DolphinDB 跨环境数据动态同步方案
随着高频交易与历史行情数据的规模急剧膨胀,企业数据总量已进入爆发式增长阶段。作为这类核心时序数据的承载平台,DolphinDB 面临着从单节点迁移到新集群、定期灾备、跨环境数据共享等日益复杂的运维需求。然而,传统的人工静态备份与恢复方式在庞大数据体量和高业务连续性要求下已难以为继:全量操作耗时长、占用存储资源多,且难以在业务持续写入的情况下保证数据的一致性与完整性。
针对这些挑战,DolphinDB 提供了BackupRestore模块——一种基于分区粒度的在线跨集群动态备份与恢复方案。它通过循环备份策略、磁盘空间水位控制及并行恢复等机制,从根本上解决了迁移过程中磁盘空间紧张和同步效率低下的问题,同时将运维人员从繁琐的手工操作中解放出来,实现了自动化、细粒度且高效的数据同步,为复杂生产环境下的数据运维提供了可靠保障。
1. 动态备份恢复方案
在 DolphinDB 的生产运维中,不同集群或节点间的数据同步是高频且关键的需求。然而,传统方案在数据体量、业务连续性和运维效率等方面均存在明显不足。为此,DolphinDB 设计了一套动态备份恢复方案,以分区粒度进行在线跨集群的数据备份与迁移,兼顾效率与可靠性。以下先介绍现有集群间数据同步的几种方式及其局限性,再详细阐述本方案的设计思路与核心流程。
1.1 现有集群间数据同步方案
目前,DolphinDB 环境下跨集群数据同步主要有以下三种方案:
方案一:全量备份与恢复
在旧环境使用backup系列函数备份数据,将备份文件经网络传输至新环境后,再通过restore系列函数完成恢复。该方案可通过脚本一次性完成全部数据同步,但存在明显不足:
-
若旧环境历史数据量过大,一次性备份将占用大量磁盘空间,甚至超出可用容量;
-
即使磁盘空间充足,备份、传输与恢复的总耗时也随数据量线性增长。加之操作期间须保证无数据写入或修改,否则将导致新旧环境数据不一致,因此必须安排业务停机窗口,对业务连续运行影响较大。
方案二:集群间异步复制
参考 DolphinDB 的集群间异步复制机制进行数据同步。该方案仅适用于集群异地容灾场景,且限制条件较多:
-
要求主从环境均为集群模式,不支持单节点与单节点、或单节点与集群之间的同步;
-
异步复制仅对配置完成后新增的数据生效,不支持历史数据的同步回溯。这意味着若需实现两个集群数据完全一致,必须在两者均为全新部署、尚无数据写入的初始状态下完成配置。
方案三:在线查询与插入
通过脚本从旧环境查询目标数据,再将结果插入新环境。此方案仅适用于待同步数据量较小的场景。对于整个环境的大规模数据迁移,操作繁琐且极其耗时,难以满足实际业务对效率的需求,不适合用作常规大规模数据迁移手段。
1.2 动态备份恢复方案
针对上述问题,本方案基于 DolphinDB 的backup和restore功能,以分区为单位进行在线数据同步。下图为方案的整体架构与关键流程:
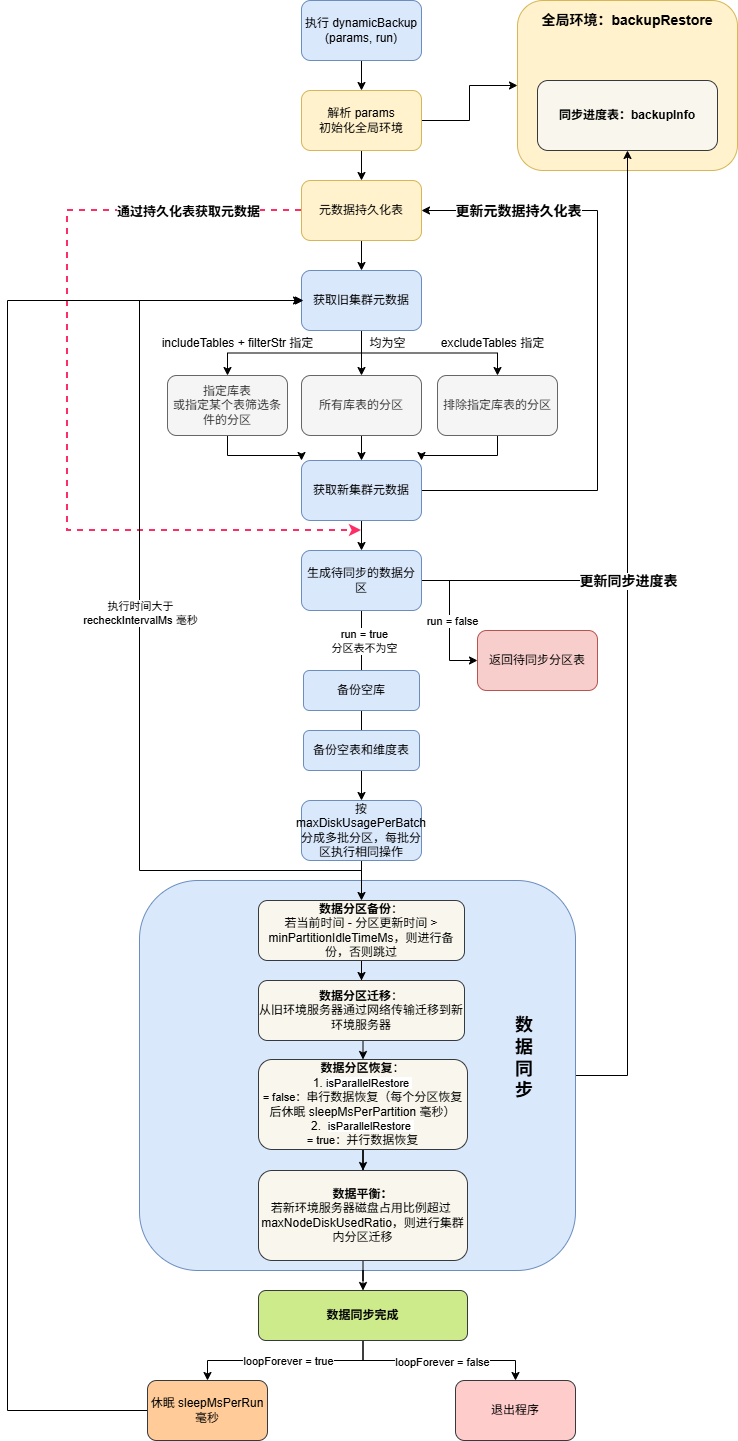
核心设计思想
不用一次性全量操作,而是按分区、分批、循环地备份和恢复。每批数据量可控,磁盘占用小,不需要长时间停写。方案同时兼容单节点与集群环境,支持本地和跨服务器两种传输模式。
参数管理与环境初始化
通过initParamsEnv(params)集中管理备份目录、恢复目录、服务器信息和磁盘阈值等关键参数,启动时自动校验环境,避免配置缺失。
数据迁移与多环境协同
跨服务器传输通过transferData接口,基于 SSH(rsync命令)完成。每批备份恢复完成后,deleteBackupRestoreData会自动清理临时文件,防止磁盘堆积。
注意:新旧环境位于不同服务器时,需满足两个条件:两端服务器已配置 SSH 免密登录;新环境 DolphinDB 已启用enableShellFunction = true。
空库与空表处理
对空数据库、空表和维度表,分别用backupRestoreDatabase和backupRestoreTable处理元数据、表结构和数据,确保结构完整,避免迁移盲区。
分区级动态备份与恢复
核心流程在backupRestorePartitions中实现:
-
同步元数据,判断分区是否写入完成,保证数据一致;
-
按分区增量备份,不搞全量;
-
支持并行或顺序恢复,灵活控制资源消耗;
-
实时更新元数据表和状态表,方便监控进度和排查故障;
-
新环境磁盘使用率过高时,自动触发副本迁移,均衡负载。
动态执行与自动化循环
整体逻辑封装在dynamicBackup函数中,支持单次全量同步或周期性无限循环。循环模式下会持续刷新元数据,动态调整待同步分区,保证时效性。
2. 动态备份恢复模块
以上方案通过BackupRestore模块落地。本章说明模块结构、功能组成与使用方式。
2.1 模块结构与功能
BackupRestore模块的文件结构为:
BackupRestore/
├── funcDefine.dos
├── mainFrame.dos
├── newEnv.dos
└── utils.dos其中,每个文件的功能分别为:
| 文件名 | 功能 |
|---|---|
funcDefine.dos |
定义新旧环境共同用到的函数 |
mainFrame.dos |
定义完成整个迁移备份流程的函数 |
newEnv.dos |
定义新集群环境操作的函数 |
utils.dos |
定义整个模块需要用到的辅助函数 |
2.2 模块导入
在使用 BackupRestore 模块前,需要先将该模块文件上传并同步至目标服务器。当 DolphinDB 调用模块时,系统会在指定路径下查找相应的模块文件。
同步路径
将模块放置于节点所在 Home 目录的 module 目录下,节点所在 Home 目录可通过getHomeDir函数获取,假设Home 目录为: /DolphinDB/server,那么需要将模块文件放置于 /DolphinDB/server/modules/ 路径下。
如何同步
-
使用 xftp 等传输软件,将模块传输至服务器上指定的路径。
-
使用 scp 命令:
scp -r FuturesOLHC <user>@<服务器ip>:/DolphinDB/server/modules/。
2.3 如何使用模块
以下部分详细介绍BackupRestore模块的用法。
注意,该模块需要有以下依赖:两个服务器之间需要设置免密 scp执行模块的节点的配置项需要设置: enableShellFunction=true
2.3.1 操作步骤
-
连接上新环境的数据节点,若为集群模式,选择其中一个数据节点即可
-
在节点上执行数据同步脚本(以下部分详细介绍)
2.3.2 应用实践
-
导入
backupRestore模块 -
定义所需参数后,调用
dynamicBackup函数执行备份
clearCachedModules();
use BackupRestore::mainFrame
/*
执行前需保证:
1. 两个服务器之间能够免密 scp
2. 执行该脚本的节点的配置项 enableShellFunction=true
*/
params = {
loopForever:true, // 是否无限循环
excludeTables:[], // 排除的库表
includeTables:["dfs://level2_tl_test/entrust"], // 包含的库表
filterStr: NULL, // 适用于只同步某张表某个筛选条件的数据,includeTbs 必须设置且里面只包含一张表
sourceIP:"192.168.100.45", // 旧集群数据节点IP
sourcePort: 7912, // 旧集群数据节点端口号
sourceDDBUser: "admin",// 旧集群 dolphindb 用户名
sourceDDBPwd: "123456",// 旧集群 dolphindb 密码
sourceServerUser: "ymchen",// 旧集群服务器用户名
ctlMetaDbname: "dfs://ctlMeta1", // 存储元数据的库,自动创建
ctlMetaTableName: "data", // 存储元数据的表,自动创建
backupDir:"/data/backup", // 旧集群数据备份目录
restoreDir: "/data/restore", // 新集群数据恢复目录
maxDiskUsagePerBatch:2, // 每一批同步数据的磁盘占用阈值
maxNodeDiskUsedRatio:0.9, // 该执行节点的最大磁盘占用比例
isParallelRestore:true, // 是否并发恢复
sleepMsPerPartition:0, // 每个分区恢复后,停顿多少毫秒
sleepMsPerRun:60.0 * 1000, // 每次循环后,停顿多少毫秒
minPartitionIdleTimeMs:13824097482, // 每个分区的更新时间距离当前时间大于多少毫秒时,才能够备份和恢复(备份时,分区会锁住,如果此时还在写入,会报错,所以需要指定一定时间来避免这个问题)
recheckIntervalMs:20.0 * 60 * 1000 // 每隔多少毫秒重新对比新旧环境元数据
}
// 第二个参数指定是否真实执行
dynamicBackup(params, false)其中,需要定义传入若干个参数,分别为:
| 参数名 | 参数含义 | 附加说明 |
|---|---|---|
| loopForever |
是否无限循环
|
|
| excludeTables |
排除在外的库表
|
|
| includeTables |
待同步的库表
|
|
| filterStr |
数据筛选语句,字符串格式,适合只同步某张表某个条件下的数据,例如: 表示筛选: |
|
| sourceIP | 旧环境数据节点IP | |
| sourcePort | 旧环境数据节点端口号 | |
| sourceDDBUser | 旧环境 DolphinDB 数据节点用户名 | |
| sourceDDBPwd | 旧环境 DolphinDB 数据节点密码 | |
| sourceServerUser | 旧环境服务器用户名 | |
| ctlMetaDbname | 存储元数据的持久化库名 | 首次执行时会自动创建 |
| ctlMetaTableName | 存储元数据的持久化表名 | 首次执行时会自动创建 |
| backupDir | 存储备份数据的路径 | |
| restoreDir | 存储恢复数据的路径 |
|
| maxDiskUsagePerBatch | 每批同步数据的磁盘占用上限,单位为 GB | 不宜设置过高,推荐 1 - 10 |
| maxNodeDiskUsedRatio | 运行脚本所使用的数据节点磁盘的最大利用率,取值范围为 0 到 1 之间 |
|
| isParallelRestore |
是否并行恢复
|
|
| sleepMsPerPartition | 每个分区恢复后休眠多少毫秒 |
仅在 isParallelRestore = false 时生效 假设设置为 50,则每个分区恢复后休眠 50 毫秒,用于控制节点间网络传输 |
| sleepMsPerRun | 每一轮同步后休眠多少毫秒 | 仅在loopForever= true 时生效 |
| minPartitionIdleTimeMs | 分区的最短空闲时间(分区未发生更新),单位为毫秒 |
|
| recheckIntervalMs | 用于控制周期性地重新比对新旧数据环境的元数据,防止数据过时,单位为毫秒 |
|
3. 常见问题
3.1 怎么查看数据同步进度?
共享字典backupRestore中定义了一张同步信息表backupInfo,该表记录了每个分区的备份恢复信息,从而可以直观地统计备份与恢复的进度:
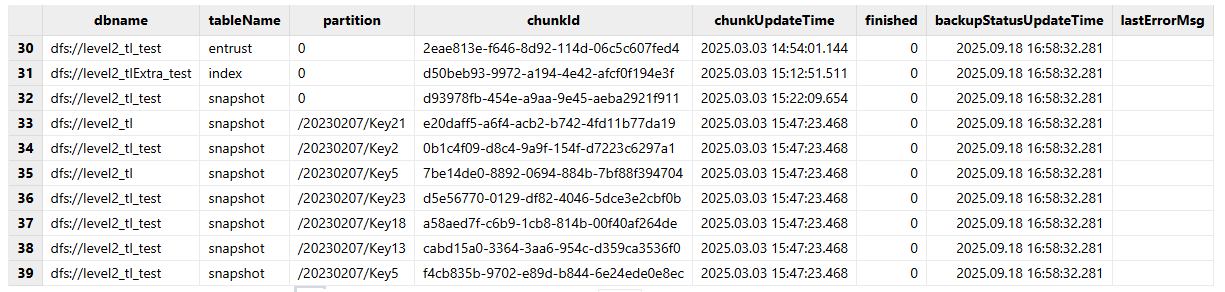
其中各字段含义如下:
| 字段名 | 含义 |
|---|---|
| dbname | 数据库名 |
| tableName | 数据表名,“0” 代表该分区为 domain 分区 |
| partition | 分区名, ”0” 代表该分区为 tbl 分区 |
| chunkId | 旧环境数据分区 ID,唯一 |
| chunkUpdateTime | 数据分区更新时间 |
| finished |
分区同步状态:
|
| backupStatusUpdateTime | 同步信息更新时间 |
| lastErrorMsg | 分区同步失败时最新的报错信息 |
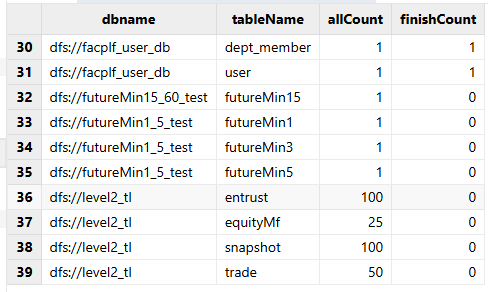
根据该信息表,即可动态获取数据同步的进度,例如:若要获取每个表的同步进度,可以执行以下脚本获取:
ctx = objByName("backupRestore", true)
info = ctx["backupInfo"]
status = select count(finished) as allCount, sum(finished == 1) as finishCount
from info
where tableName != "0" and partition != "0"
group by dbname, tableName返回结果如下,allCount表示全部待同步分区,finishCount表示已同步完成分区:
3.2 不同版本的 DolphinDB 之间可以同步吗?
分成以下几种情况:
-
2.00.x 和 2.00.y 之间可以互相同步
-
3.00.x 和 3.00.y 之间可以互相同步
-
从 2.00.x 到 3.00.y 可以同步
-
从 3.00.x 到 2.00.y 不能同步
3.3 当执行同步程序时,对于新旧环境会有什么潜在的影响,怎么解决?
当具体的数据分区备份和恢复时,会先锁定这个分区,因此如果该分区在备份或恢复的时候,有其他的任务对这个分区进行事务操作,则会失败报错,可以通过调整以下参数在极大程度上避免此类问题:
-
minPartitionIdleTimeMs参数指定了每个分区更新后需要至少等待多长时间才能进行同步,可以调大这个参数; -
maxDiskUsagePerBatch参数指定了每批同步的分区数据占用磁盘空间的阈值,通过调小这个参数可以缩短数据备份和恢复的范围和时间,减少冲突的概率。
3.4 新旧环境现有数据一样,是由同一源导入的,当启动此程序时,这些数据是否会同步?
此方案是通过比对新旧环境的数据分区元数据来判断是否需要同步,因此如果是同一上游导入相同数据到两个环境,虽然数据一致,但是元数据是不一致的,所有会进行同步。
3.5 此方案的数据同步速度如何?
此方案底层用的是backup和restore函数,如果新旧环境服务器不一样,还涉及数据的网络传输,因此,数据同步速度依赖于两部分:1. 备份恢复速度;2. 网络传输速度;
-
备份恢复速度:取决于磁盘速度,可参考:数据备份以及恢复 (1.30.20/2.00.8及之后版本)
-
网络传输速度:取决于具体环境的网络带宽
4. 总结
BackupRestore模块实现了跨集群、跨节点的在线数据迁移与同步,覆盖元数据获取、分区筛选、备份执行、恢复写入到元数据更新的完整流程。模块按库表或分区灵活选择同步对象,通过循环模式、磁盘占用阈值、并行恢复等参数实现细粒度控制。用户配置源集群信息与同步策略后即可快速启动,并实时监控进度。模块兼容空表、冲突分区及新旧版本差异等场景,结合持久化元数据表支持循环执行或中断后继续增量迁移。实际使用表明,该模块显著提升了数据运维的自动化水平与灵活性,跨大版本迁移时需注意字段兼容性限制。
5. 附件
-
动态备份恢复模块:BackupRestore.zip
-
调用脚本 Demo:testBackupRestore.dos