ridgeBasic
语法
ridgeBasic(Y, X, [mode=0], [alpha=1.0], [intercept=true], [normalize=false],
[maxIter=1000], [tolerance=0.0001], [solver='svd'], [swColName])
详情
进行 ridge 回归估计。
最小化以下目标函数:
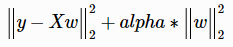
参数
Y 数值类型的向量,表示因变量。
X 数值类型的向量/元组/矩阵/表,表示自变量。
-
当 X 是向量/元组时,其长度必须等于 Y 的长度。
-
当 X 是矩阵/表时,其行数必须等于 Y 的长度。
mode 一个整数,可取以下 3 个值
-
0(默认值): 输出一个系数估计向量
-
1: 输出一个具有系数估计,标准差,t 统计量和 p 值的表
-
2: 输出一个具有 ANOVA(方差分析)、RegressionStat(回归统计)、Cofficient(系数) 和 Residual(残差) 的字典,具体含义见下表:
键 ANOVA 对应值:
|
Source of Variance |
自由度(Degree of freedom) |
平方和(Sum of Square) |
均方差(Mean of square) |
F统计量 |
Significance |
|---|---|---|---|---|---|
| Regression(回归) | 变量个数(p) | 回归平方和(SSR) | 回归均方差(MSR=SSR/R) | MSR对MSE的比值 | 显著性,即统计出的P值 |
| Residual(残差) | 残差自由度(n-p-1) | 残差平方和(SSE) | 残差均方差(MSE=MSE/E) | ||
| Total | 样本自由度, 不包括常数项(n-1) | 总离差平方和(SST) |
键 RegressionStat 对应值:
|
item |
统计值 |
|---|---|
| R2 | R决定系数,描述回归曲线对真实数据点拟合程度的统计量。范围在 [0,1]之间,越接近1 ,说明对y的解释能力越强,拟合越好。 |
| AdjustedR2 | 经自由度修正后的决定系数,通过样本数量与模型数量对 R-squared 进行修正。 |
| StdError | 回归残差标准误差,残差经自由度修正后的标准差。 |
| Observations | 观察样本个数。 |
键 Coefficient 对应值:
|
元素 |
说明 |
|---|---|
| factor | 自变量名称 |
| beta | 回归系数估计值 |
| stdError | 回归系数标准误差。 |
| tstat | T统计值,衡量系数的统计显著性。 |
键 Residual 对应每一个预测值和实际值之间的残差。
alpha 一个浮点数,表示乘以L1范数惩罚项的系数。默认值是1.0。
intercept 布尔值,表示是否包含回归中的截距。默认值为 true,此时系统自动给 X 添加一列 “1”
以生成截距。
normalize 布尔值,默认值为 false。若设为 true,则所有自变量均会进行如下标准化:减去平均值,然后除以L2范数。若
intercept 为 false,该参数会被忽略。
maxIter 一个正整数,表示最大迭代次数。默认值是1000。
tolerance 一个浮点数,表示迭代中止的边界差值。默认值是0.0001。
solve 字符串,表示回归算法模型。可取值 ‘svd’ 或 ‘cholesky’。若 ds 为多个数据源,则 solver 必须为
’cholesky’。
swColName 字符串,表示列名,必须为 X
中存在的列名。如果未指定该参数,则所有样本的权重都默认为1;如果指定该参数,则将指定的列作为自变量的权重。
返回值
返回一个向量、表或字典,取决于参数 mode。
例子
例1:设置 mode=0,输出一个系数估计向量。
Y = [225.72, -76.20, 63.09, 139.45, -65.55]
X0 = [2.24, -0.85, 0.40, 1.45, -0.98]
X1 = [0.98, 0.31, 1.76, 0.14, 1.87]
coefficients = ridgeBasic(Y, [X0, X1], mode=0, alpha=0.5, intercept=true)
coefficients
// 输出:[7.940468476954727, 88.20426761349431, 9.380634942436586]例2:设置 mode=1,输出包含 ANOVA(方差分析)、RegressionStat(回归统计)、Cofficient(系数)和 Residual(残差)的字典。
Y = [1.5, 2.3, 4.7, 3.2, 5.1]
X = matrix([1.1, 2.2, 3.1, 2.8, 4.0], [0.5, 0.8, 1.2, 1.0, 1.5])
result = ridgeBasic(Y, X, mode=2, alpha=0.8, solver='svd')查看方差分析。
result[`ANOVA]| Breakdown | DF | SS | MS | F | Significance |
|---|---|---|---|---|---|
| Regression | 2 | 6.439542296188023 | 3.2197711480940114 | 6.3847474657971865 | 0.1354142446483848 |
| Residual | 2 | 1.0085821452899069 | 0.5042910726449534 | ||
| Total | 4 | 9.432000000000016 |
查看回归统计。
result[`RegressionStat]| item | statistics |
|---|---|
| R2 | 0.6827334919622574 |
| AdjustedR2 | 0.3654669839245148 |
| StdError | 0.7101345454524469 |
| Observations | 5 |
查看回归系数。
result[`Coefficient]| factor | beta | stdError | tstat | pvalue |
|---|---|---|---|---|
| intercept | 0.22075506589464267 | 1.084447930898624 | 0.20356446778566378 | 0.8575265882132079 |
| beta0 | 1.0193512860448009 | 2.662502504483437 | 0.3828545829828503 | 0.7386872800445148 |
| beta1 | 0.44815753894708277 | 7.540425982186433 | 0.05943398158218302 | 0.9580108927931805 |
查看残差。
result[`Residual]
// 输出:[-0.06612025001746513, -0.5218539263508712, 0.7814669006299755, -0.32309620576716735, 0.12960348150553003]