Primary Key Storage Engine
DolphinDB version 3.00.1 introduces a brand new storage engine - Primary Key Engine (PKEY) - designed to store data with unique identifier to each record within a table. This enhancement results in faster sorting, searching, and querying operations.
Design Considerations
- Data integrity and consistency: Preserves the primary key constraint of the source OLTP system.
- Near real-time data manipulation: Enables swift handling of updates, insertions, and deletions on a per row basis to managing write-heavy workloads typically associated with transactional databases.
- Flexible ad hoc queries: Supports on-the-fly queries.
- The OLAP storage plan faces challenges with real-time writes, as rewriting data files is necessary for each write operation.
- The TSDB storage plan presents challenges for data query, particularly with dynamic ad hoc queries that may require multiple index types, due to: (1) expensive deduplication costs; (2) inability to utilize indexes for non-primary key column.
Popular Strategies
The following approaches are commonly considered for handling data updates and queries.
Copy-on-Write
- Pros: This method excels in query performance and simplifies primary key uniqueness management during queries.
- Cons: It's less suitable for frequent update scenarios due to the costly process of rewriting the data file with each write operation.
- Examples of systems using this approach include Hudi, Delta Lake, and DolphinDB's OLAP engine.
Merge-on-Read
- Pros: This approach offers superior write performance and is well-suited for frequent write scenarios, as it doesn't strictly enforce uniqueness during writes.
- Cons: It has limitations in query performance optimization, as queries must read and merge new files for deduplication. Additionally, it restricts the ability to filter data using non-primary key column indexes.
- Examples of systems using this approach include ClickHouse, StarRocks Unique Key table, and DolphinDB's TSDB engine (keepDuplicates=LAST).
Merge-on-Write
- Pros: This strategy ensures that only the latest record among the records with the same primary key value needs to be read during queries, which eliminates the need to merge multiple versions of data files. Moreover, predicates and indexes can be pushed down to the underlying data, which greatly improves query performance.
- Cons: The need to update the delete bitmap for each file introduces some overhead, potentially impacting write performance.
- Examples of systems using this approach include Hologres, ByteHouse, Doris Unique Model, StarRocks Primary Key table.
Solutions for the PKEY Engine
Considering the scenario for streaming data in real time from transaction processing systems into DolphinDB, the constraints of the TSDB and OLAP solutions highlight the need for a solution that can create a trade-off between excellent query performance and the ability to handle high-frequency, real-time write operations effectively.
To address these challenges, the PKEY storage engine implements two key design principles: LSM Tree Architecture + Merge-on-Write.
This design enables real-time data inserts and updates through sequential writing, significantly enhancing write performance. It completes all data deduplication work during the data write phase, thus providing excellent query performance.
Storage Structure
The PKEY engine shares similarities with the TSDB engine, which is developed based on LSM Tree, utilizing a column-oriented storage structure. In PKEY databases, both the Immutable MemTable and level files sort data based on the primary key. A key distinction lies in how data updates and deletes are performed: The PKEY engine writes a delete bitmap file (see File Structure for details) that tracks the position in that file of records to be deleted.
The following figure illustrates the storage structure of the PKEY database.
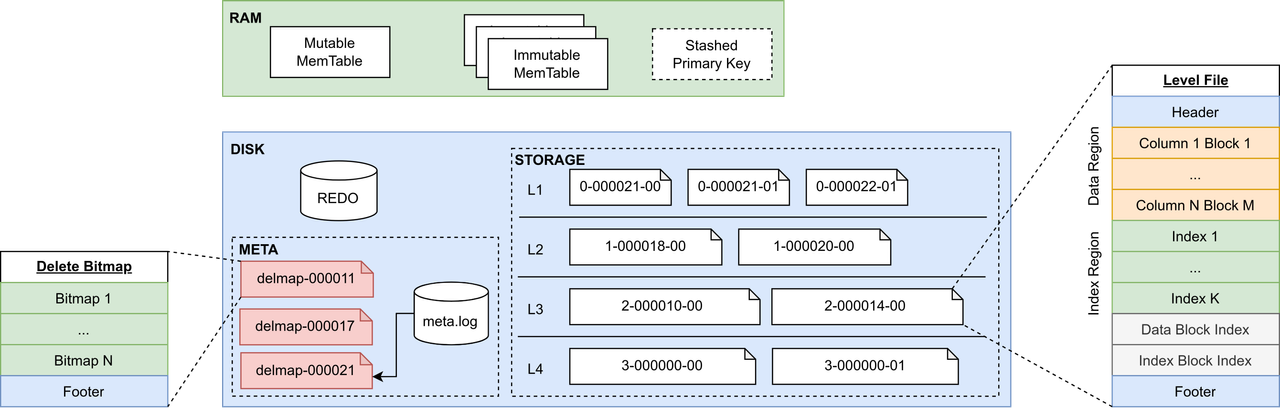
The storage structure of PKEY database consists of the following components:
- MemTable (Cache Engine): Two types of memory tables are
maintained:
- Mutable MemTable: Receives newly written data.
- Immutable MemTable: When the Mutable MemTable reaches its capacity, its data is sorted by the primary key and converted into an Immutable MemTable.
- Stashed Primary Key Buffer: A double-buffer design is adopted during the disk flushing process. It temporarily stores two key pieces of information: (1) the primary key and (2) the CID (commit ID) column of the data. It enables background updates of delete bitmap and facilitates deduplication during query.
- REDO: Logs transactions to ensure atomicity and durability. Write operations first record data in the redo log before inserting it into the MemTable.
- META: Contains storage engine metadata, including meta.log for meta information and multi-version delete bitmap files.
- STORAGE: Houses the data of the storage engine, organized into four levels. Each level contains multiple level files. Records within a level file are sorted by their primary key.
File Structure
Level File
- Level 0-2: Multiple level files may have overlapping primary key ranges.
- Level 3: Ranges of primary keys of level files never overlap.
This approach is designed to minimize read amplification (i.e., the number of disk reads per query) and space amplification (i.e., the ratio of the size of data files on disk to data size in the database) at level 3, optimizing query performance and storage efficiency.
Level File Name
- level ID: Indicates the level of the file (starting from 0).
- flush ID: Represents the most recent flushing operation that contributed data to this file.
- sequence number: Denotes the file's position (starting from 0) within its sorted run. A sorted run consists of one or multiple level files and each level file belongs to exactly one sorted run. Within a sorted run, ranges of primary keys of level files never overlap.
For example, a file named "1-000000014-001" indicates that this file is on the Level 1 (the second level), containing data from flush operation 14, and it is the second file in its sorted run.
Level File Structure
The structure of level files in a PKEY database is composed of six main components. See the following figure.

- Header: Contains file metadata, including maximum and minimum CIDs, column type info, and primary key column details.
- Data Block: Stores data, which is sorted by primary key both within and between blocks. Each block can hold up to 8192 rows.
- Index Block: Supports two index types: Bloomfilter and ZoneMap.
- Data Block Index: Stores information of data blocks, including column number, file offsets, and row counts.
- Index Block Index: Stores information of index blocks, including index type, column number, and file offsets.
- Footer: Stores the file offsets for the Data Block Index and Index Block Index.
For optimal file access efficiency, all six components are aligned to a 4 KB boundary.
Delete Bitmap File
The PKEY storage engine employs the delete bitmap to track data deletions and overwrites across its level files. Each delete bitmap is approximately 120KB in size, which enables storing deletion markers for up to 1 million rows of data. Therefore, one delete bitmap file is sufficient to store the deletion status for all level files in a partition.
The following figure illustrates a delete bitmap file structure.
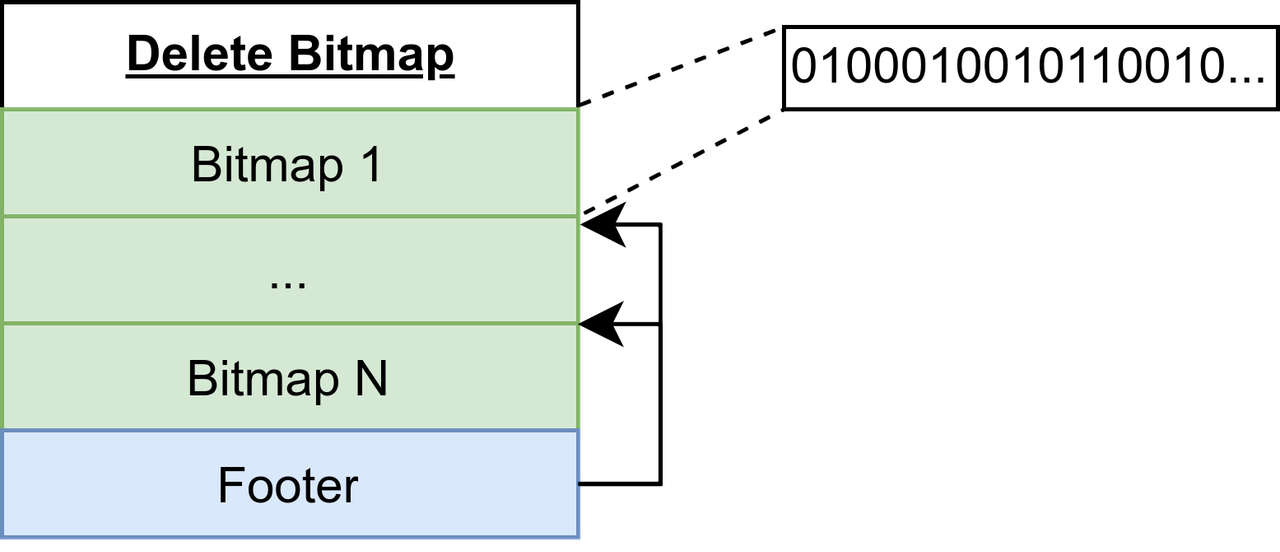
- Bitmap: Stores the delete bitmap for each level file within the partition, indicating whether the row has been deleted or overwritten. If a row is deleted, mark the row as 1. Each bitmap consists of a binary sequence. For example, the Bitmap 1 in the above figure indicates that the 2nd, 6th, 9th, 11th, 12th and 15th rows of the corresponding level file have been marked as deleted or overwritten.
- Footer: Stores the information of corresponding level files, including file offset, level ID, flush ID, and sequence number.
Multi-Version Delete Bitmap Files
The delete bitmap file is stored in multiple versions to avoid conflicts between query and write processes. Delete bitmap files are named with the flush ID. For example, a file named "delmap-000000014" is the delete bitmap for level files containing the updated data with flush ID 14. Each delete bitmap file will take the version with the latest flush ID as the snapshot. The meta.log file tracks the latest flush ID for delete bitmaps in each partition, which enables queries to retrieve the most recent delete bitmap version from the metadata for accurate data deduplication.
Read and Write Operations
The following figure demonstrates the workflow of read and write operations in a PKEY database.
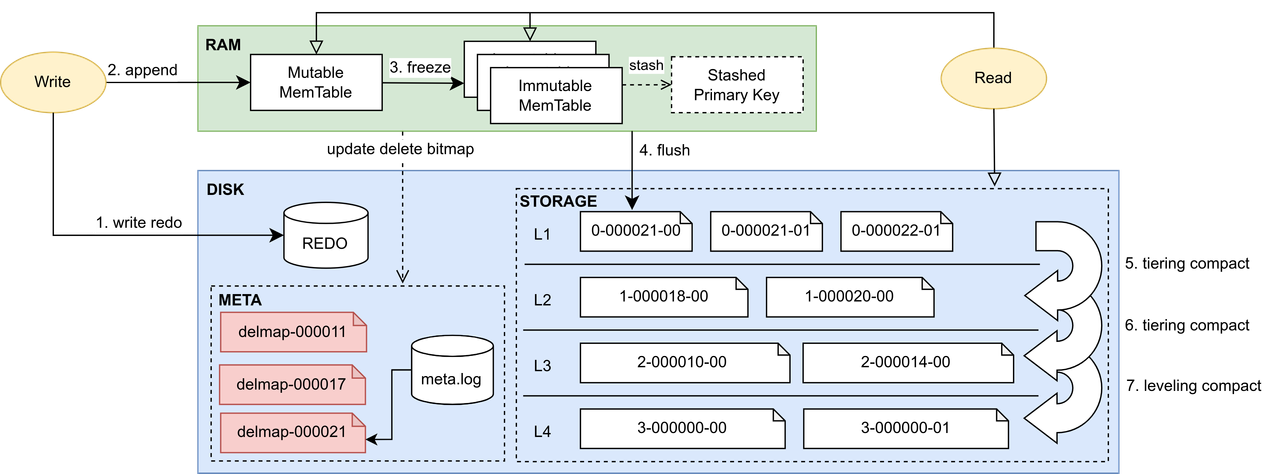
Writing Data
- Recorded in the redo log: To ensure atomicity and durability.
- Cached in the memory (cache engine): After the redo log is
successfully written, the data moves to the cache engine, which involves
two steps:
- Data is first cached to the Mutable MemTable.
- Once the Mutable MemTable reaches 8MB, the records are sorted by primary key and it is converted to an Immutable MemTable.
- Flushed to disk: When the cache engine's data volume reaches the predefined PKEYCacheEngineSize, the PKEY engine initiates a flush operation. This process writes all in-memory data to disk, creating the first level of storage.
- Background delete bitmap update: During data flushing (step 3),
the system extracts and temporarily stores the primary key and CID of
the data in the Stashed Primary Key buffer, based on which the
delete bitmap will be updated asynchronously in batches as a background
operation. Depending on the number and size of files, updating one batch
of the delete bitmap usually takes longer than a single flushing of
data. In order to mark as many deleted or overwritten rows as possible
in a delete bitmap update, the system will check whether the size of
Stashed Primary Key reaches PKEYDeleteBitmapUpdateThreshold to
trigger the update of delete bitmap. The delete bitmap update follows
these steps:
- Uses each file's ZoneMap to determine which data blocks require merging.
- Uses binary search to check and update the delete bitmap. For rows with identical primary keys, the row with the lower CID on disk is marked as deleted.
- Writes updated delete bitmaps for all files into a single delete bitmap file, naming it with the most recent flush ID.
- Background Compaction: After each flushing and compaction
operation, a background thread evaluates the need for level file
compaction based on specific trigger conditions. If compaction is
required, it proceeds according to a predetermined file selection
strategy.
- Trigger condition: Checks if (1) the amount of data, or (2) the percentage of deleted or overwritten rows in each level exceeds the threshold. When multiple levels meet the condition, a scoring system is applied to determine which level has priority for compaction.
- File selection policy: Once a level is chosen for compaction, the system selects files within that level: Starting from the oldest file, the system identifies overlapping sorted runs and calculates a score for each potential set of files to compact. If the trigger condition is the amount of data, files with the most sorted runs are favored. If the trigger condition is the ratio of deleted rows, files with the most deleted rows are prioritized.
Reading Data
- In-Memory Data Access: Initially retrieves required columns from the cache engine. For primary key-based point queries, it employs a binary search across each MemTable.
- Metadata Snapshot Retrieval: The latest versions of level file info, and delete bitmaps are fetched from the metadata.
- Disk Data Extraction: This phase involves multi-level filtering
using various indexes to create a bitmap for each file, identifying
relevant data blocks:
- Bloomfilter: For point queries or exact-match queries on Bloomfilter-indexed columns, a file-level bloom filter screens each level file to identify potential result-containing files.
- ZoneMap: For exact-match or range queries, block-level filtering is conducted on each level file to pinpoint qualifying blocks.
- Delete Bitmap: Following initial filtering, the file's delete bitmap is cross-referenced with the row number bitmap to exclude deleted and overwritten rows.
- Predicate Evaluation: The predicate pushdown is performed.
- Result Deduplication: Query results undergo a deduplication process, considering both the cache engine data and the stashed primary keys in memory. If both the cache engine and stashed primary key are empty, this step is skipped.
- Result Delivery: After filtering and deduplication, the system returns the final query result to the user.
Updating Data
- Query Phase: The system executes a query based on the given predicate conditions to locate the specific data that needs updating.
- Modification Phase: Once the relevant data is retrieved, the system updates the records and corresponding delete bitmaps.
- Write Phase: The updated data is then inserted into the database following the standard write process of the PKEY engine.
Deleting Data
- Query Phase: The system executes a query based on the given predicate conditions to locate the specific data that needs deleting.
- Write Phase: Then marks the data as deleted in delete bitmap. The corresponding CID will be updated as a negative number as a delete marker.
Features of the PKEY Engine
- Primary key integrity: Ensures uniqueness of primary keys while supporting near real-time updates.
- Efficient point queries: Excels in queries using primary key columns with predicate conditions, delivering high-speed retrievals.
- Multiple indexing for range queries:
- Bloomfilter: Facilitates file-level filtering, ideal for point queries on high-cardinality columns.
- ZoneMap: Enables block-level data filtering, particularly effective for time-related column queries.
- Competitive Write Performance: At moderate data throughput levels, the write performance of PKEY engine is comparable to TSDB engine. Note: As throughput increases, write time grows more rapidly compared to TSDB engine.
Configuration Options
- PKEYRedoLogDir and PKEYMetaLogDir: Paths where the PKEY meta log files and redo log files will be stored. To improve write performance, it is recommended to configure the path to SSDs.
- PKEYCacheEngineSize: The capacity (in GB) of the PKEY cache engine. The default value is 1. For scenarios with large write volumes, setting it higher can improve write performance. Conversely, in situations where query performance is critical, a lower value might be more appropriate.
- PKEYBlockCacheSize: The capacity (in GB) of the PKEY block cache. The default value is 1. Setting it higher for optimal query performance.
- PKEYDeleteBitmapUpdateThreshold: The buffer size threshold (in MB)
for updating the PKEY delete bitmap. The default value is 100.
- If set too small, the delete bitmap will be updated too frequently, consuming excessive disk bandwidth. This can negatively impact queries, cache engine flushing, and level file compaction.
- If set too large, the deduplication process during queries becomes more resource-intensive, potentially increasing query time. The system recovery process after a reboot may be significantly slower.
- PKEYStashedPrimaryKeyBufferSize: The buffer size (in MB) for the stashed primary key. The default value is 1024. Under excessive write load, frequent disk flushing and delayed buffer clearing due to slow delete bitmap updates will result in the buffer to grow continuously. This parameter serves as a safeguard against potential OOM issues that could arise from an indefinitely growing staging buffer during periods of high write activity.
- PKEYBackgroundWorkerPerVolume: The size of worker pool for the PKEY level file compaction and delete bitmap updates on each volume. The default and minimum value is 1.
- PKEYCacheFlushWorkerNumPerVolume: The size of worker pool for the PKEY cache engine flushing on each volume. The default and minimum value is 1.
Usage Example
Creating a Database
Use the database function (with engine specified as "PKEY") to create a COMPO-partitioned PKEY database.
dbName="dfs://test_pkey"
db1 = database(, VALUE, 2020.01.01..2021.01.01)
db2 = database(, HASH, [SYMBOL, 100])
db = database(directory=dbName, partitionType=COMPO, partitionScheme=[db1, db2], engine="PKEY")Creating a Table
-
create with built-in functions
To create a partitioned table
createPartitionedTable(dbHandle, table, tableName, [partitionColumns], [compressMethods], [primaryKey], [indexes])To create a dimension table
createDimensionTable(dbHandle, table, tableName, [compressMethods], [primaryKey], [indexes]) -
create with SQL statement (only partitioned table is supported)
create table dbPath.tableName ( schema[columnDescription] ) [partitioned by partitionColumns], [primaryKey]For example, create a partitioned table within the PKEY database.
tbName = "pt1" colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT tbSchema = table(1:0, colName, colType) // create with built-in function db.createPartitionedTable(table=tbSchema, tableName=tbName, partitionColumns=`TradeDate`SecurityID, primaryKey=`SecurityID`TradeDate`TradeTime, indexes={"BuyNo": "bloomfilter"}) // create with SQL statement create table "dfs://test_pkey"."pt1"( SecurityID SYMBOL, TradeDate DATE, TradeTime TIME, TradePrice DOUBLE, TradeQty INT, TradeAmount DOUBLE, BuyNo INT [indexes="bloomfilter"], SellNo INT ) partitioned by TradeDate,SecurityID primaryKey=`SecurityID`TradeDate`TradeTime
Performance Tuning
This section introduces how to improve your read and write performance by properly setting the following parameters.
partitionColumns
partitionColumns defines the database's partitioning strategy, which directly impacts data distribution and access patterns.
- Avoid using continuously increasing IDs or unique IDs as partitioning columns, as this can lead to poor write performance due to constant creation of new partitions.
- Instead, choose partitioning columns that naturally group related data together, allowing for more localized write operations.
In this regard, you can adopt a custom solution for data partitioning based on user-defined rules to flexibly accommodate diverse partitioning requirements.
For instance, for data with a column in the format id_date_id (e.g.,
ax1ve_20240101_e37f6), you can partition by date using a user-defined function:
// Define a function to extract the date information
def myPartitionFunc(str,a,b) {
return temporalParse(substr(str, a, b),"yyyyMMdd")
}
// Use myPartitionFunc to process the data column
pt = db.createPartitionedTable(table=tb, tableName=`pt,
partitionColumns=["myPartitionFunc(DateId, 6, 8)","SecurityID"],
primaryKey=`SecurityID`DateId`TradeTime,
indexes={"BuyNo": "bloomfilter"})primaryKey
The primaryKey parameter defines the database's primary key columns and should contain all partitioning columns. For optimal performance, it's recommended to prioritize ordered columns such as timestamps or incrementing IDs. This enhances storage efficiency by grouping related data together and thus improves query performance.
indexes
The indexes parameter sets the index type for non-primary key columns.
Currently, only "bloomfilter" index type is available. Bloomfilter indexing excels in point queries on high-cardinality columns (e.g., ID card numbers, order numbers, foreign keys from upstreams).
Columns not specified in indexes default to ZoneMap indexing, which is particularly effective for range queries, especially on time-based columns. ZoneMap performance improves with more concentrated batches of written data, making it ideal for columns such as order time or event occurrence time.