Real-Time Cloud-Edge Data Synchronization with DolphinDB
The widespread deployment of edge sensors has made real-time data synchronization between edge devices and the cloud a critical component for efficient system operation and intelligent decision-making. Real-time synchronization enables edge devices to transmit large volumes of data to the cloud for storage, analysis, and processing. This capability is vital across various domains, including industrial IoT, intelligent transportation, smart cities, healthcare, and smart homes. By enabling rapid response and real-time feedback, real-time data synchronization improves system responsiveness and enhances both user experience and service quality.
In cloud-edge synchronization scenarios, DolphinDB—a high-performance distributed time-series database and real-time computing platform—offers unique advantages.
- DolphinDB delivers exceptional real-time data processing capabilities, efficiently handling large-scale data streams from edge devices and synchronizing the results to the cloud with minimal latency. It supports data compression during transmission to improve synchronization efficiency. This is particularly valuable in latency-sensitive applications such as predictive maintenance in industrial systems, real-time traffic control, or smart home automation.
- Its distributed architecture and elastic scalability enable deployment across a wide range of environments—from lightweight edge devices to large-scale cloud clusters—and support hybrid deployments across both cloud and edge, ensuring fast and reliable data synchronization.
- DolphinDB also supports local data storage at the edge, enhancing data security and availability. Its lightweight and flexible development model simplifies deployment and maintenance across cloud and edge environments.
DolphinDB enables end-to-end data management from edge to cloud, combining efficient synchronization with real-time analytics. This capability facilitates digital transformation and accelerates innovation across IoT and distributed application scenarios.
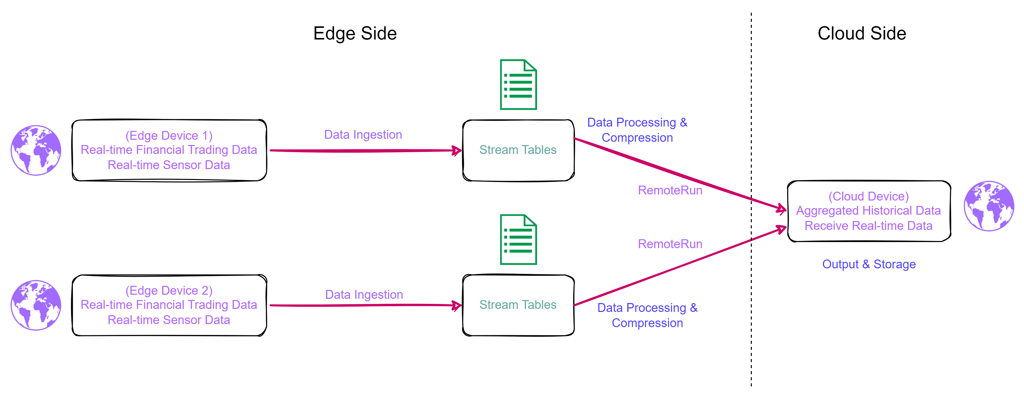
1. DolphinDB Real-Time Synchronization Architecture
DolphinDB implements a modular, extensible stream processing architecture designed for real-time computation and analytics on continuous data streams. Unlike traditional batch processing, DolphinDB performs incremental processing as data arrives, following the time-series nature of the stream. This significantly reduces processing latency, making it ideal for real-time synchronization.
The architecture introduces the concept of stream tables, which are integrated with a classic publish/subscribe (Pub/Sub) model. Upon insertion into a stream table, data is immediately published to a message queue, and publisher threads dispatch it to subscribers. This mechanism ensures real-time data delivery across distributed nodes.
The synchronization solution described in this document is built on these stream
processing capabilities. In DolphinDB, subscriptions can be local or remote. Local
subscriptions process and consolidate data at the edge, which can then trigger
synchronization to the cloud using the remoteRun function.
The remoteRun function in DolphinDB is designed for executing
functions or transferring data between distributed DolphinDB nodes. In cloud-edge
scenarios, edge nodes use remoteRun to invoke computation remotely
on the cloud server, passing serialized function definitions and parameters.
To optimize network usage, remoteRun supports data compression. Two
algorithms are currently available:
-
lz4: Faster decompression, lower compression ratio.
-
zstd: Higher compression ratio, slower decompression.
By leveraging stream tables for real-time data collection and distribution, and
combining them with local subscription and remoteRun calls, the
solution ensures low-latency, resource-efficient data synchronization. All
compression, transmission, and function orchestration are handled on the edge side,
allowing the cloud to maintain a lightweight processing load.
This end-to-end synchronization mechanism enables high-throughput, low-latency data integration across edge and cloud, making DolphinDB a robust solution for real-time, intelligent IoT applications.
2. Synchronization Implementation Example
This example demonstrates a cloud-edge synchronization scenario for inspection data collected by on-site robots. To comprehensively evaluate the functionality and performance of the synchronization mechanism, various data volumes and synchronization scenarios were simulated using DolphinDB scripts. The tests cover both real-time data synchronization and end-of-month batch synchronization, with the volume of each test ranging from 4,800 to 14.4 million records.
The simulated dataset represents 30 days of activity from 100 robots, totaling 14.4 million records (approximately 3.3 GB). The tests assessed transmission efficiency across different data sizes, with all records generated and synchronized in real time. Stream tables with built-in message queuing mechanisms were used for data ingestion and distribution. Robot inspection data was written to the stream table and then pushed to subscribers in real time.
To optimize storage and query performance, the receiving end used partitioned distributed tables. Following DolphinDB’s performance best practices and considering future scalability, data was partitioned by date. For details on partitioning strategies, refer to Partitioned Database Design and Operations.
For this dataset, the detect_time column was used as the partitioning key, dividing data into 30 date-based partitions. The device_id and detect_time were set as the sort columns to improve query efficiency. The modeling strategy is as follows:
if (existsDatabase("dfs://Robot")) { dropDatabase("dfs://Robot") }
CREATE DATABASE "dfs://Robot" PARTITIONED BY VALUE(2020.06.01..2026.06.30) ENGINE="TSDB"
CREATE TABLE "dfs://Robot"."data" (
device_id SYMBOL,
error BOOL,
detect_time TIMESTAMP,
temp DOUBLE,
humidity DOUBLE,
......
)
PARTITIONED BY detect_time
sortColumns=`device_id`detect_time For the complete data generation script and field descriptions, see Appendix 1.
3. Performance Evaluation
3.1 Test Environment
The test was conducted using two physical servers:
- One acted as the cloud node, responsible for receiving synchronized data.
- The other acted as the edge node, responsible for generating and sending data.
The hardware specifications and DolphinDB configurations are detailed in Tables 3-1 and 3-2.
| Host IP | Role |
|---|---|
| 10.0.0.80 | Simulated cloud device |
| 10.0.0.81 | Simulated edge device |
| Simulated Role | Quantity | Physical Setup | Configuration |
|---|---|---|---|
| Cloud Node | 1 | 1 Physical Server | OS: Centos 7.6 |
| CPU: Intel® Xeon® Silver 4214 @ 2.20GHz (48 logical cores with Hyper-Threading) | |||
| Mem: 188 GB | |||
| DolphinDB: 3.00.0.1 | |||
| Edge Node | 1 | 1 Physical Server | Disk: 2T SSD * 2 500M/s; 2T HDD*1 250M/s |
| Net: 100Mbps | |||
| DolphinDB: 3.00.0.1 |
The cloud node is configured as follows:
localSite=localhost:8848:local8848
mode=single
maxMemSize=32
maxConnections=512
workerNum=4
localExecutors=3
maxBatchJobWorker=4
dataSync=1
OLAPCacheEngineSize=2
TSDBCacheEngineSize=1
newValuePartitionPolicy=add
maxPubConnections=64
subExecutors=4
perfMonitoring=true
lanCluster=0
subThrottle=1
persistenceWorkerNum=1
maxPubQueueDepthPerSite=100000000To simulate the resource-constrained nature of edge devices, the edge node in this test is configured with 4 CPU cores and 8 GB of memory. The edge node configuration is detailed below:
localSite=localhost:8848:local8848
mode=single
maxMemSize=8
maxConnections=512
workerNum=4
localExecutors=3
maxBatchJobWorker=4
dataSync=1
OLAPCacheEngineSize=2
TSDBCacheEngineSize=2
newValuePartitionPolicy=add
maxPubConnections=64
subExecutors=4
perfMonitoring=true
lanCluster=0
subThrottle=1
persistenceWorkerNum=13.2 Real-Time Synchronization Performance Testing
This section evaluates DolphinDB’s synchronization performance across varying
data volumes, as well as its CPU, memory, and network bandwidth usage. The test
covers synchronization of datasets ranging from 4,800 to 14,400,000 records,
representing most real-world scenarios. Additionally, the resource consumption
and transmission efficiency under different compression algorithms (zstd and
lz4) when using the remoteRun function are analyzed to identify
the optimal scheme for different conditions.
| Data Volume (rows) | Compression Method | Elapsed Time (ms) | Average Sync Throughput (records/s) | CPU Usage | Memory Usage (GB) | Network Throughput (MB/s) |
|---|---|---|---|---|---|---|
| 4,800 | lz4 | 60 | 80,000 | 103% | 0.6 | 0.04 |
| zstd | 62 | 77,419 | 105% | 0.6 | 0.04 | |
| uncompressed | 74 | 64,864 | 105% | 0.6 | 0.06 | |
| 240,000 | lz4 | 1,883 | 127,456 | 120% | 0.7 | 1.22 |
| zstd | 1,720 | 139,535 | 120% | 0.7 | 0.94 | |
| uncompressed | 2,853 | 84,122 | 120% | 0.7 | 2.12 | |
| 1,920,000 | lz4 | 14,384 | 133,482 | 140% | 1.1 | 9.5 |
| zstd | 13,208 | 145,366 | 140% | 1.1 | 7.93 | |
| uncompressed | 22,362 | 85,859 | 145% | 1.1 | 11.5 | |
| 14,400,000 | lz4 | 108,529 | 132,683 | 140% | 1.7 | 10.1 |
| zstd | 98,080 | 146,819 | 140% | 1.8 | 8.85 | |
| uncompressed | 167,579 | 85,930 | 145% | 1.3 | 11.4 |
Note: All resource usage figures in the table represent peak values.
DolphinDB demonstrates efficient synchronization even at large data volumes while maintaining low CPU and memory consumption, effectively conserving cloud resources.
The results clearly show that compressed transmission outperforms uncompressed in both efficiency and synchronization speed. Comparing lz4 and zstd compression reveals that zstd achieves a higher compression ratio but requires longer decompression time. For smaller datasets, the decompression overhead causes zstd’s transmission efficiency to lag behind lz4. However, as data volume increases, zstd becomes increasingly faster than lz4. At very small volumes (4,800 records), all transmission methods exhibit similar throughput and resource consumption.
Comparing uncompressed with lz4 compressed transmission, network throughput peaks approach the bandwidth limits of the test environment. To further improve synchronization speed, increased resource allocation and higher network bandwidth are necessary. Uncompressed transmission requires sending the entire dataset without reduction, resulting in longer transfer times than the combined compression and decompression process, thus yielding slower overall speed.
For the zstd method, synchronization speed is primarily limited by the subscription and dispatch rate rather than network bandwidth. Therefore, improving performance for this mode requires upgrading the DolphinDB configuration.
Detailed implementation and testing procedures are described in the appendix.
4. Conclusion
The real-time synchronization approach presented in this document leverages DolphinDB’s compression-based transmission to achieve efficient data transfer while minimizing memory and network usage. It significantly reduces the cloud's computational and bandwidth load, offering a cloud-lightweight and efficient synchronization solution.
However, this approach imposes certain operational and implementation requirements.
It involves capturing real-time data on the edge, packaging it, and transmitting it
to the cloud via the remoteRun function. Preprocessing on the edge
enables edge computing, which helps offload processing from the cloud. This
increases the operational burden on edge-side personnel, who must be familiar with
cloud-side data processing logic and proficient in using DolphinDB functions.
Overall, this synchronization strategy is best suited for scenarios where edge devices have sufficient idle resources, while cloud resources and network bandwidth are constrained.
Appendix
Appendix 1: Simulated Data Field Description
| Field Name | Data Type | Description |
|---|---|---|
| device_id | LONG | Robot device ID |
| error | BOOL | Error status |
| detect_time | TIMESTAMP | Data reporting time |
| temp | DOUBLE | Temperature |
| humidity | DOUBLE | Humidity |
| temp_max | DOUBLE | Maximum temperature recorded |
| humidity_max | DOUBLE | Maximum humidity recorded |
| trace | INT | Preset operating path of the device |
| position | SYMBOL | Current position of the device |
| point_one | BOOL | Whether point 1 is reached |
| point_two | BOOL | Whether point 2 is reached |
| point_three | BOOL | Whether point 3 is reached |
| point_four | BOOL | Whether point 4 is reached |
| point_five | BOOL | Whether point 5 is reached |
| point_six | BOOL | Whether point 6 is reached |
| point_seven | BOOL | Whether point 7 is reached |
| point_eight | BOOL | Whether point 8 is reached |
| point_nine | BOOL | Whether point 9 is reached |
| point_ten | BOOL | Whether point 10 is reached |
| responsible | SYMBOL | Person in charge |
| create_time | TIMESTAMP | Record creation time |
| rob_type | INT | Robot type |
| rob_sn | SYMBOL | Robot serial number |
| rob_create | TIMESTAMP | Robot creation time |
| rob_acc1 | DOUBLE | Robot accuracy metric 1 |
| rob_acc2 | DOUBLE | Robot accuracy metric 2 |
| rob_acc3 | DOUBLE | Robot accuracy metric 3 |
| rob_acc4 | DOUBLE | Robot accuracy metric 4 |
| rob_acc5 | DOUBLE | Robot accuracy metric 5 |
Appendix 2: Implementation of Synchronization Methods
Compression
The implementation begins by creating a database on the receiving end using the
same schema described earlier. On the sending side, a stream table is created
and subscribed to locally. A handler function is defined to be triggered
whenever new data is written into the stream table. The function compresses the
data using the compress function and transmits it to the
receiving end using the remoteRun function. On the receiving
side, the data is decompressed using decompress and then
written into the target database.
Since stream table subscriptions send data in segments as new data arrives, the transmission time is also measured in segments. To capture this, the receiving end maintains a table to log the elapsed time for each segment received during subscription.
The core implementation code for this process is shown below.
Cloud Side (Receiver):
login("admin","123456")
share streamTable(1:0,`sourceDevice`startTime`endTime`cost`rowCount,[INT,TIMESTAMP,TIMESTAMP,DOUBLE,INT]) as timeCost
colNames = `device_id`error`detect_time`temp`humidity`temp_max`humidity_max`trace`position`Point_one`point_two`point_three`point_four`point_five`point_six`point_seven`point_eight`point_nine`point_ten`responsible`create_time`rob_type`rob_sn`rob_create`rob_acc1`rob_acc2`rob_acc3`rob_acc4`rob_acc5
colTypes = [SYMBOL,BOOL,TIMESTAMP,DOUBLE,DOUBLE,DOUBLE,DOUBLE,INT,SYMBOL,BOOL,BOOL, BOOL, BOOL, BOOL, BOOL, BOOL, BOOL, BOOL, BOOL, SYMBOL, TIMESTAMP, INT, SYMBOL, TIMESTAMP, DOUBLE, DOUBLE, DOUBLE, DOUBLE, DOUBLE]
if(existsDatabase("dfs://Robot")){dropDatabase("dfs://Robot");}
data= table(1:0, colNames, colTypes)
db = database(directory = "dfs://Robot",partitionType = VALUE, partitionScheme = [today()],engine=`TSDB)
createPartitionedTable(dbHandle=db, table=data, tableName = `data, partitionColumns = `detect_time,sortColumns = `device_id`detect_time)Edge Side (Sender):
def pushData(ip,port,compressMethod,msg){
pubNodeHandler1=xdb(ip,port,`admin,123456)
StartTime=now()
table1=select * from msg;
y=compress(table1,compressMethod)
remoteRun(pubNodeHandler1,'def insertTableToDatabase(y,StartTime){
pt=loadTable("dfs://Robot",`data)
pt.append!(decompress(y))
endTime=now()
duration=endTime-StartTime
tmp = table([0] as c1,[StartTime] as c2,[endTime] as c3,[duration] as c4,[y.size()] as c5)
timeCost.append!(tmp)
}')
remoteRun(pubNodeHandler1,'insertTableToDatabase',y,StartTime)
}
ip = "xx.xx.xx.xx"
port = xxxx
compressMethod = "lz4"
subscribeTable(,`data,`pushData,0,pushData{ip,port,compressMethod},msgAsTable=true,batchSize=500000,throttle=1)To evaluate the performance of different synchronization schemes under varying data volumes, we progressively increased the amount of generated data and measured the corresponding resource usage. A summary of the results is shown below.
| Data Volume (rows × columns) | Elapsed Time (ms) | Avg. Sync Throughput (records/s) | CPU Usage (%) | Memory Usage (%) | Network Throughput (MB/s) |
|---|---|---|---|---|---|
| 4,800 | 60 | 80,000 | 103% | 0.6 | 0.04 |
| 240,000 | 1,883 | 127,456 | 120% | 0.7 | 1.22 |
| 1,920,000 | 14,384 | 133,482 | 140% | 1.1 | 9.5 |
| 14,400,000 | 108,529 | 132,683 | 140% | 1.7 | 10.1 |
As the volume of transmitted data increases, network bandwidth usage rises significantly, while memory and CPU usage show a moderate increase. Network throughput approaches the maximum bandwidth limit of the test environment. To further improve synchronization speed, more system resources and higher network bandwidth are required.
The test code above uses lz4 compression by default, and all reported performance results are based on this configuration.
To switch to Zstd compression, simply set the parameter compressMethod =
"zstd".
No Compression
This section mainly serves as a comparison against compressed transmission. Replace the sender-side code with the following to disable compression.
def pushDataNoCompress(ip,port,msg){
pubNodeHandler1=xdb(ip,port,`admin,123456)
StartTime=now()
remoteRun(pubNodeHandler1,'def insertTableToDatabase(y,StartTime){
pt=loadTable("dfs://Robot",`data)
pt.append!(y)
endTime=now()
duration=endTime-StartTime
tmp = table([0] as c1,[StartTime] as c2,[endTime] as c3,[duration] as c4,[y.size()] as c5)
timeCost.append!(tmp)
}')
remoteRun(pubNodeHandler1,'insertTableToDatabase',msg,StartTime)
}
ip = "xx.xx.xx.xx"
port = xxxx
subscribeTable(,`data,`pushData,0,pushDataNoCompress{ip,port},msgAsTable=true,batchSize=500000,throttle=1)Appendix 3: Complete Test Script
Full test scripts for the cloud-edge data synchronization solution: Cloud-Edge Data Synchronization.zip