About DolphinDB
Welcome to DolphinDB documentation!
DolphinDB is a real-time platform for analytics and stream processing, powered by a high-performance time series database. It offers capabilities related to efficient writes, fast queries, complex analysis, distributed parallel computing, and low-latency stream computing. It also supports high availability.
The following figure illustrates the architecture of the DolphinDB system:
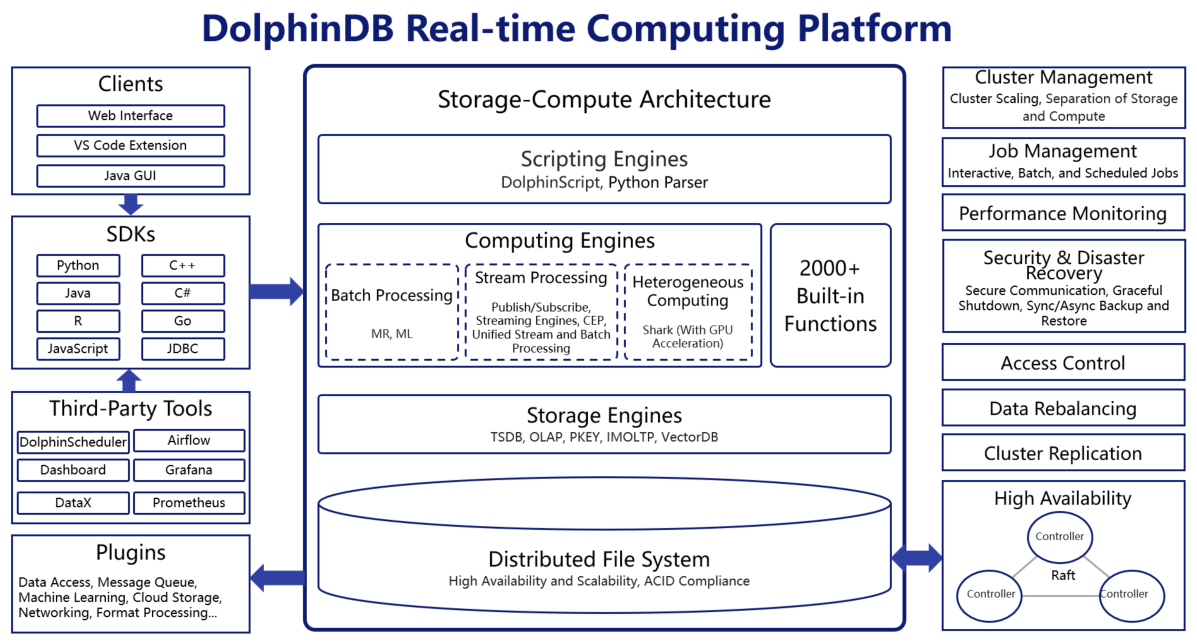
Distributed Architecture
- Distributed File System: Data is logically distributed across data nodes, with a controller managing all chunk metadata, including chunk and replica information, chunk version numbers, etc. This distributed system simplifies data management and enhances fault tolerance and scalability to ensure high data availability and continuous execution of computing tasks.
- Various Scaling Options: A DolphinDB cluster can be scaled online and offline by adding/removing more nodes or increasing/decreasing resources for a single node. DolphinDB also provides seamless and efficient data migration and rebalancing to ensure the even distribution of chunk replicas across a cluster after scaling.
- Distributed Transaction: DolphinDB guarantees ACID (atomicity, consistency, isolation, and durability) and supports snapshot isolation.
- High Availability: To maintain stable service and business continuity against single-node failure, DolphinDB offers high availability solutions for controllers, data nodes, and clients.
- Comprehensive Backup and Recovery: The backup and recovery mechanism is flexible and can be tailored to specific needs, ensuring data security.
- Cluster Replication: With low latency, high throughput, and high fault tolerance, this solution enables asynchronous data replication across clusters, enhancing datasecurity.
Storage
- DolphinDB supports various storage engines, including TSDB, OLAP, PKEY, IMOLTP, and
VectorDB, each tailored for different application scenarios:
- TSDB: Utilizes the PAX model for row-column hybrid storage, delivering significant performance for point queries.
- OLAP: Utilizes columnar storage, which is more suitable for aggregate computations over long time spans.
- PKEY: Ensures uniqueness of primary key and supports real-time updates and efficient queries. The PKEY engine is specifically engineered to seamlessly integrate with OLTP (Online Transaction Processing) systems based on CDC (change data capture).
- IMOLTP: Organizes the in-memory data in rows, supports transactions, and handles high-frequency, high-concurrency updates and queries using B+ tree indexing.
- VECTORDB: Supports vector indexing and enables fast approximate nearest neighbor searches (ANNS), catering to large-scale vector data retrieval and response needs.
- Supports various lossless data compression algorithms, including LZ4, Delta-of-delta, Zstandard, Chimp, and dictionary compression, with a compression ratio of 4:1 to 10:1.
- Supports tiered storage, which stores hot and cold data in different ways to reduce storage costs.
Batch Processing
- Rich Function Library: DolphinDB boasts over 2,000 built-in functions across various domains, covering a wide range of data processing needs. It also supports user-defined functions, helping users tackle complex application scenarios.
- Diverse Computing Models: DolphinDB’s distributed framework integrates a variety of computing models, including pipeline, Map-Reduce, and iterative computing.
- Multi-Diagram Programming: DolphinDB seamlessly combines SQL with functions and expressions to support complex data analysis directly within the database, significantly improving data processing speed and efficiency.
-
Vectorized Programming: Vectorization converts loops into parallel operations, processing multiple data elements simultaneously through single CPU instructions. This is particularly suitable for time-series data represented with a vector, reducing the cost of script interpreting and optimizing numerous algorithms.
- Multi-Machine and Multi-Core CPU Resources: DolphinDB fully utilizes the CPU resources and achieves efficient parallel processing of massive data.
Stream Processing
- DolphinDB supports publishing and subscribing to stream tables.
- Streaming Engines: DolphinDB integrates various streaming engines and built-in functions/operators for complex business needs. Powerful streaming pipelines can be built manually by calling these engines or automatically by using the streamEngineParser.
- Historical Data Replay: DolphinDB’s replay functionality allows simulating real-time data flows by replaying multiple data streams into a single synchronized timeline, which is essentially a way to backtest how trading strategies would have performed under past conditions.
- Unified Stream and Batch Processing: Factors or functions written in batch processing of historical data can be used for real-time calculation in production, ensuring that the results of stream calculations are completely consistent with those of batch calculations. This feature not only greatly facilitates testing, validation, and retrospective analysis for users, but also significantly reduces the development costs of factor implementation.
- Real-Time Data Ingestion: DolphinDB supports the ingestion of real-time streaming data from various sources, with automatic format conversion of the data.
- Complex Event Processing (CEP) Engine: DolphinDB’s CEP engine enables users to capture specific events from the received real-time data streams and perform predefined actions on the events.
- Sub-Millisecond Latency: DolphinDB boasts sub-millisecond data latency, ensuring optimal performance for real-time data processing.
Multi-Paradigm Programming
- Turing-Complete Programming Language: DolphinDB supports multi-paradigm programming including imperative programming, functional programming, vector programming, and SQL programming. With concise syntax, flexible usage, and strong expressiveness, it contributes to a leap in development efficiency.
- Support for SQL-92 Standard: DolphinDB further extends
the SQL-92 syntax with additional features, such as
cgroup by(for cumulative grouping calculations) andpivot by(for column/table rearrangement). It is also compatible with mainstream SQL databases such as Oracle and MySQL. - Python Parser: As an interpreter for Python language, DolphinDB Python Parser supports some native Python objects (e.g., dict, list, tuple, set), syntax, and functionalities of the pandas library. Users can directly use Python syntax in DolphinDB clients to access and manipulate DolphinDB data.
Comprehensive Ecosystem
- Rich SDK and Client Ecosystem: DolphinDB offers a wide range of APIs in different programming languages (e.g., Python, C++, Java, C#, R, JavaScript, etc.) and clients (e.g., Web Interface, VS Code Extension, Java GUI, DolphinDB terminal, etc.).
- Various Plugins: DolphinDB supports plugins across different fields, covering data access, financial scenarios, message queues, numerical computing, machine learning, networking, cloud storage, format conversion, etc.
- Modular Design: DolphinDB provides various modules, including technical analysis indicator library, ops, trading calendar, and WorldQuant 101 alphas. It also enables users to save user-defined functions as reusable modules to simplify the scripts for function calling and optimize system maintenance efficiency.
- Third-Party Tools: DolphinDB integrates third-party tools such as Grafana to connect various solutions for data transfer and visualization.