高频行情低频化因子库使用教程
目前,在量化投资研究领域,因子挖掘与应用正不断向更高频、更精细的数据层级深入。经典的因子库,如 国泰君安 191 Alpha 因子库 和 WorldQuant 101 Alpha 因子指标库,为基于日频、分钟频等中低频行情数据的策略开发提供了坚实基础。然而,这类低频因子在捕捉瞬息万变的市场微观结构信息、挖掘更具时效性和差异化的交易信号方面存在天然的局限。
随着行情数据粒度的不断细化,海量的分钟级、快照级乃至逐笔数据蕴含着更丰富的价格形成、订单流动与市场参与者行为信息。直接从这些高频数据中高效、稳定地提炼出可靠的 Alpha 信号,并将其“降维”应用于频率相对较低(如日度、小时级)的策略研究与组合管理中,已成为业界的重要发展方向。高频数据低频化过程的核心业务价值在于:使得策略开发者能够将微观、瞬时的市场状态(如资金流向、订单簿失衡、交易冲击等)转化为具有稳定预测能力的低频特征或因子,从而在更低频的交易周期中,提前洞察机会、优化风险控制,构建具备信息优势的差异化策略。
为满足这一需求,本教程提供了一套基于 DolphinDB 高性能时序数据库和分析引擎原生构建的、面向分钟级乃至 tick 级金融数据的专业因子计算解决方案。其核心在于,将公开研报和文献中经过验证的 100 余个中低频日频因子,结合 DolphinDB 的卓越数据处理能力,高效地适配并应用于分钟 K 线、Level-2 行情快照、逐笔委托和逐笔成交等高频数据源上。
注意:本教程包含的所有代码兼容 DolphinDB 2.00.12,3.00.2 及以上版本。
1. 高频行情低频化因子库简介
高频行情数据通常指时间粒度介于日频与超高频(如毫秒级)之间的数据,主要包括分钟 K 线、快照行情、逐笔成交与委托等类型。这些数据实时记录了市场最细微的价格变动、订单流动与交易行为,是捕捉市场微观结构、挖掘独特 Alpha 信号的信息宝库。
本教程基于经典的公开研报和学术文献等资料系统整理并实现了一个高频行情低频化因子库,涵盖了量价趋势类、波动率类、流动性类等多种类别的因子。该因子库的核心价值在于,提供了一套经过完整工程实现、性能优化与初步验证的标准化因子计算流程,用户可直接基于自己的高频数据运行,快速获得可用于低频策略研究的、具有更高信息密度的因子序列。
本因子库完全基于 DolphinDB 高性能时序数据库原生构建。DolphinDB 集成了分布式计算、实时流处理与高效存储引擎,其内置的多范式编程语言与丰富的金融分析函数,能够轻松应对高频数据处理的巨大吞吐与计算复杂度挑战,实现从 TB 级高频数据到日频因子的秒级生成。本文提供了完整的计算脚本与性能基准,帮助用户快速验证、迭代与部署自己的低频化因子。具体的因子列表与计算脚本请见第 7 章。
2. 数据集与入参规范
本文的中高频因子库基于国内 A 股四类行情数据集:分钟 K 线数据、快照数据、逐笔成交和逐笔委托数据。本节提供了相关数据集的部分字段和存储方案,具体的建库建表方案及相关代码请参考 存储金融数据的分区方案最佳实践。
| 数据集 | 简称 | 代码样例中的分区数据库路径 | 代码样例中的表名 | 分区方案 |
|---|---|---|---|---|
| 分钟 K 线 | stockMinKSH | dfs://stockMinKSH | stockMinKSH | 按天分区 |
| 快照行情 | snapshot | dfs://Level2 | snapshot | 按天分区 + 按股票代码 HASH50 分区 |
| 逐笔委托 | entrust | dfs://Level2 | entrust | 按天分区 + 按股票代码 HASH50 分区 |
| 逐笔成交 | trade | dfs://Level2 | trade | 按天分区 + 按股票代码 HASH50 分区 |
2.1 分钟 K 线数据
分钟 K 线数据是指每分钟的市场行情走势,由逐笔成交数据聚合产生,通常用于短线交易者分析日内价格波动。本教程中分钟 K 线数据采用“时间维度按天”的分区规则,使用 OLAP存储引擎,每个分区内都包含了当天所有股票的分钟 K 线数据。其中,涉及到因子计算的重要字段有:
| 字段名称 | 数据类型 | 数据说明 |
|---|---|---|
| SecurityID | SYMBOL | 股票代码 |
| DateTime | TIMESTAMP | 交易时间 |
| OpenPrice | DOUBLE | 开盘价 |
| HighPrice | DOUBLE | 最高价 |
| LowPrice | DOUBLE | 最低价 |
| LastPrice | DOUBLE | 收盘价 |
| Volume | LONG | 成交量 |
| Amount | DOUBLE | 成交额 |
2.2 Level-2 行情数据
股票 Level-2 行情数据包含 Level-2 快照数据、逐笔委托数据、逐笔成交数据。在分布式数据库中,对跨分区数据表进行连接操作往往十分耗时,因为涉及到的分区可能位于不同的节点上,需要在不同节点之间复制数据。为解决这个问题,DolphinDB 推出了共存储位置(co-location)的分区机制,使同一分布式数据库中、分区方案一致的多个表,其相同分区的数据能够存放在同一节点上,从而显著提升表连接效率。因此在本教程中,把 Level-2 快照数据、逐笔委托数据、逐笔成交数据这些分区方案一致的数据表存入同一个数据库中。本教程中 Level-2 行情数据采用“时间维度按天 + 股票维度 HASH50”的分区规则,使用 TSDB 存储引擎。
2.2.1 Level-2 行情快照数据
Level-2 行情快照数据是对逐笔行情数据的某一个时刻的切片数据,通常以 3 秒为周期更新,包含多档买卖盘等关键信息。其中,涉及到因子计算的重要字段有:
| 字段名称 | 数据类型 | 数据说明 |
|---|---|---|
| SecurityID | SYMBOL | 证券代码 |
| TradeTime | TIMESTAMP | 数据生成时间 |
| PreCloPrice | DOUBLE | 昨日收盘价 |
| NumTrades | INT | 成交笔数 |
| TotalVolumeTrade | INT | 成交总量 |
| TotalValueTrade | DOUBLE | 成交总金额 |
| LastPrice | DOUBLE | 最近价 |
| OpenPrice | DOUBLE | 开盘价 |
| HighPrice | DOUBLE | 最高价 |
| LowPrice | DOUBLE | 最低价 |
| ClosePrice | DOUBLE | 今日收盘价 |
| TotalBidQty | INT | 委托买入总量 |
| TotalOfferQty | INT | 委托卖出总量 |
| OfferPrice | DOUBLE VECTOR | 卖价 10 档 |
| BidPrice | DOUBLE VECTOR | 买价 10 档 |
| OfferOrderQty | INT VECTOR | 卖量 10 档 |
| BidOrderQty | INT VECTOR | 买量 10 档 |
| Market | SYMBOL | 交易所名称 |
2.2.2 Level-2 逐笔委托数据
Level-2 逐笔委托数据记录了市场中每一笔委托行为,包括新委托的提交、现有委托的撤销以及委托价格或数量的修改。其中,涉及到因子计算的重要字段有:
| 字段名称 | 数据类型 | 数据说明 |
|---|---|---|
| SecurityID | SYMBOL | 证券代码 |
| TradeTime | TIMESTAMP | 报价时间 |
| Price | DOUBLE | 委托价格 |
| OrderQty | INT | 委托数量 |
| Side | SYMBOL | 买卖方向 |
| Market | SYMBOL | 交易所名称 |
2.2.3 Level-2 逐笔成交数据
Level-2 逐笔成交数据是交易所公布的买卖双方具体成交的每一笔数据,每 3 秒发布一次,每次包含这 3 秒内的所有成交记录。每一笔成交撮合都由买方和卖方的一笔具体委托组成,是交易过程的真实成交情况。其中,涉及到因子计算的重要字段有:
| 字段名称 | 数据类型 | 数据说明 |
|---|---|---|
| SecurityID | SYMBOL | 证券代码 |
| TradeTime | TIMESTAMP | 成交时间 |
| BidApplSeqNum | LONG | 买方委托索引 |
| OfferApplSeqNum | LONG | 卖方委托索引 |
| TradPrice | DOUBLE | 委托价格 |
| TradeQty | DOUBLE | 委托数量 |
| TradeMoney | DOUBLE | 成交金额 |
| Market | SYMBOL | 交易所名称 |
3. 因子存储
因子挖掘是量化交易的必备环节之一,随着量化交易和 AI 模型训练规模的发展,量化投资团队在投研环节势必需要处理大量因子数据。因子的存储也是一个关键问题,目前 DolphinDB 支持宽表和窄表两种存储模式。相较于宽表,窄表存储支持更加高效地添加、更新、删除因子等操作,因而推荐使用窄表存储因子库。
3.1 建立因子库
针对日频因子库,经过各项测试后(测试见 中高频多因子库存储最佳实践),推荐采用“时间维度按年 + 因子名”的组合分区方式存储,使用 TSDB 存储引擎,以“股票代码 + 交易时间”作为排序列。更多金融数据与因子库分区方案见 存储金融数据的分区方案最佳实践。具体脚本如下:
// 创建日频因子库
create database "dfs://factor_day"
partitioned by RANGE(date(datetimeAdd(1980.01M,0..80*12,'M'))), VALUE(`f1`f2),
engine='TSDB',
atomic='CHUNK'
// 创建分区表
create table "dfs://factor_day"."factor_day"(
SecurityID SYMBOL,
TradeDate DATE[comment="时间列", compress="delta"],
Value DOUBLE,
FactorName SYMBOL,
UpdateTime TIMESTAMP,
)
partitioned by TradeDate, FactorName
sortColumns=[`SecurityID, `TradeDate],
keepDuplicates=ALL, //保留所有写入的因子值
sortKeyMappingFunction=[hashBucket{, 500}]3.2 处理计算结果并入库
因子计算结果是一个五列的表格,分别是 SecurityID(证券代码)、TradeDate(数据日期)、Value(因子值)、FactorName(因子名)以及 UpdateTime(更新日期)。本文推荐采用窄表方式存储因子,因此可将计算结果直接入库,其代码如下:
//读取数据库并将结果入库
loadTable("dfs://factor_day","factor_day").append!(select * from res)4. 因子计算流程
本章将完整地介绍如何调取数据进行因子计算并将计算结果存储入库。考虑到部分因子具有特殊的数据需求或计算方式,其实现方式与其他因子有所区别,相关内容将在 4.2 小节单独介绍。
4.1 因子通用计算流程
本因子库内所有 dos 脚本均由三部分构成:因子计算函数,后台任务提交函数以及因子计算样例。用户正确配置参数并直接运行脚本即可实现因子的计算与入库。接下来将分别介绍每一部分的具体内容及使用方法。
4.1.1 因子计算函数
本小节定义了因子计算函数。这些函数均以因子计算依赖的基础数据表作为唯一入参,并返回一个标准格式的表。输出表包含五列:SecurityID(证券代码)、TradeDate(数据日期)、Value(因子值)、FactorName(因子名)以及 UpdateTime(更新日期),其中每一行对应单只股票在单个交易日的因子值。
以成交量占比偏度因子为例,其因子计算函数如下:
def skewVolProp(snapshot){
snap =
select
TradeDate, TradeTime, SecurityID,
deltas(TotalVolumeTrade)\last(TotalVolumeTrade) as volProp
from snapshot
context by TradeDate, SecurityID csort TradeTime
having TradeTime >= 09:30:00.000
//日内tick成交量除以总成交量序列的偏度
res =
select
SecurityID,
TradeDate,
skew(volProp) as Value,
"skewVolProp" as FactorName,
now() as UpdateTime
from snap
group by TradeDate, SecurityID
return res
}4.1.2 后台任务提交函数
因子计算通常涉及较长时间跨度的数据,处理耗时较长,因此更适合将任务提交至服务器后台执行。本节介绍的函数旨在将因子的计算流程与存储逻辑封装为可执行单元,并以异步任务的形式提交至后台运行。
后台任务提交函数的入参为一个包含因子计算基本信息的字典,其具体内容如下:
| 配置项 | 配置内容 | 类型 |
|---|---|---|
| func | 计算因子的函数名 | FUNCTION |
| funcsec | 调整因子的函数名 | FUNCTION |
| factorName | 因子名 | SYMBOL |
| dataDB | 计算所需数据的数据库 | STRING |
| dataTB | 计算所需数据的数据表 | STRING |
| factorDB | 存储因子的数据库 | STRING |
| factorTB | 存储因子的数据表 | STRING |
| startDay | 计算因子的起始日期 | DATE |
| endDay | 计算因子的结束日期 | DATE |
该函数首先根据 dataDB 库中 dataTB 表的分区信息,生成一个由多条 SQL 元代码构成的向量 ds。每条 SQL 会查询 startDay 到 endDay 期间每日给定时段的数据,这些数据将作为并行计算任务的数据源。随后,函数通过 mr 函数并行调用因子计算函数 func 进行处理,并使用 unionAll 函数合并所有分区的计算结果。最终,函数将结果按 factorDB 库中 factorTB 表所需的格式进行整理后将数据存入目标因子库。
以成交量占比偏度因子为例,其后台任务提交函数如下:
def factorJob(conf){
dataTB = loadTable(conf[`dataDB], conf[`dataTB])
days = conf[`startDay]..conf[`endDay]
startTime = 09:27:00.000
endTime = 14:57:00.000
//提取计算所需数据,sqlDS生成元代码
ds = sqlDS(<select SecurityID, TradeDate, TradeTime, TotalVolumeTrade
from dataTB
where TradeDate in days and (TradeTime between startTime and endTime) and (SecurityID like "00%" or SecurityID like "30%" or SecurityID like "6%")>)
//计算因子,mr函数将因子在不同节点并行计算,unionAll函数将不同节点的计算结果汇总
res = mr(ds, conf[`func]).unionAll()
//写入因子库,存储到磁盘做持久化
loadTable(conf[`factorDB], conf[`factorTB]).append!(select * from res)
}4.1.3 计算样例
本小节将提供参数配置和提交后台任务的一个样例。首先,基于 4.1.2 小节中的入参字典配置参数 conf,其次使用 submitJob 函数将任务函数提交到服务器后台执行。
以成交量占比偏度因子为例,其计算样例如下:
// 配置计算因子的参数
// conf = {
// func : 计算因子的函数名
// funcsec : 计算再调整因子的函数名
// factorName : 因子名
// dataDB : 计算所需数据的数据库
// dataTB : 计算所需数据的数据表
// factorDB : 存储因子的数据库
// factorTB : 存储因子的数据表
// startDay : 计算因子的起始日期
// endDay : 计算因子的结束日期
// }
conf = {
func : skewVolProp,
funcsec : NULL,
factorName : `skewVolProp,
dataDB : "dfs://Level2",
dataTB : "snapshot",
factorDB : "dfs://factor_day",
factorTB : `factor_day,
startDay : 2023.02.01,
endDay : 2023.02.28
}
//提交计算和存储因子的任务到服务器并返回任务 id
id = submitJob("factor_job", conf[`factorName], factorjob, conf)在该例子中,计算的因子名为 skewVolProp ,计算因子的函数为 skewVolProp。计算所需的 2023 年
2 月的通联 Level-2 行情快照数据存储于数据库 dfs://Level2 下的 snapshot 表中。计算的时间区间为 2023 年 2 月
1 日到 2023 年 2 月 28 日。计算得到的因子将存储在数据库 dfs://factor_day 下的表 factor_day
中。因为该因子不涉及调整因子的函数,因此配置项 funcsec 为 NULL 。
配置完成后,submitJob 函数将任务提交到后台服务器,提交的任务名为 factor_job,任务描述为因子名
skewVolProp,执行的函数为 4.1.2 小节中的 factorJob 函数,入参为
conf。执行 submitJob 函数后等待后台完成计算任务即可完成因子计算到入库的全流程。
4.2 特殊因子实现方式
部分因子实现方式与其他因子有所区别,因此这一小节将单独介绍这些因子的计算和使用方式。
4.2.1 需要额外数据集的因子
部分因子的计算涉及基础数据表与其它数据库表(如历史数据或市场指数数据)。在分布式计算框架下,由于数据按时间和标的分区并行处理,某些因子(如依赖历史窗口的因子或其他市场指数)无法仅从当前传入的数据块中获取全部所需信息。
为解决此问题,本因子库允许在计算函数内部直接读取数据库。对于需要额外数据的因子,其计算函数内已预设了读取逻辑。因此,用户在使用这些因子前,需根据实际环境,在相应的因子计算函数中修改所依赖数据的数据库路径参数。
本因子库中包含的该类因子如下:
| 因子名 | 涉及的额外数据集 |
|---|---|
| 日度惊恐因子 | Level-2 行情快照数据 |
| 日内主买占比因子 | Level-2 行情快照数据 |
| 开盘后净主买占比因子 | Level-2 行情快照数据 |
| 日内主买强度因子 | Level-2 行情快照数据 |
| 开盘后净主买强度因子 | Level-2 行情快照数据 |
| 开盘后买入意愿强度 | Level-2 逐笔成交数据 |
| 开盘后买入意愿占比 | Level-2 逐笔成交数据 |
以开盘后买入意愿强度因子为例,其计算函数如下:
def netBuyIntenOpen(entrustTB){
//净委买增额:1分钟委托买单增加量减去委托卖单变化量(逐笔委托)
tmp1 =
select
sum(OrderMoney*iif(Side==`B or Side==`1, 1.0, 0.0)) - sum(OrderMoney*iif(Side==`S or Side==`2, 1.0, 0.0)) as enrustNetBuy
from entrustTB
group by TradeDate, SecurityID, interval(X=TradeTime, duration=60s, label='left', fill=0) as TradeTime
//净主买成交额:1分钟主动买入成交额减去主动卖出成交额(逐笔成交)
//根据逐笔委托当天的标的去逐笔成交表查询计算依赖的行情数据
calDate = first(entrustTB[`TradeDate])
codes = exec distinct SecurityID from entrustTB
tradeTB =
select SecurityID, TradeDate, TradeTime, TradePrice*TradeQty as TradeMoney, iif(BidApplSeqNum > OfferApplSeqNum, `B, `S) as BSFlag
from loadTable("dfs://Level2", "trade")
where TradeDate=calDate, SecurityID in codes and TradeTime between 09:30:00.000 and 10:00:00.000, TradePrice>0
tmp2 =
select
sum(TradeMoney*iif(BSFlag==`B, 1.0, 0.0))- sum(TradeMoney*iif(BSFlag==`S, 1.0, 0.0)) as tradeNetBuy,
sum(TradeMoney) as tradeTotal
from tradeTB
group by TradeDate, SecurityID, interval(X=TradeTime, duration=60s, label='left', fill=0) as TradeTime
//开盘后买入意愿强度:开盘后时间段(09:30-10:00)内1分钟买入意愿序列的均值除以标准差
tmp3 =
select
mean(tradeNetBuy+enrustNetBuy)\stdp(tradeNetBuy+enrustNetBuy) as Value
from lj(tmp1, tmp2, `TradeDate`SecurityID`TradeTime)
where tradeNetBuy!=NULL
group by TradeDate, SecurityID
//因子
res =
select
SecurityID,
TradeDate,
Value,
"netBuyIntenOpen" as FactorName,
now() as UpdateTime
from tmp3
return res
}注:该类因子的后台任务提交函数与计算样例部分与通用模板一致,遵循通用模板的流程即可计算因子并入库。
4.2.2 基于日频因子的再调整因子
部分因子需在已生成的日频因子上进行二次修正,无法一次性计算得出。对此,本小节采用两步计算策略:先运行日频因子计算函数,再将其结果传入修正函数进行二次处理。因此,这类因子的实现方式与其他因子不同。
在函数定义上,该类因子将有两个关联函数:一个用于计算基础日频因子,另一个用于后续修正。需要特别说明的是,由于日频因子已经过降频处理,修正函数将采用更高效的本地计算,而非分布式计算。
本因子库中包含的该类因子主要如下:
| 因子名 | 测试数据集 |
|---|---|
| 修正日模糊价差因子 | 分钟 K 线数据 |
以修正日模糊价差因子为例,其计算因子的函数如下:
//自定义因子计算函数
def fuzzinessDiff(minKTB){
/**@test 少量数据临时调试
minKTB =
select SecurityID, date(DateTime) as TradeDate, time(DateTime) as TradeTime, LastPx, Volume, Amount
from loadTable("dfs://stockMinKSH", "stockMinKSH")
where date(DateTime) between 2021.01.04 and 2021.01.31, SecurityID in `603189`000001 and LastPx>0
*/
//计算模糊性
fuzziness =
select
SecurityID,
TradeDate,
TradeTime,
Volume,
Amount,
mstd(mstd(percentChange(LastPx), 5, 5), 5, 5) as fuzziness
from minKTB
context by SecurityID, TradeDate
//计算每日起雾时刻模糊性阈值及成交量均值、成交金额均值
threshold =
select
SecurityID,
TradeDate,
avg(Volume) as avgVolume,
avg(Amount) as avgAmount,
avg(fuzziness) as thresholdFuzzy
from fuzziness
group by SecurityID, TradeDate
//日模糊价差=日模糊金额比-日模糊数量比
res =
select
SecurityID,
TradeDate,
avg(Volume)\first(avgVolume)-avg(Amount)\first(avgAmount) as Value,
"fuzzinessDiff" as factorName,
now() as updateTime
from lj(fuzziness, threshold, `SecurityID`TradeDate)
where fuzziness > thresholdFuzzy
group by SecurityID, TradeDate
return res
}
def adjFuzzinessDiff(diffTB){
/**@test
diffTB = select * from res
*/
//修正日模糊价差:将横截面上值为负的日模糊价差求和,记为 s1;将负的日模糊价差除以其过去 10 日日模糊价差的标准差,值为正的日模糊价差不变
s1 =
select
TradeDate,
sum(Value) as s1
from diffTB
where Value<0
group by TradeDate
adjDiff =
select
SecurityID,
TradeDate,
iif(Value<0, Value\mstd(Value, 10), Value) as adjFuzzDiff
from diffTB
context by SecurityID
//调整数量级:将横截面上值为负的修正日模糊价差求和,记为 s2;将值为负的修正日模糊价差除以 s2 后乘以 s1
s2 =
select
TradeDate,
sum(adjFuzzDiff) as s2
from adjDiff
where adjFuzzDiff<0
group by TradeDate
s =
select
TradeDate,
s1\s2 as s
from ej(s1, s2, `TradeDate)
res =
select
SecurityID,
TradeDate,
iif(adjFuzzDiff<0, adjFuzzDiff*s, adjFuzzDiff) as Value,
"adjFuzzinessDiff" as FactorName,
now() as UpdateTime
from lj(adjDiff, s, `TradeDate)
context by SecurityID, TradeDate
return res
}由于该类因子在计算时需要调用两个函数,其任务函数也有所区别。修正模糊价差因子的任务函数如下:
//后台任务计算函数模版
def factorjob(conf){
dataTB = loadTable(conf[`dataDB], conf[`dataTB])
days = conf[`startDay]..conf[`endDay]
startTime = 09:30:00.000
endTime = 14:57:00.000
//提取计算所需数据,sqlDS生成元代码
ds = sqlDS(<select SecurityID, date(DateTime) as TradeDate, time(DateTime) as TradeTime, LastPx, Volume, Amount
from dataTB
where date(DateTime) in days and (time(DateTime) between startTime and endTime) and (SecurityID like "00%" or SecurityID like "30%" or SecurityID like "6%") and LastPx>0>)
//计算因子,mr函数将因子在不同节点并行计算,unionAll函数将不同节点的计算结果汇总
diffTB = mr(ds, conf[`func]).unionAll()
res = conf[`funcsec](diffTB)
//写入因子库,存储到磁盘做持久化
loadTable(conf[`factorDB], conf[`factorTB]).append!(select * from res)
}与通用流程的区别在于,此类计算需配置 funcsec 参数以实现两步计算:先分布式执行 func
函数生成日频因子,再通过 funcsec 函数进行修正。配置时,需将修正函数赋值给 conf 的
funcsec。其计算样例如下:
//计算模版配置参数
conf = {
func : fuzzinessDiff,
funcsec : adjFuzzinessDiff,
factorName : "fuzzinessDiff",
dataDB : "dfs://stockMinKSH",
dataTB : "stockMinKSH",
factorDB : "dfs://factor_day",
factorTB : "factor_day",
startDay : 2021.01.01,
endDay : 2021.01.31
}
//提交计算和存储因子的任务到服务器
id = submitJob("factorjob", conf[`factorname], factorjob, conf)4.3 批量计算因子
本因子库支持批量计算因子。所有脚本开箱即用,只需将参数配置完成的脚本上传至 DolphinDB 服务器,并通过循环执行即可实现批量计算与入库。
以基于逐笔成交的日频因子为例,将所需脚本上传至
/ssd/ssd0/singleDDB/server/高频因子库/基于逐笔成交的日频因子
文件目录下,执行以下代码即可批量计算该类因子:
//登录服务器.
login("xxxxxx","xxxxxxxx");
go
//脚本所在目录
scriptdir = "/ssd/ssd0/singleDDB/server/高频因子库/基于逐笔成交的日频因子"
//获取脚本所在目录下的脚本名称
scriptFiles = files(scriptdir)
//批量运行脚本
for(script in scriptFiles){
run(scriptdir+"/"+script[`filename], newSession = true, clean = true)
print("已运行脚本:"+script[`filename])
}用户实际使用时可自行设置脚本所在目录和是否打印运行信息。
4.4 因子更新
本因子库的因子在入库时默认追加至尾部,如用户需要更新已计算的因子值,可以通过在建立存储因子的数据库的时候调整配置项实现。以下示例演示了具体操作。请注意,为保证代码复用性,在建库之前将删除已存在的数据,实际操作时请谨慎执行该行代码。
//删除已有数据库
if(existsDatabase("dfs://factor_day")) dropDatabase("dfs://factor_day")
// 创建日频因子库
create database "dfs://factor_day"
partitioned by RANGE(date(datetimeAdd(1980.01M,0..80*12,'M'))), VALUE(`f1`f2),
engine='TSDB',
atomic='CHUNK'
// 创建分区表
create table "dfs://factor_day"."factor_day"(
SecurityID SYMBOL,
TradeDate DATE[comment="时间列", compress="delta"],
Value DOUBLE,
FactorName SYMBOL,
UpdateTime TIMESTAMP,
)
partitioned by TradeDate, FactorName
sortColumns=[`SecurityID, `TradeDate],
keepDuplicates=LAST, //支持重复写入,保留最新写入的因子值
sortKeyMappingFunction=[hashBucket{, 500}]创建数据表时 keepDuplicates 参数可以设置不同的去重机制,设置为 LAST 时,将依据 sortColumns 中的数据列保留最新入库的数据。此外,因子表中的 UpdateTime 列可用于记录当前数据入库时间。
5. 计算性能
5.1 测试环境与数据集
5.1.1 测试环境
测试使用的 DolphinDB server 版本为 2.00.16 ,硬件配置如下:
| OS(操作系统) | CentOS Linux 7 (Core) |
| 内核 | 3.10.0-1160.el7.x86_64 |
| CPU | Intel(R) Xeon(R) Gold 5220R CPU @ 2.20GHz 16 逻辑 CPU 核心 |
| 内存 | 8*32GB RDUNN, 3200MT/s 总共 256 GB |
| 磁盘 |
固态硬盘(SSD) 6*3.84TB 固态硬盘 SATA 读取密集型 6Gbps 512 2.5 英寸 Flex Bay AG 硬盘, 1DWPD 单盘测试随机写
单盘测试混合随机读写
|
| 网络 | 9.41Gbps(万兆以太网) |
5.1.2 测试数据集
计算各因子依赖的的数据集及其数据量展示如下:
| 因子类型 | 测试数据集 | 数据量(条) |
|---|---|---|
| 基于行情快照的因子 | 2023 年 2 月沪深 Level-2 快照数据 | 475,627,079 |
| 基于逐笔委托数据的因子 | 2023 年 2 月沪深逐笔委托数据 | 2,712,071,019 |
| 基于逐笔成交数据的因子 | 2023 年 2 月沪深逐笔成交数据 | 2,067,012,875 |
| 基于分钟 K 线的因子 | 2021 年 1 月 K 线数据 | 38,594,699 |
5.2 测试结果
所有因子测试数据及耗时情况如下:
| 因子名 | 测试数据 | 计算耗时(s) |
|---|---|---|
| 最短路径非流动性因子 | 2021 年 1 月 K 线数据 | 0.29 |
| 一致买入交易因子 | 2021 年 1 月 K 线数据 | 0.25 |
| 绝对收益与调整后滞后成交量相关性因子 | 2021 年 1 月 K 线数据 | 78.75 |
| 成交量“潮汐”的价格变动速率因子 | 2021 年 1 月 K 线数据 | 0.48 |
| 跌幅时间重心偏离因子 | 2021 年 1 月 K 线数据 | 77.94 |
| 一致交易因子 | 2021 年 1 月 K 线数据 | 0.33 |
| 成交额占比熵因子 | 2021 年 1 月 K 线数据 | 0.23 |
| 日内持续异常交易量因子 | 2021 年 1 月 K 线数据 | 0.56 |
| 日耀眼波动率因子 | 2021 年 1 月 K 线数据 | 0.35 |
| 日午蔽古木因子 | 2021 年 1 月 K 线数据 | 1.52 |
| 单一成交额占比熵因子 | 2021 年 1 月 K 线数据 | 0.27 |
| 日度灾后重建因子 | 2021 年 1 月 K 线数据 | 1.01 |
| 滞后绝对收益与调整后成交量相关性因子 | 2021 年 1 月 K 线数据 | 78.53 |
| 日耀眼收益率因子 | 2021 年 1 月 K 线数据 | 0.27 |
| 日度勇攀高峰因子 | 2021 年 1 月 K 线数据 | 1.04 |
| 绝对收益与成交量相关性因子 | 2021 年 1 月 K 线数据 | 0.41 |
| 绝对收益与滞后成交量相关性因子 | 2021 年 1 月 K 线数据 | 0.18 |
| 滞后绝对收益与成交量相关性因子 | 2021 年 1 月 K 线数据 | 0.19 |
| 日朝没晨雾因子 | 2021 年 1 月 K 线数据 | 0.92 |
| T分布主动占比因子 | 2021 年 1 月 K 线数据 | 0.61 |
| 置信正态分布主动占比因子 | 2021 年 1 月 K 线数据 | 0.30 |
| 朴素主动占比因子 | 2021 年 1 月 K 线数据 | 0.63 |
| T分布主动占比因子 | 2021 年 1 月 K 线数据 | 0.21 |
| 成交量波峰计数因子 | 2021 年 1 月 K 线数据 | 0.22 |
| 日模糊金额比因子 | 2021 年 1 月 K 线数据 | 0.36 |
| 日模糊数量比因子 | 2021 年 1 月 K 线数据 | 0.38 |
| P 型成交量分布因子 | 2021 年 1 月 K 线数据 | 0.42 |
| B 型成交量分布因子 | 2021 年 1 月 K 线数据 | 0.44 |
| 修正日模糊价差因子 | 2021 年 1 月 K 线数据 |
日模糊价差因子:0.38; 修正版:0.41 |
| 成交量支撑区域下限与收盘价差异因子 | 2021 年 1 月 K 线数据 | 0.43 |
| 模糊关联度因子 | 2021 年 1 月 K 线数据 | 0.32 |
| 时间加权平均的股票相对价格位置因子 | 2023 年 2 月通联 Level-2 快照数据 | 7.96 |
| 高频上行波动占比因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.94 |
| 高频下行波动占比因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.94 |
| 已实现波动率因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.78 |
| 上行已实现波动率因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.20 |
| 下行已实现波动率因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.05 |
| 高频已实现偏度因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.27 |
| 高频已实现峰度因子 | 2023 年 2 月通联 Level-2 快照数据 | 4.93 |
| 上下行波动率不对称性因子 | 2023 年 2 月通联 Level-2 快照数据 | 6.98 |
| 中间价变化率偏度因子 | 2023 年 2 月通联 Level-2 快照数据 | 30.27 |
| 中间价变化率最大值因子 | 2023 年 2 月通联 Level-2 快照数据 | 31.44 |
| 大成交量已实现偏度因子 | 2023 年 2 月通联 Level-2 快照数据 | 7.41 |
| 大成交量价量相关性因子 | 2023 年 2 月通联 Level-2 快照数据 | 7.35 |
| 已实现双幂次变差因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.85 |
| 已实现三幂次变差因子 | 2023 年 2 月通联 Level-2 快照数据 | 6.16 |
| 日度惊恐因子 | 2023 年 2 月通联 Level-2 快照数据 | 4.01 |
| 成交量分桶熵因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.68 |
| 已实现跳跃波动率因子 | 2023 年 2 月通联 Level-2 快照数据 | 6.72 |
| 交易量变异系数因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.76 |
| 上行已实现跳跃波动率因子 | 2023 年 2 月通联 Level-2 快照数据 | 6.34 |
| 下行已实现跳跃波动率因子 | 2023 年 2 月通联 Level-2 快照数据 | 6.69 |
| 聪明钱因子 | 2023 年 2 月通联 Level-2 快照数据 | 7.51 |
| 成交量占比偏度因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.24 |
| 成交量占比峰度因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.26 |
| 日度主力交易情绪因子 | 2023 年 2 月通联 Level-2 快照数据 | 8.34 |
| 趋势占比因子 | 2023 年 2 月通联 Level-2 快照数据 | 6.69 |
| 上下行跳跃波动的不对称性因子 | 2023 年 2 月通联 Level-2 快照数据 | 6.80 |
| 最大涨幅因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.44 |
| 大单资金净流入率因子 | 2023 年 2 月通联 Level-2 快照数据 | 8.35 |
| 大单驱动涨幅因子 | 2023 年 2 月通联 Level-2 快照数据 | 7.84 |
| 每单成交量筛选的局部反转因子 | 2023 年 2 月通联 Level-2 快照数据 | 8.63 |
| 平均单笔流出金额占比因子 | 2023 年 2 月通联 Level-2 快照数据 | 8.03 |
| 大的上行跳跃波动率因子 | 2023 年 2 月通联 Level-2 快照数据 | 8.03 |
| 大的下行跳跃波动率因子 | 2023 年 2 月通联 Level-2 快照数据 | 8.22 |
| 小的上行跳跃波动率因子 | 2023 年 2 月通联 Level-2 快照数据 | 8.13 |
| 小的下行跳跃波动率因子 | 2023 年 2 月通联 Level-2 快照数据 | 7.83 |
| 日内条件在险价值因子 | 2023 年 2 月通联 Level-2 快照数据 | 8.73 |
| 隔夜收益率因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.18 |
| 日内最大回撤因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.09 |
| 日内成交量占比标准差因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.26 |
| 每笔成交量收益率相关性因子 | 2023 年 2 月通联 Level-2 快照数据 | 8.33 |
| 日内收益率因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.04 |
| 分钟成交额方差因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.39 |
| 尾盘半小时收益率因子 | 2023 年 2 月通联 Level-2 快照数据 | 2.03 |
| 日度盘口价差因子 | 2023 年 2 月通联 Level-2 快照数据 | 30.64 |
| 尾盘半小时成交额占比因子 | 2023 年 2 月通联 Level-2 快照数据 | 2.04 |
| 大的上下行跳跃波动不对称性因子 | 2023 年 2 月通联 Level-2 快照数据 | 9.44 |
| 小的上下行跳跃波动不对称性因子 | 2023 年 2 月通联 Level-2 快照数据 | 10.33 |
| 日度价格弹性因子 | 2023 年 2 月通联 Level-2 快照数据 | 7.31 |
| 日度盘口平均深度因子 | 2023 年 2 月通联 Level-2 快照数据 | 29.77 |
| 加权收盘价比因子 | 2023 年 2 月通联 Level-2 快照数据 | 6.32 |
| 结构化反转因子 | 2023 年 2 月通联 Level-2 快照数据 | 6.98 |
| 日度有效深度因子 | 2023 年 2 月通联 Level-2 快照数据 | 28.92 |
| 分钟成交额自相关性因子 | 2023 年 2 月通联 Level-2 快照数据 | 5.60 |
| 尾盘半小时成交量占比因子 | 2023 年 2 月通联 Level-2 快照数据 | 2.01 |
| 加权偏度因子 | 2023 年 2 月通联 Level-2 快照数据 | 8.94 |
| 交易量同步的知情交易概率因子 | 2023 年 2 月通联 Level-2 快照数据 | 8.52 |
| 开盘后买入意愿强度因子 | 2023 年 2 月通联 Level-2 逐笔委托 | 11.80 |
| 开盘后净委买增额占比因子 | 2023 年 2 月通联 Level-2 逐笔委托 | 3.56 |
| 开盘后买入意愿占比因子 | 2023 年 2 月通联 Level-2 逐笔委托 | 5.69 |
| 卖出反弹偏离因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 87.86 |
| 大单买入占比因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 38.15 |
| 买单集中度因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 32.47 |
| 卖单集中度因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 31.79 |
| 开盘后大单净买入占比因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 14.73 |
| 日内主买占比因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 49.80 |
| 大单买入强度因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 38.02 |
| 开盘后净主买占比因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 17.61 |
| 日内主买强度因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 38.02 |
| 开盘后净主买强度因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 16.81 |
| 卖单非流动性因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 29.79 |
| 买单非流动性因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 29.64 |
| 卖出反弹占比因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 34.94 |
| 剔除超大单后的普通大单买入占比因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 35.77 |
| 超大单买入占比因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 29.00 |
| 小买单主动成交度因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 1,035.52 |
| 剔除超大单影响后的大单涨跌幅因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 25.44 |
| 基于物理时间交易量加权的知情交易概率 | 2023 年 2 月通联 Level-2 逐笔成交 | 28.24 |
| 超大单涨跌幅因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 19.43 |
| 买入浮亏占比因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 33.64 |
| 买入浮亏偏离因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 20.28 |
| 开盘后大单净买入强度因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 14.06 |
| 大成交量委托单成交量占比因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 34.27 |
| 大成交量成交单成交量占比因子 | 2023 年 2 月通联 Level-2 逐笔成交 | 31.57 |
6. 常见问题解答(FAQ)
6.1 窄表存储的因子如何按照因子名转变为宽表形式?
本因子库推荐以窄表的形式存储因子。若实际业务场景需要宽表计算,用户可以使用 pivot by 语句将因子窄表按照因子名转变为宽表形式,示例代码如下:
dailyFactor = loadTable("dfs://factor_day","factor_day")
factorTB1 = select
Value
from dailyFactor
where FactorName in `skewVolProp`netBuyIntenOpen
pivot by SecurityID, TradeDate, FactorName6.2 如何把一个按照因子名展开的宽表处理成一个窄表?
若需要将宽表转化为窄表,可以使用 unpivot 函数:
factorTB2 =
select
SecurityID, TradeDate, value as Value, valueType as FactorName
from factorTB1.unpivot(`SecurityID`TradeDate, `skewVolProp`netBuyIntenOpen)6.3 如何将每个因子单独存储在独立的数据表中?
若用户需要将每个因子单独存储于同一个数据库下的不同表中,以成交量占比偏度因子为例,可将建库建表代码和任务函数调整为:
//删除已有数据库
if(existsDatabase("dfs://factor_day")) dropDatabase("dfs://factor_day")
//建立日频因子数据库
create database "dfs://factor_day"
partitioned by RANGE(date(datetimeAdd(1980.01M,0..80*12,'M'))),
engine='TSDB',
atomic='CHUNK'
//任务函数
def factorjob(conf){
dataTB = loadTable(conf[`dataDB], conf[`dataTB])
days = conf[`startDay]..conf[`endDay]
startTime = 09:27:00.000
endTime = 14:57:00.000
//提取计算所需数据,sqlDS生成元代码
ds = sqlDS(<select SecurityID, TradeDate, TradeTime, TotalVolumeTrade
from dataTB
where TradeDate in days and (TradeTime between startTime and endTime) and (SecurityID like "00%" or SecurityID like "30%" or SecurityID like "6%")>)
//计算因子,mr函数将因子在不同节点并行计算,unionAll函数将不同节点的计算结果汇总
res = mr(ds, conf[`func]).unionAll()
//创建因子表
db = database(conf[`factorDB])
tbName = conf[`factorName]
if(existsTable(conf[`factorDB], tbName)){dropTable(db, tbName)}
colNames = `SecurityID`TradeDate`Value`FactorName`UpdateTime
colTypes = [SYMBOL, DATE, DOUBLE, SYMBOL, TIMESTAMP]
t = table(1000:0, colNames, colTypes)
pt = createPartitionedTable(dbHandle=db,
table=t,
tableName=tbName,
partitionColumns=`TradeDate,
sortColumns=`SecurityID`TradeDate,keepDuplicates=ALL,
sortKeyMappingFunction=[hashBucket{, 500}])
//写入因子库,存储到磁盘做持久化
loadTable(conf[`factorDB], conf[`factorName]).append!(select * from res)
}请注意,这种存储因子的方式会导致一个数据库下有大量数据表,而每个表内仅有少量数据,不利于因子的查询与管理。因此,不建议采用此种存储方式。
6.4 如何处理用户数据字段名与因子计算字段名不一致的问题?
如果用户在计算因子时使用的数据集字段名与本教程中所列字段名不同,则需要调整任务函数中构造分布式数据源的 SQL 代码。以成交量占比偏度因子为例,示例如下:
def factorjob(conf){
dataTB = loadTable(conf[`dataDB], conf[`dataTB])
days = conf[`startDay]..conf[`endDay]
startTime = 09:27:00.000
endTime = 14:57:00.000
//提取计算所需数据,sqlDS生成元代码
//此处修改字段名
ds = sqlDS(<select ticker as SecurityID,
date(tradeTime) as TradeDate,
time(tradeTime) as TradeTime,
cumVolume as TotalVolumeTrade
from dataTB
where date(tradeTime) in days and (time(tradeTime) between startTime and endTime) and (ticker like "00%" or ticker like "30%" or ticker like "6%")>)
//计算因子,mr函数将因子在不同节点并行计算,unionAll函数将不同节点的计算结果汇总
res = mr(ds, conf[`func]).unionAll()
//写入因子库,存储到磁盘做持久化
loadTable(conf[`factorDB], conf[`factorTB]).append!(select * from res)
}注:如果计算的因子属于 4.2.1 小节中列出的需要额外数据集的因子,请在计算函数中修改额外数据集中的字段。
6.5 如何对计算得到的因子进行相关性分析?
DolphinDB 内置了多种相关性分析函数,如 corr 计算 Pearson 相关系数、spearmanr 计算 Spearman 相关系数等。本小节提供了一个因子相关性分析的示例,具体代码如下:
// 计算相关性函数
def factorCorr(factor1, factor2, method){
con = ej(factor1, factor2, `SecurityID`TradeDate)
if(method == `pearson){
return corr(con[`Value], con[`factor2_Value])
}
if(method == `spearman){
return spearmanr(con[`Value], con[`factor2_Value])
}
if(method == `kendall){
return kendall(con[`Value], con[`factor2_Value])
}
}
//相关性分析
factorTB = loadTable("dfs://factor_day", `factor_day)
factor1 = select * from factorTB where FactorName = `skewVolProp
factor2 = select * from factorTB where FactorName = `netBuyIntenOpen
result = factorCorr(factor1, factor2, `pearson)该相关性计算函数可以计算两个因子之间的 Pearson 相关系数、Spearman 相关系数和 Kendall 相关系数。传入参数为两张因子表和需要计算的相关系数类型,输出为 DOUBLE 类型的相关系数。
7. 因子与计算代码汇总
7.1 因子库代码
本因子库中所有因子脚本均整理在以下压缩包中,用户可根据自有数据库表进行修改使用。
7.2 因子库因子列表
7.2.1 基于分钟 K 线的因子
| 因子名 | 因子计算逻辑和含义 | 参考文献 |
|---|---|---|
| 最短路径非流动性因子 |
股价变动最短路径: 最短路径非流动性因子:股价变动最短路径与成交额的比值之和 |
基于K线路径构造的非流动性因子,光大证券 |
| 一致买入交易因子 |
集体一致交易:分钟数据满足
一致买入交易因子:在满足集体一致交易条件的 K 线中,上涨 K 线的总成交量与当日总成交量的比值 |
一致交易因子:挖掘集体行为背后的收益,光大证券 |
| 绝对收益与调整后滞后成交量相关性因子 |
调整后成交额: 绝对收益:对数收益率的绝对值 绝对收益与调整后滞后成交量相关性:绝对收益与前一时刻调整后成交额的相关系数 |
量价关系的高频乐章,方正证券 |
| 成交量“潮汐”的价格变动速率因子 |
领域成交量:日内第 n 分钟及其前后 4 分钟的总成交量 顶峰时刻:领域成交量最大值所在时刻 涨潮时刻:顶峰时刻前领域成交量最低点所在时刻 m 退潮时刻:顶峰时刻后领域成交量最低点所在时刻 n 潮汐价格变动速率:涨潮时刻较退潮时刻的收盘价变动速率除以 n-m |
个股成交量的潮汐变化及“潮汐”因子构建,方正证券 |
| 跌幅时间重心偏离因子 |
涨(跌)幅时间重心:上涨(下跌)时间依价格变动幅度的加权平均数 跌幅时间重心偏离:在截面跌时间重心对涨时间重心进行回归,得到的残差均值 |
日内分钟收益率的时序特征:逻辑讨论与因子增强,开源证券 |
| 一致交易因子 |
集体一致交易:满足
一致交易:一致交易 K 线的总成交量与当日总成交量的比值 |
一致交易因子:挖掘集体行为背后的收益,光大证券 |
| 成交额占比熵因子 | 每分钟成交额占当日总成交额的比值的熵 | 高位成交因子一从量价匹配说起,长江证券 |
| 日内持续异常交易量因子 |
异常交易量:当前分钟交易量与过去一段时间分钟交易量均值的比值(本因子库中为过去 10 个交易时刻) 日内持续异常交易量: |
“持续异常交易量”选股因子PATV, 招商证券 |
|
日耀眼波动率因子
|
成交量激增时刻:成交量增长量大于当日差值序列均值 +1 倍标准差的时刻 耀眼波动率:成交量激增时刻及其随后四分钟区间内的 1 分钟收益率标准差 日耀眼波动率:交易日内所有耀眼波动率的均值 |
成交量激增时刻蕴含的 alpha值息,方正证券 |
|
日午蔽古木因子
|
对每天第 6 分钟到第 240 分钟的增量成交量数据进行带截距项的最小二乘回归: 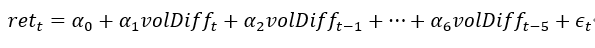 其中,volDiff 为 1 分钟增量成交量。 若回归方程的 F 值小于其横截面均值,午蔽古木因子为截距项 t 值的绝对值的负值,反之为截距项 t 值的绝对值。 |
推动个股价格变化的因素分解与“花隐林间”因子,方正证券 |
|
单一成交额占比熵因子
|
单一成交额占比熵计算公式为: 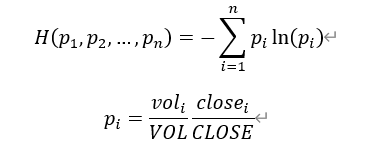 其中,voli和 closei分别为每分钟成交量和每分钟收盘价,VOL 和 CLOSE 分别为整个时间段总成交量和收盘价之和。 |
高位成交因子一从量价匹配说起,长江证券 |
|
日度灾后重建因子
|
更优波动率:对当前时刻及其前四分钟的高开低收的标准差与均值之比的平方 收益波动比:收益率与更优波动率之比 日度灾后重建因子:收益波动比与更优波动率的协方差 |
个股波动率的变动及“勇攀高峰”因子构建,方正证券 |
|
滞后绝对收益与调整后成交量相关性因子
|
调整后成交额: 绝对收益:对数收益率的绝对值 滞后绝对收益与调整后成交量相关性:前一时刻绝对收益与调整后成交额的相关系数 |
量价关系的高频乐章,方正证券 |
| 日耀眼收益率因子 |
成交量激增时刻:成交量增长量大于当日差值序列均值 +1 倍标准差的时刻 耀眼收益率:成交量激增时刻的分钟收益率 日耀眼收益率:交易日内所有耀眼收益率的均值 |
成交量激增时刻蕴含的 alpha值息,方正证券 |
| 日度勇攀高峰因子 |
更优波动比:对当前时刻及其前四分钟的高开低收的标准差与均值之比的平方 收益波动比:收益率与更优波动率之比 波动率异常高时刻:更优波动率大于其日内均值+1 倍标准差的时刻 日度勇攀高峰因子:当日波动率异常高时刻的收益波动比序列和更优波动率序列的协方差 |
个股波动率的变动及“勇攀高峰”因子构建,方正证券 |
|
绝对收益与成交量相关性因子
|
对数收益率:当前价格与前一时刻价格之比的对数 绝对收益与成交量相关性:对数收益率的绝对值与成交额的相关系数 |
量价关系的高频乐章,方正证券 |
| 绝对收益与滞后成交量相关性因子 | 绝对收益与滞后成交量相关性:对数收益率的绝对值与前一时刻成交额的相关系数 | 量价关系的高频乐章,方正证券 |
| 滞后绝对收益与成交量相关性因子 | 前一时刻对数收益率的绝对值与成交额的相关系数 | 量价关系的高频乐章,方正证券 |
| 日朝没晨雾因子 | 对每天第 6 分钟到第 240 分钟的增量成交量数据进行带截距项的最小二乘回归: 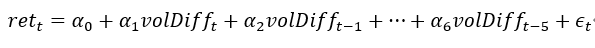 其中,volDiff 为 1 分钟增量成交量。 日朝没晨雾因子:五阶增量成交量回归系数的 t 值的标准差 |
推动个股价格变化的因素分解与“花隐林间”因子,方正证券 |
|
T 分布主动占比因子
|
T 分布主动买入金额: T 分布主动占比因子:T 分布主动买入金额除以当日总成交额 |
分布估计下的主动成交占比,长江证券 |
|
置信正态分布主动占比因子
|
置信正态分布主动买入金额: 置信正态分布主动占比因子:置信正态分布主动买入金额除以当日总成交额 |
分布估计下的主动成交占比,长江证券 |
|
朴素主动占比因子
|
朴素主动买入金额: 朴素主动占比因子:主动买入金额除以当日总成交额 |
分布估计下的主动成交占比,长江证券 |
|
均匀分布主动占比因子
|
均匀分布主动买入金额: 均匀分布主动占比因子:均匀分布主动买入金额除以当日总成交额 |
分布估计下的主动成交占比,长江证券 |
| 成交量波峰计数因子 |
成交量波峰:成交量大于当日成交量均值 + 1 倍标准差的时刻 成交量波峰计数因子:统计每条记录与上一条记录时间差超过 1 分钟的记录条数 |
高频波动中的时间序列信息,长江证券 |
|
日模糊金额比因子
|
波动率:当前时刻及之前 4 分钟内收益率的标准差 模糊性:当前时刻及之前 4 分钟内波动率的标准差 起雾时刻:模糊性大于当日模糊性均值的时刻 雾中金额:起雾时刻的成交金额均值 日模糊金额比:雾中金额除以当日成交金额均值 |
波动率的波动率与投资者模糊性厌恶,方正证券 |
| 日模糊数量比因子 |
波动率:当前时刻及之前 4 分钟内收益率的标准差 模糊性:当前时刻及之前 4 分钟内波动率的标准差 起雾时刻:模糊性大于当日模糊性均值的时刻 雾中数量:起雾时刻的成交量均值 日模糊数量比:雾中数量除以当日成交量均值 |
波动率的波动率与投资者模糊性厌恶,方正证券 |
| P 型成交量分布 |
同价成交量:将日内分钟收盘价相同的成交量累加在一起,得到成交量随价格的分布 成交量支撑点和成交量支撑区域:成交量累计最大的价格及其附近区域(区域累积成交量达全天成交量 50% 的最小区域) P 型成交量分布:成交量支撑区域下限价格与当日最高价之差 |
成交量分布中的 Alpha,兴业证券 |
| B 型成交量分布 |
同价成交量:将日内分钟收盘价相同的成交量累加在一起,得到成交量随价格的分布 成交量支撑点和成交量支撑区域:成交量累计最大的价格及其附近区域(区域累积成交量达全天成交量 50% 的最小区域) B 型成交量分布:成交量支撑区域上限价格与当日最低价之差 |
成交量分布中的 Alpha,兴业证券 |
| 修正日模糊价差因子 |
日模糊价差:日模糊金额比-日模糊数量比 修正日模糊价差:将横截面上值为负的日模糊价差求和,记为 s1;将负的日模糊价差除以其过去 10 日日模糊价差的标准差,值为正的日模糊价差不变 调整数量级:将横截面上值为负的修正日模糊价差求和,记为 s2;将值为负的修正日模糊价差除以 s2 后乘以 s1 |
波动率的波动率与投资者模糊性厌恶,方正证券 Ambiguity about velatlity and investor behaviot, Journal of Financial Economics |
| 成交量支撑区域下限与收盘价差异因子 |
同价成交量:将日内分钟收盘价相同的成交量累加在一起,得到成交量随价格的分布 成交量支撑点和成交量支撑区域:成交量累计最大的价格及其附近区域(区域累积成交量达全天成交量 50% 的最小区域) 成交量支撑区域下限与收盘价差异:成交量支撑区域最低价与当日收盘价的差 |
成交量分布中的 Alpha,兴业证券 |
| 模糊关联度因子 |
波动率:当前时刻及之前 4 分钟内收益率的标准差 模糊性:当前时刻及之前 4 分钟内波动率的标准差 模糊关联度:模糊性序列和时刻成交额序列的相关系数 |
波动率的波动率与投资者模糊性厌恶,方正证券 |
7.2.2 基于 Level-2 行情快照的因子
| 因子名 | 因子计算逻辑和含义 | 参考文献 |
|---|---|---|
| 时间加权平均的股票相对价格位置因子 | 股票当期价格相对区间最高最低价的分位数: 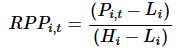 时间加权平均的股票相对价格位置: 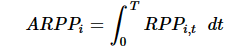 |
基于时间尺度度量的日内买卖压力,东方证券 |
| 高频上行波动占比因子 |
收益率:price / 上一时刻 price - 1 上行收益率:收益率大于0 高频上行波动占比:上行收益率的平方和与收益率平方和之比 |
高频因子之已实现波动分解,海通证券 |
| 高频下行波动占比因子 |
收益率:price / 上一时刻 price - 1 下行收益率:收益率小于0 高频下行波动占比:下行收益率的平方和与收益率平方和之比 |
高频因子之已实现波动分解,海通证券 |
| 已实现波动率因子 |
对数收益率序列:收益率的对数 已实现波动率:对数收益率序列平方和的平方根 |
The distribution of exchange rate volatlity. Jounal of the Amencan Statistical Association 96,42-55 |
| 上行已实现波动率因子 |
对数收益率序列:收益率的对数 上行已实现波动率:大于 0 的收益率的平方和的平方根 |
Measuting downside risk realised semivariance, In Volatlity and Time Series Econometncs Essays in Honor of Robert F Engle Edited by T Boliersiev.J Russell and M. Watson), Oxford University Press,117-136. |
| 下行已实现波动率因子 |
对数收益率序列:收益率的对数 下行已实现波动率:小于 0 的收益率的平方和的平方根 |
Measuting downside risk realised semivariance, In Volatlity and Time Series Econometncs Essays in Honor of Robert F Engle Edited by T Boliersiev.J Russell and M. Watson), Oxford University Press,117-136. |
|
高频已实现偏度因子
|
收益率:price / 上一时刻 price - 1 高频已实现偏度:收益率的偏度 |
高频因子之股票收益分布特征,海通证券 |
| 高频已实现峰度因子 |
收益率:price / 上一时刻 price - 1 高频已实现峰度:收益率的峰度 |
高频因子之股票收益分布特征,海通证券 |
| 上下行波动率不对称性因子 |
已实现波动率:对数收益率序列平方和 上行已实现波动率:大于 0 的收益率的平方和 下行已实现波动率:小于 0 的收益率的平方和 上下行波动率不对称性:上行已实现波动率与下行已实现波动率之差除以已实现波动率 |
Measuting downside risk realised semivariance, In Volatlity and Time Series Econometncs Essays in Honor of Robert F Engle Edited by T Boliersiev.J Russell and M. Watson), Oxford University Press,117-136. |
| 中间价变化率偏度因子 |
市场中间价:买一价与卖一价的均值 中间价变化率:(当前时刻中间价/前一时刻中间价)-1 中间价变化率偏度:中间价变化率的偏度 |
高频订单失衡及价差因子,中信建投证券 |
| 中间价变化率最大值因子 |
市场中间价:买一价与卖一价的均值 中间价变化率:(当前时刻中间价/前一时刻中间价)-1 中间价变化率最大值:中间价变化率的最大值 |
高频订单失衡及价差因子,中信建投证券 |
| 大成交量已实现偏度因子 |
大成交量:分钟成交量在当日排名前 1/3 的成交量 大成交量已实现偏度:大成交量订单收益率的偏度 |
高频价量数据的因子化方法,广发证券 |
| 大成交量价量相关性因子 |
大成交量:分钟成交量在当日排名前 1/3 的成交量 大成交量价量相关性:大成交量订单成交量和价格的相关系数 |
高频价量数据的因子化方法,广发证券 |
| 已实现双幂次变差因子 | 已实现双幂次变差:日内对数收益率的绝对值与前一时刻对数收益率的绝对值的乘积之和 | Power and bipower variation with stochastic volatility and jumps. Journal of Financial Econometrics.2.1-48 |
| 已实现三幂次变差因子 | 已实现三幂次变差:首先计算每一时刻与 t-1 时刻、t-2 时刻对数收益率绝对值的乘积的 2/3 次方,其次计算日内所有该值之和 | Power and bipower variation with stochastic volatility and jumps. Journal of Financial Econometrics.2.1-48 |
| 日度惊恐度因子 |
偏离度:个股收益率与市场收益率的差的绝对值(选取中证全指 000985 代表市场水平) 基准项:个股收益率的绝对值+市场收益率的绝对值+0.1 日度惊恐度:偏离度与基准项之比
|
显著效应、极端收益扭曲决策权重和“草木皆兵”因子,2022.方正证券 Cosemans M, Frehen R.2021, Salience theory and stock prices: Empirical evidence, Journal of Financial Economics.140(2),480-483 |
| 成交量分桶熵因子 |
将日内分钟成交量基于最大值、最小值区间进行等距分桶,并统计各个区间的概率; 分桶信息熵:每个区间计算pk*ln(pk) 的值并求和,然后乘以-1 |
成交量分布中的Alpha,兴业证券 |
| 已实现跳跃波动率因子 |
已实现三幂次变差:首先计算每一时刻与 t-1 时刻、t-2 时刻对数收益率绝对值的乘积的 2/3 次方,其次计算日内所有该值之和 积分波动估计量:已实现三幂次变差乘以常数 1.935792405 (正态分布的 2/3 阶绝对矩) 已实现跳跃波动率:max(对数收益率的平方和与积分波动估计量之差,0) |
Power and bipower variation with stochastic volatility and jumps. Journal of Financial Econometrics.2.1-48. New Evidence of the Marginal Predictve Content of Small and Large Jumps in the Cross-Section, Econometrics, MDPI, 8(2), 1-52. |
| 交易量变异系数因子 | 日内成交额序列的标准差除以均值 | 再觅知情交易者的踪迹,招商证券 |
| 上行已实现跳跃波动率因子 |
已实现三幂次变差:首先计算每一时刻与 t-1 时刻、t-2 时刻对数收益率绝对值的乘积的 2/3 次方,其次计算日内所有该值之和 积分波动估计量:已实现三幂次变差乘以常数 1.935792405 (正态分布的 2/3 阶绝对矩) 上行已实现跳跃波动率:max(收益率大于 0 的对数收益率的平方和与积分波动估计量的一半之差,0) |
New Evidence of the Marginal Predictve Content of Small and Large Jumps in the Cross-Section, Econometrics, MDPI, 8(2), 1-52. |
| 下行已实现跳跃波动率因子 |
已实现三幂次变差:首先计算每一时刻与 t-1 时刻、t-2 时刻对数收益率绝对值的乘积的 2/3 次方,其次计算日内所有该值之和 积分波动估计量:已实现三幂次变差乘以常数 1.935792405 (正态分布的 2/3 阶绝对矩) 下行已实现跳跃波动率:max(收益率小于 0 的对数收益率的平方和与积分波动估计量的一半之差,0) |
New Evidence of the Marginal Predictve Content of Small and Large Jumps in the Cross-Section, Econometrics, MDPI, 8(2), 1-52. |
| 聪明钱因子 |
原始聪明钱因子:每分钟涨跌幅绝对值与成交量的四次方根之比 聪明钱交易:将原始聪明钱因子按从大到小排序后,成交量累计占比 20% 的分钟交易 成交量加权平均价:将价格按照成交量大小进行加权平均 聪明钱因子:聪明钱交易的成交量加权平均价除以所有交易的成交量加权平均价 |
聪明钱因子模型的2.0版本, 开源证券 |
| 成交量占比偏度因子 | 日内成交量占比序列的偏度 | 高频因子(四). 高阶矩高频因子, 长江证券 |
| 成交量占比峰度因子 | 日内成交量占比序列的峰度 | 高频因子(四). 高阶矩高频因子, 长江证券 |
| 日度主力交易情绪因子 | 日内单笔成交金额序列和收盘价序列的秩相关性 | 高频因子:分钟单笔金额序列中的主力行为刻画,开源证券 |
| 趋势占比因子 | 当日收盘价减开盘价,除以每一时刻价格变化量绝对值之和 | 高频价量数据的因子化方法,广发证券 |
| 上下行跳跃波动的不对称性因子 |
已实现三幂次变差:首先计算每一时刻与 t-1 时刻、t-2 时刻对数收益率绝对值的乘积的 2/3 次方,其次计算日内所有该值之和 积分波动估计量:已实现三幂次变差乘以常数 1.935792405 (正态分布的 2/3 阶绝对矩) 上行(下行)已实现跳跃波动率:max(收益率大于(小于) 0 的对数收益率的平方和与积分波动估计量的一半之差,0) 上下行跳跃波动的不对称性:上行已实现跳跃波动率与下行已实现跳跃波动率之差 |
New Evidence of the Marginal Predictve Content of Small and Large Jumps in the Cross-Section, Econometrics, MDPI, 8(2), 1-52. |
| 最大涨幅因子 | 日内涨跌幅最大的前 10% 时刻的涨跌幅加 1 后连乘 | 高频选股因子分类体系,中信建投证券 |
| 大单资金净流入率因子 |
平均单笔成交金额:每分钟成交金额总额除以成交笔数 大单筛选:平均单笔成交金额最大的 30% 的时刻 大单资金净流入金额:收益率为正的成交总额与收益率为负的成交总额之差 大单资金净流入率:大单资金净流入金额除以当日成交总额 |
日内分时成交中的玄机,海通证券 |
| 大单驱动涨幅因子 |
平均单笔成交金额:每分钟成交金额总额除以成交笔数 大单筛选:平均单笔成交金额最大的 30% 的时刻 大单驱动涨幅:大单收益率加 1 后连乘 |
日内分时成交中的玄机,海通证券 |
| 每笔成交量筛选的局部反转因子 | 每笔成交量(成交量/成交笔数)位于 80%~100% 区间对应时间段的收益率之和 | 量价关系中的反转微观结果,长江证券 |
| 平均单笔流出金额占比因子 | 收益率小于 0 的平均单笔成交金额除以总体平均单笔成交金额 | 日内分时成交中的玄机,海通证券 |
| 大的上行跳跃波动率因子 | 上行已实现跳跃波动率:max(收益率大于 0 的对数收益率的平方和与积分波动估计量的一半之差,0) 判别阈值: 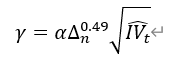 其中,α 经验参数为 4,Δ 为日内股票收益率的采样间隔,IV 为积分波动估计量 大的上行跳跃波动率: min(上行已实现跳跃波动率,高于判别阈值的对数收益率的平方和) |
Empincal evidence on the importance of aggregaton, asymmetry and jumps for volatlty ored cnon jourral af Econometrics.187 606-621 New Evidence of the Marginal Predictve Content of Small and Large Jumps in the Cross-Section, Econometrics, MDPI, 8(2), 1-52. |
| 大的下行跳跃波动率因子 | 下行已实现跳跃波动率:max(收益率小于 0 的对数收益率的平方和与积分波动估计量的一半之差,0) 判别阈值: 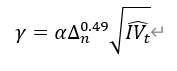 其中,α 经验参数为 4,Δ 为日内股票收益率的采样间隔,IV 为积分波动估计量 大的下行跳跃波动率: min(下行已实现跳跃波动率,小于判别阈值相反数的对数收益率的平方和) |
Empincal evidence on the importance of aggregaton, asymmetry and jumps for volatlty ored cnon jourral af Econometrics.187 606-621 New Evidence of the Marginal Predictve Content of Small and Large Jumps in the Cross-Section, Econometrics, MDPI, 8(2), 1-52. |
| 小的上行跳跃波动率因子 | 上行已实现跳跃波动率:max(收益率大于 0 的对数收益率的平方和与积分波动估计量的一半之差,0) 判别阈值: 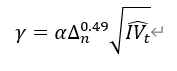 其中,α 经验参数为 4,Δ 为日内股票收益率的采样间隔,IV 为积分波动估计量 大的上行跳跃波动率: min(上行已实现跳跃波动率,高于判别阈值的对数收益率的平方和) 小的上行跳跃波动率: 上行已实现跳跃波动率与大的上行已实现跳跃波动率之差 |
Empincal evidence on the importance of aggregaton, asymmetry and jumps for volatlty ored cnon jourral af Econometrics.187 606-621 New Evidence of the Marginal Predictve Content of Small and Large Jumps in the Cross-Section, Econometrics, MDPI, 8(2), 1-52. |
| 小的下行跳跃波动率因子 | 下行已实现跳跃波动率:max(收益率小于 0 的对数收益率的平方和与积分波动估计量的一半之差,0) 判别阈值: 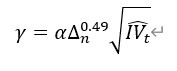 其中,α 经验参数为 4,Δ 为日内股票收益率的采样间隔,IV 为积分波动估计量 大的下行跳跃波动率: min(下行已实现跳跃波动率,小于判别阈值相反数的对数收益率的平方和) 小的下行跳跃波动率: 下行已实现跳跃波动率与大的下行已实现跳跃波动率之差 |
Empincal evidence on the importance of aggregaton, asymmetry and jumps for volatlty ored cnon jourral af Econometrics.187 606-621 New Evidence of the Marginal Predictve Content of Small and Large Jumps in the Cross-Section, Econometrics, MDPI, 8(2), 1-52. |
| 日内条件在险价值因子 | 分钟 VWAR:分钟收益率序列依交易量的加权平均数 VaR (在险价值): 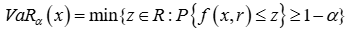 CVaR: 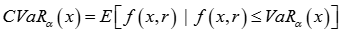 VCVaR:交易日分钟 VWAR 的置信度为 α 的 CVaR |
分钟线的尾部特征,方正证券 |
| 隔夜收益率因子 | 当日开盘价与前一日收盘价之比减 1 | Overnight Return: the invisible Hand Behind intraday Returns, Journal of Financial Econometrics. 2.90-100 |
| 日内最大回撤因子 | 交易日内价格峰值到随后谷值的最大跌幅 | 高频价量数据的因子化方法,广发证券 |
| 日内成交量占比标准差因子 | 日内时刻成交量占比的标准差 | 高阶矩高频因子, 长江证券 |
| 每笔成交量收益率相关性因子 | 分钟平均每笔成交量与收益率的相关系数 | 量价关系中的反转微观结果,长江证券 |
| 日内收益率因子 | 当日收盘价与当日开盘价之比减 1 | Overnight Return: the invisible Hand Behind intraday Returns, Journal of Financial Econometrics. 2.90-100 |
| 分钟成交额方差因子 | 日内分钟成交额的方差 | 高频视角下成交额蕴藏的Alpha,华安证券 |
| 尾盘半小时收益率因子 | 14:30~15:00 的收盘价收益率 | 高频价量数据的因子化方法,广发证券 |
| 日度盘口价差因子 |
盘口价差: 日度盘口价差:盘口价差序列的均值 |
高频视角下的微观流动性与波动性,中金公司 |
| 尾盘半小时成交额占比因子 | 14:30~15:00 的成交额占当日总成交额比值 | 高频视角下成交额蕴藏的Alpha,华安证券 |
| 大的上下行跳跃波动不对称性因子 | 上行(下行)已实现跳跃波动率:max(收益率大于(小于) 0 的对数收益率的平方和与积分波动估计量的一半之差,0) 判别阈值: 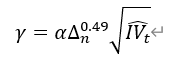 其中,α 经验参数为 4,Δ 为日内股票收益率的采样间隔,IV 为积分波动估计量 大的上行跳跃波动率: min(上行已实现跳跃波动率,高于判别阈值的对数收益率的平方和) 大的下行跳跃波动率: min(下行已实现跳跃波动率,小于判别阈值相反数的对数收益率的平方和) 大的上下行跳跃波动不对称性:大的上行跳跃波动率与大的下行跳跃波动率之差 |
Empincal evidence on the importance of aggregaton, asymmetry and jumps for volatlty prediction, journal of Econometrics.187 606-621 New Evidence of the Marginal Predictve Content of Small and Large Jumps in the Cross-Section, Econometrics, MDPI, 8(2), 1-52. |
|
小的上下行跳跃波动不对称性因子
|
上行(下行)已实现跳跃波动率:max(收益率大于(小于) 0 的对数收益率的平方和与积分波动估计量的一半之差,0) 判别阈值: 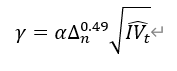 其中,α 经验参数为 4,Δ 为日内股票收益率的采样间隔,IV 为积分波动估计量 大的上行跳跃波动率: min(上行已实现跳跃波动率,高于判别阈值的对数收益率的平方和) 大的下行跳跃波动率: min(下行已实现跳跃波动率,小于判别阈值相反数的对数收益率的平方和) 小的上行(下行)跳跃波动率: 上行(下行)已实现跳跃波动率与大的上行(下行)已实现跳跃波动率之差 小的上下行跳跃波动不对称性:小的上行跳跃波动率与小的下行跳跃波动率之差 |
Empincal evidence on the importance of aggregaton, asymmetry and jumps for volatlty prediction, journal of Econometrics.187 606-621 New Evidence of the Marginal Predictve Content of Small and Large Jumps in the Cross-Section, Econometrics, MDPI, 8(2), 1-52. |
| 日度价格弹性因子 |
价格弹性:最高价与最低价之差与成交额的比值 日度价格弹性:价格弹性序列的均值 |
高频视角下的微观流动性与波动性,中金公司 |
| 日度盘口平均深度因子 |
盘口平均深度:买卖一量均值 日度盘口平均深度:盘口平均深度序列的均值 |
高频视角下的微观流动性与波动性,中金公司 |
| 加权收盘价比因子 | 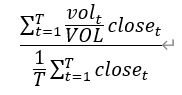 其中,VOL 为整个时间段总成交量 |
高位成交因子一从量价匹配说起,长江证券 |
| 结构化反转因子 | 动量时间段和反转时间段:将成交量从小到大进行排序,将小于等于10%的时间段记为动量时间段,大于10%的时间段记为反转时间段 动量时间段反转因子: 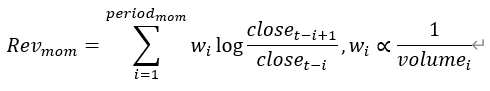 反转时间段反转因子: 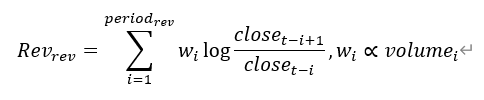 结构化反转因子:反转时间段反转因子与动量时间段动量因子之差 |
结构化反转因子,长江证券 |
| 日度有效深度因子 |
有效深度:买卖一量的最小值 日度有效深度:有效深度序列的均值 |
高频视角下的微观流动性与波动性,中金公司 |
| 分钟成交额自相关性因子 | 分钟成交额与其前1分钟的分钟成交额的相关系数 | 高频视角下成交额蕴藏的Alpha,华安证券 |
| 尾盘半小时成交量占比因子 | 14:30~15:00 的成交量占当日总成交量比值 | 高频因子的现实与幻想,海通证券 |
| 加权偏度因子 | 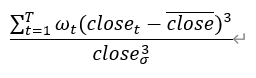 其中,权重 ω 为成交量占当日总成交量的比值,分母为收盘价的标准差的三次方 |
高位成交因子一从量价匹配说起,长江证券 |
| 交易量同步的知情交易概率因子 |
交易量桶:将交易量等量划分为交易量桶(此处设置单桶交易量为 100,000) 桶内买方交易量:桶内逐笔交易的加权和,权重为标准正态分布累计密度函数,其参数为环比增量与其标准差之比向量 桶内卖方交易量:桶量与买方交易量估计值之差 交易量同步的知情交易概率:买卖方交易量的绝对差之和,除以总交易量 |
Flow toxicity and liquidity in a high frequency world, Review of Financial Studies, 25(5),457-1493. |
7.2.3 基于逐笔委托的因子
| 因子名 | 因子计算逻辑和含义 | 参考文献 |
|---|---|---|
| 开盘后买入意愿强度因子 |
净委买变化额:委托买单增加量减去委托卖单增加量(逐笔委托) 净主买成交额:主动买入成交额减去主动卖出成交额 买入意愿:净主买成交额与净委买变化额之和 开盘后买入意愿强度:开盘后时间段(9:30~10:00)内买入意愿序列的均值除以标准差 |
基于直观逻辑和机器学习的高频数据低频化应用,海通证券 |
| 开盘后净委买增额占比因子 |
净委买变化额:委托买单增加量减去委托卖单增加量 开盘后净委买增额占比:开盘后时间段(9:30~10:00)内净委买变化额的总量除以同时间段内总成交额 |
捕捉投资者的交易意愿,海通证券 高频因子的现实与幻想,海通证券 |
|
开盘后买入意愿占比因子
|
净委买变化额:委托买单增加量减去委托卖单增加量(逐笔委托) 净主买成交额:主动买入成交额减去主动卖出成交额 买入意愿:净主买成交额与净委买变化额之和 开盘后买入意愿强度:开盘后时间段(9:30~10:00)内买入意愿的总和除以同时间段内总成交额 |
基于直观逻辑和机器学习的高频数据低频化应用,海通证券 |
7.2.4 基于逐笔成交的因子
| 因子名 | 因子计算逻辑和含义 | 参考文献 |
|---|---|---|
| 卖出反弹偏离因子 | (低于当日收盘价的卖单平均成交价之和 / 当日收盘价)-1 | 基于逐笔成交数据的遗憾规避因子,国金证券 |
| 大单买入占比因子 |
大单筛选:成交量对数调整后,成交量大于均值+1 倍标准差的成交单 大单买入占比:大买单成交总额除以总成交额 |
大单的精细化处理与大单因子重构,海通证券 买卖单数据中的Alpha,海通证券 |
| 买单集中度因子 | 买单成交额的平方和与总成交额的平方之比 | 买卖单数据中的Alpha,海通证券 |
| 卖单集中度因子 | 卖单成交额的平方和与总成交额的平方之比 | 买卖单数据中的Alpha,海通证券 |
| 开盘后大单净买入占比因子 |
大单筛选:成交量对数调整后,成交量大于均值+1 倍标准差的成交单 开盘后大单净买入占比:开盘后(9:30~10:00)大买单成交额与大卖单成交额之差 / 总成交额 |
买卖单数据中的Alpha,海通证券 大单的精细化处理与大单因子重构,海通证券 |
| 日内主买占比因子 |
主动买入成交额:剔除处于涨跌停分钟上的主动买入卖出金额数据,逐笔成交数据中的标识为“Buy”的成交额 日内主买占比:主动买入成交额占当日总成交额之比 |
基于主动买入行为的选股因子,海通证券 |
| 大单买入强度因子 |
大单筛选:成交量对数调整后,成交量大于均值+1 倍标准差的成交单 大单买入强度:大买单成交额的日内均值 / 大买单成交额的日内标准差 |
大单的精细化处理与大单因子重构,海通证券 |
| 开盘后净主买占比因子 |
净主买成交额:剔除处于涨跌停分钟上的主动买入金额数据,主动买入成交额与主动卖出成交额之差 开盘后净买入占比:开盘后(9:30~10:00)净主买成交额占总成交金额之比 |
基于主动买入行为的选股因子,海通证券 高频因子的现实与幻想,海通证券 |
| 日内主买强度因子 |
主动买入成交额:剔除处于涨跌停分钟上的主动买入卖出金额数据,逐笔成交数据中的标识为“Buy”的成交额 日内主买强度:主动买入成交额的均值与标准差之比 |
基于主动买入行为的选股因子,海通证券 |
| 开盘后净主买强度因子 |
净主买成交额:剔除处于涨跌停分钟上的主动买入金额数据,主动买入成交额与主动卖出成交额之差 开盘后净主买强度:开盘后(9:30~10:00)净主买成交额的均值与标准差之比 |
基于主动买入行为的选股因子,海通证券 高频因子的现实与幻想,海通证券 |
| 卖单非流动性因子 |
以收益率为因变量,主动卖出成交额和主动买入成交额为自变量进行线性回归,其中主动卖出成交额的回归系数
|
Sell-order liquidity and the cross section of expected stock retutns, Journat of Financial Economeics 105(3) 523-541 技术类新 Alpha 因子的批量测试, 东方证券 |
| 买单非流动性因子 | 以收益率为因变量,主动卖出成交额和主动买入成交额为自变量进行线性回归,其中主动买入成交额的回归系数 |
Sell-order liquidity and the cross section of expected stock retutns, Journat of Financial Economeics 105(3) 523-541 技术类新 Alpha 因子的批量测试, 东方证券 |
| 卖出反弹占比因子 | 卖价小于收盘价的所有卖单的成交量之和与总成交量的比值 | 基于逐笔成交数据的遗憾规避因子,国金证券 |
|
剔除超大单后的普通大单买入占比因子
|
大单筛选:成交金额的分位数大于 70% 的订单 超大单筛选:订单成交金额占当日成交总额比例超过 1% 的订单 剔除超大单后的普通大单买入占比:剔除超大单后的大买单成交金额占全部大单成交金额的比例 |
超大单冲击对大单因子的影响,东方证券 |
|
超大单买入占比因子
|
超大单筛选:订单成交金额占当日成交总额比例超过 1% 的订单 超大单买入占比:超大单买入成交金额占全部超大单成交金额的比例 |
超大单冲击对大单因子的影响,东方证券 |
| 小买单主动成交度因子 |
小单筛选:成交量对数调整后,成交量小于均值的成交单 小买单主动成交度:小买单主动成交金额占小买单成交金额的比例 |
买卖单主动成交中的隐藏信息,海通证券 |
|
剔除超大单影响后的大单涨跌幅因子
|
大单筛选:成交金额的分位数大于 70% 的订单 超大单筛选:订单成交金额占当日成交总额比例超过 1% 的订单 对数价格变动:当前成交价格的对数与上一笔成交价格的对数之差 剔除超大单影响后的大单涨跌幅:剔除超大单后,大单主动成交订单的累计对数价格变动 |
超大单冲击对大单因子的影响,东方证券
|
| 基于物理时间交易量加权的知情交易概率因子 | 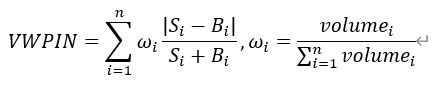 其中,Si和 Bi 分别第 i 个交易时段内的卖单数和买单数 |
知情交易概率与风险定价——基于不同PIN测度方法的比较研究,管理科学学报. 23(1). 33-46 |
|
超大单涨跌幅因子
|
超大单筛选:订单成交金额占当日成交总额比例超过 1% 的订单 对数价格变动:当前成交价格的对数与上一笔成交价格的对数之差 超大单涨跌幅:超大单主动成交订单的累计对数价格变动 |
超大单冲击对大单因子的影响,东方证券 |
| 买入浮亏占比因子 | 买单成交价大于当日收盘价的的买单成交量之和,除以当日总成交量 | 基于逐笔成交数据的遗憾规避因子,国金证券 |
| 买入浮亏偏离因子 | 买单成交价大于当日收盘价的的买单平均成交价之和,除以收盘价,减去1 | 基于逐笔成交数据的遗憾规避因子,国金证券 |
| 开盘后大单净买入强度因子 |
大单筛选:成交量对数调整后,成交量大于均值+1 倍标准差的成交单 开盘后大单净买入强度:开盘后(9:30~10:00)大买单成交额与大卖单成交额之差的日内均值除以其标准差 |
大单的精细化处理与大单因子重构,海通证券 |
| 大成交量委托单成交量占比因子 |
大成交量委托单筛选:按照委托单号统计成交量,成交量排前 5% 的委托单 大成交量委托单成交量占比:大成交量委托单成交总量占全天成交总量的比例 |
|
| 大成交量成交单成交量占比因子 |
大成交量成交单筛选:逐笔成交数据中成交量排前 5% 的订单 大成交量成交单成交量占比:大成交量成交单成交总量占全天成交总量的比例 |