Orca 声明式 DStream API 应用:实时计算日累计逐单资金流
流计算一直是 DolphinDB 产品的核心功能之一。借助功能丰富的流计算引擎和高性能的内置算子,DolphinDB 已在因子计算、交易监控等场景中,助力众多客户实现高性能实时计算的生产部署。随着业界对流计算的深入使用,企业对流数据产品提出了更高的要求。为此,DolphinDB 流计算功能模块不断演进,并在 3.00.3 版本中发布了企业级实时计算平台 Orca。Orca 在原有流计算产品的基础上,为用户提供了更简洁的编程 API、更清晰的任务管理、更智能的自动调度以及更可靠的高可用计算支持等。更详细的 Orca 介绍请参考:Orca 实时计算平台。
本文重点介绍 Orca 为流计算作业提供的声明式 API (Declarative Stream API,DStream API)。DStream API 为用户提供了更加简洁、抽象级别更高的接口设计。它以声明式编程范式为核心,允许用户通过描述“做什么”而非“如何做”的方式,来定义流数据的处理逻辑,从而降低流处理应用的开发门槛。这使得开发者无需关注实现细节,能够将注意力重心放在更加宏观的业务逻辑和需求上,也降低了代码维护和修改的成本。
本文将通过两个具体的金融场景案例介绍如何用 DStream API 构建流计算作业。首先,通过一个简单的入门案例,介绍 Orca 流计算作业的关键组成部分与编写流程。之后我们进一步展示如何使用 DStream API 实现更复杂的业务场景——实时日累计逐单资金流计算 。
本文全部脚本在 3.00.3 Linux 版本部署的 DolphinDB 集群计算组的计算节点中开发和运行。用户也可以在单节点环境快速试用 DStream API 。
1. DolphinDB 流计算编程接口
在进入后续章节的 DStream API 案例之前,我们将在本章先梳理一下 DolphinDB 流计算编程的几个抽象层级。本章主要面向已经使用过 3.00.3 以下旧版本的 DolphinDB 流计算框架的用户, 意在简单介绍 DStream API 和之前已有接口的关系。读者也可以跳过本章直接跟随后续章节学习 DStream API 的使用。

DolphinDB 的底层实现语言为 C++ ,这保证了其在实时计算等场景中的高性能。在上层, DolphinDB 通过脚本语言(DLang)暴露给用户抽象好的编程接口,用户可通过这些接口使用 DolphinDB 流计算框架。
在 3.00.3 版本以前,DolphinDB 流计算仅提供函数式的编程接口——Stream
API,用户通过函数调用(如streamTable、subscribeTable、createReactiveStateEngine
等)创建流数据表、创建订阅、创建引擎等,通过串联流数据表、订阅和引擎等模块以搭积木的方式完成流计算作业的构建。
在 3.00.3 版本开始,DolphinDB 流计算提供了进一步抽象的编程接口——DStream API。DStream API 屏蔽了底层并行调度、订阅关系、资源清理等复杂逻辑,用户通过链式编程可以更简洁地定义处理逻辑。底层系统会将用户定义的 DStream API 转换为 DolphinDB 的函数调用,并自动封装为可调度的流任务分发至各个节点执行。DStream API 接口列表见:Orca 相关函数。
以下为 DStream API 示例代码,在下一章中我们将对它进行拆解介绍。
g = createStreamGraph("quickStart")
g.source("trade",`securityID`tradeTime`tradePrice`tradeQty`tradeAmount`buyNo`sellNo, [SYMBOL,TIMESTAMP,DOUBLE,INT,DOUBLE,LONG,LONG])
.map(msg -> select * from msg where tradePrice!=0)
.reactiveStateEngine(
metrics = [<tradeTime>, <tmsum(tradeTime, iif(buyNo>sellNo, tradeQty, 0), 5m)\tmsum(tradeTime, tradeQty, 5m) as factor>],
keyColumn = ["SecurityID"])
.sink("resultTable")
g.submit()2. Orca 流计算作业代码剖析
本章介绍 Orca 流计算作业代码的基本组成部分。通过一个入门示例,帮助首次使用 DStream API 的用户快速上手。
2.1 基本组成部分
一个 Orca 流计算作业总是由以下五部分组成:
-
在数据目录(Catalog)下创建流图(Stream Graph)
-
指定或者创建数据源
-
定义数据转换逻辑
-
指定计算结果输出表
-
提交流图
提交流图后即正式提交了流计算作业到后台,默认从数据源中最早的一条记录开始消费。随着数据源中的记录源源不断地增长,数据转换也将持续进行下去,直到流图被销毁。
下面将以一个简单的例子来演示如何使用 Orca 声明式 DStream API 来进行流计算,选取的场景为实时计算过去 5 分钟主动成交量占比。
2.2 快速上手:过去 5 分钟主动成交量占比
在本例中,我们使用逐笔成交数据流作为输入,对每条记录进行实时响应,计算并输出过去5分钟的主动成交量占比这一高频因子。
因子计算逻辑
主动成交占比即主动成交量占总成交量的比例,其计算公式如下:

其中:
-
actVolumest 表示 t-window 时刻到 t 时刻区间内的主动成交量;指示函数 IbuyNo>selNo 的定义如下:
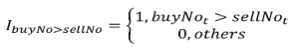
-
totalVolumet 表示 t-window 时刻到 t 时刻区间的总成交量。
输入数据示例
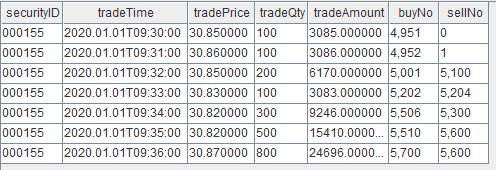
接下来,我们将使用 DStream API 逐步构建流计算作业。完整脚本见附录。
(1)在数据目录下创建流图
use catalog tutorial
g = createStreamGraph("quickStart")-
DolphinDB 支持数据目录(catalog),用于统一组织各类数据库对象,包括对分布式表的支持。在 Orca 中进一步扩展了 catalog 的应用范围,将流图、流数据表和流引擎也注册进 catalog 中,使用户能够通过一种统一的方式访问各类元素。
-
使用 DStream API 构建的计算流程被抽象为一个有向无环图,即流图(Stream Graph),其中每个节点代表一个流数据表或流计算引擎,每条边表示节点之间的数据传递关系。
-
createStreamGraph函数会新建一个流图。之后通过链式编程可以完善这个流图,从这个起点往后添加数据源节点、流计算引擎节点等即可完成流计算作业的定义。 -
一个流图用 <catalog>.orca_graph.<name> 进行唯一标识。建议每个用户或者项目使用各自的 catalog,这样不仅可以避免不同用户之间的流图命名冲突,也可以避免流图中的流数据表、引擎等命名冲突。
-
createStreamGraph 函数返回一个 StreamGraph 对象。
tutorial目录前,需要保证该目录已经存在。若不存在,可以先创建该目录:createCatalog("tutorial")(2)指定或创建数据源
sourceStream = g.source(
"trade_original",
`securityID`tradeTime`tradePrice`tradeQty`tradeAmount`buyNo`sellNo,
[SYMBOL,TIMESTAMP,DOUBLE,INT,DOUBLE,LONG,LONG]
)-
数据源(source 节点)本质上是一个流数据表,它是存储待进行转换的数据流的容器。本例中使用了 StreamGraph::source 方法新建了一个持久化共享流数据表,在本小节的最后我们将会模拟数据写入这张表,以触发本例的因子计算。
-
也可以通过 StreamGraph::sourceByName 方法指定一个系统中已有的流数据表为数据源,如sourceByName(marketData.orca_table.trade) 可以指定数据源为其他目录下的表。
-
StreamGraph::source 方法返回一个 DStream 对象。
(3)定义数据转换逻辑
transformedStream = sourceStream.map(msg -> select * from msg where tradePrice!=0)
.reactiveStateEngine(
metrics = [<tradeTime>, <tmsum(tradeTime, iif(buyNo>sellNo, tradeQty, 0), 5m)\tmsum(tradeTime, tradeQty, 5m) as factor>],
keyColumn = ["SecurityID"]
)-
DStream 对象代表了数据流。数据流可以通过 DStream::map 方法和各类引擎方法(DStream::reactiveStateEngine, DStream::timeSeriesEngine 等)进行数据转换,返回的结果是一个新的数据流。
-
DStream::map 方法主要用于定义无状态计算,如本例中筛选了价格列不为 0 的记录。
-
各类引擎方法适用于各种不同场景的有状态流式计算, 用户只需要简单配置引擎参数即可,其余的流式实现和状态管理等均由引擎底层实现。如 reactiveStateEngine 适用于本例的逐条响应计算并且计算结果依赖历史数据,后文中我们也将使用 dailyTimeSeriesEngine 对数据流进行窗口聚合、实现数据降频。
-
DStream::reactiveStateEngine 的 metrics 参数定义了因子计算的逻辑。其中的
tradeTime表示将输入的 tradeTime 列随计算结果一同输出,tmsum(tradeTime,iif(buyNo>sellNo, tradeQty, 0),5m)\tmsum(tradeTime, tradeQty, 5m)表示将计算得到的主动成交量占比作为计算结果列输出。 -
tmsum 是 DolphinDB 提供的内置函数,用于描述时序滑动窗口计算。tmsum 函数既可以在批计算(如 SQL 引擎)中使用,也可以在流计算(如响应式状态引擎)中使用,在流引擎中类似的内置函数都实现了增量计算优化。
(4)指定计算结果输出表
transformedStream.sink("resultTable")DStream::sink 方法指定了转换后的数据流写到哪张表里,既可以是持久化共享流数据表也可以是 DFS 库表。本例中,结果将被写到了名为
resultTable 的持久化共享流数据表中。这里在调用 sink 方法时包含了创建流数据表的操作,此外也接受指定
cacheSize等持久化流表参数。
(5)提交流图
g.submit()-
通过 g.submit() 语句提交流图。至此,我们提交了这个流计算作业。
-
当用户提交流图时,逻辑流图会转换成物理流图。转换的过程包括添加私有流数据表、优化、拆分并行度等。声明式 API 隐去了实现的细节。
-
在提交流图后,在 Web流图监控页面中可以点击流图名称查看各个流图的详情。
图 2. 图 2-1 流图列表 -
流图详情中包括物理流图可视化和流任务订阅线程状态等信息。物理流图中可以看到一个作业被拆成了多个流计算任务(task),并且任务被自动分配到不同的节点上运行。
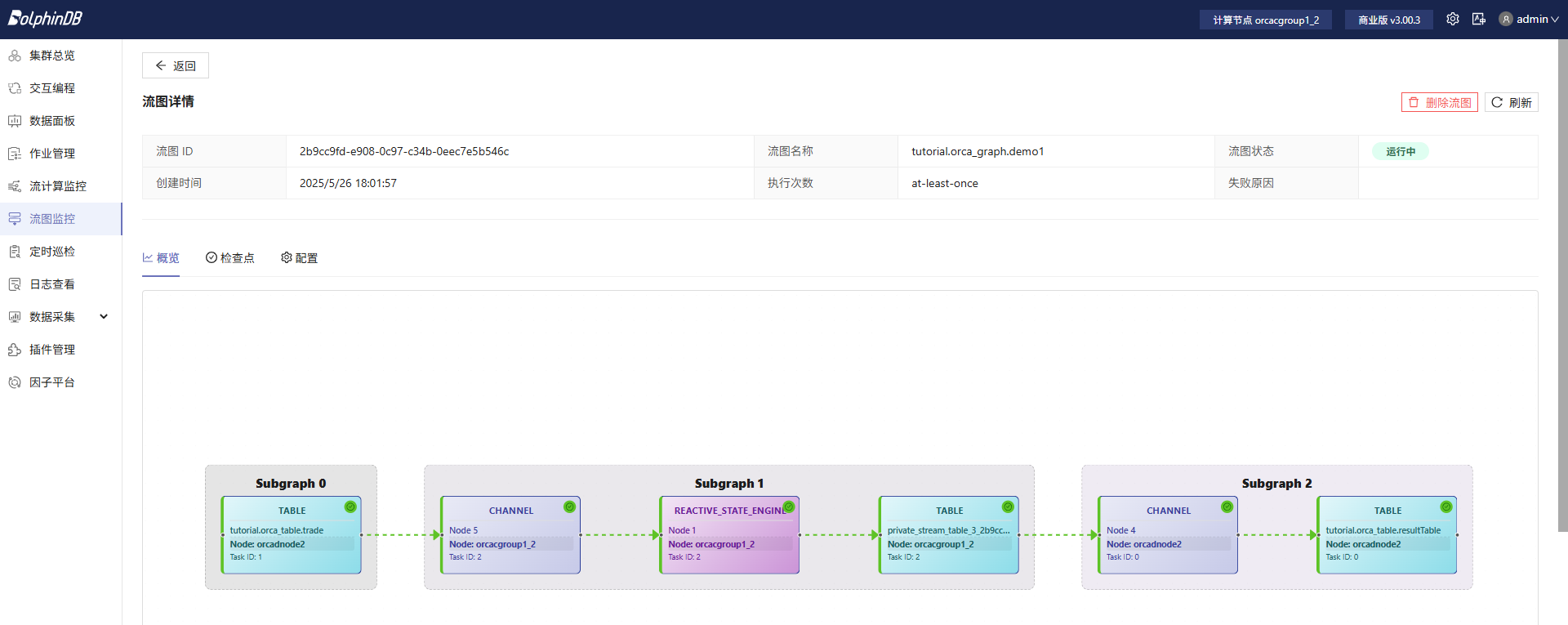
图 3. 图 2-2 物理流图
模拟数据注入数据源,观察输出结果
以下代码模拟了几条输入数据,并将其写入到 demo.orca_table.trade 表中。这会触发上文提交的流图计算并输出结果。
securityID = take(`000000, 7)
tradeTime = 2020.01.01T09:30:00.000 + 60000 * 0..6
tradePrice = [30.85, 30.86, 30.85, 30.83, 30.82, 30.82, 30.87]
tradeQty = [100, 100, 200, 100, 300, 500, 800]
tradeAmount = [3085, 3086, 6170, 3083, 9246, 15410, 24696]
buyNo = [4951, 4952, 5001, 5202, 5506, 5510, 5700]
sellNo = [0, 1, 5100, 5204, 5300, 5600, 5600]
data = table(securityID, tradeTime, tradePrice, tradeQty, tradeAmount, buyNo, sellNo)
appendOrcaStreamTable("tutorial.orca_table.trade_original", data)我们可以通过SQL语句查询结果表中的计算结果,结果如下:
select * from tutorial.orca_table.resultTable计算结果如下:
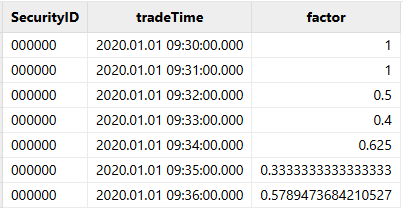
至此,我们使用 Orca 声明式 DStream API 完成了对因子的计算。下面将介绍一个更为复杂的实际业务场景,进一步展示 DStream API 的能力。
3. 应用案例:实时计算日累计逐单资金流
本章将给出 Orca 在实际业务场景的一个应用,即使用 Orca 声明式 DStreamAPI 进行日累计逐单资金流计算。相较于第二章中的快速上手示例,本场景计算逻辑更加复杂,并且回放真实数据作为数据源。本场景中给出的代码将展示如何通过 Dstream API 高效地实现引擎级联和并行计算逻辑。
对于本场景的传统 Stream API 实现可参考往期教程:。在本章的 3.4 小节将简单比较并总结 DStream API 的优越性。
3.1 场景描述

在 3.3 小节我们将通过 DStream API 链式调用实现以上计算逻辑。DStream API 实现的代码简洁清晰,代码结构与上图中的逻辑顺序完全一致。
3.2 数据源:逐笔成交数据
本章的资金流计算以逐笔成交数据流作为数据源, 在 DolphinDB 中存储的表结构如下(下表仅包含部分列):
| 列名 | 数据类型 | 注释 |
|---|---|---|
| SecurityID | SYMBOL | 股票代码 |
| TradeTime | TIMESTAMP | 交易时间 |
| TradePrice | DOUBLE | 交易价格 |
| TradeQty | INT | 成交量 |
| TradeMoney | DOUBLE | 成交额 |
| BidApplSeqNum | INT | 买单订单号 |
| OfferApplSeqNum | INT | 卖单订单号 |
为了方便用户跟随本文学习和实操,在附录中提供了包含两只标的的样例数据。通过附录中的导入脚本,可以完成建库建表并导入到库表中,用于后续的数据回放模拟数据流。注意修改导入脚本中的 filePath 为实际的 CSV 文件路径。若使用集群,需要在数据节点执行该脚本。
3.3 声明式 DStream API 实现
本小节将分步给出使用 DStream API 完成实时日累计逐单资金流的具体代码,完整代码见附录。建议读者首先阅读 2.2 小节的快速上手案例,了解 DStream API 的主要接口和代码结构。本小节更多专注于业务逻辑的实现。
(1)在数据目录下创建流图
use catalog tutorial
g = createStreamGraph("capitalFlow")在 turorial 目录下创建了另一个流图,用来构建实时计算资金流的流计算作业。
(2)指定或创建数据源
sourceStream = g.source(
"tradeOriginal",
`ChannelNo`ApplSeqNum`MDStreamID`BidApplSeqNum`OfferApplSeqNum`SecurityID`SecurityIDSource`TradePrice`TradeQty`ExecType`TradeDate`TradeTime`LocalTime`SeqNo`DataStatus`TradeMoney`TradeBSFlag`BizIndex`OrderKind`Market,
[INT, LONG, SYMBOL, LONG, LONG, SYMBOL, SYMBOL, DOUBLE, LONG, SYMBOL, DATE, TIME, TIME, LONG, INT, DOUBLE, SYMBOL, LONG, SYMBOL, SYMBOL]
)-
使用 StreamGraph::source 方法定义数据源,本例新建了一张持久化共享流数据表作为数据源。
-
后续我们将回放
loadTable("dfs://trade", "trade")库表中的数据到流数据表 tradeOriginal 中,因此两张表的字段含义和类型必须一一对应,字段名不要求必须一致。
(3)定义数据转换逻辑
根据 3.1 小节的计算逻辑,我们将使用三个响应式状态引擎(Reactive State Engine)依次计算按买单号聚合成交股数、按卖单号聚合成交股数和判断大小单并统计大小单指标,并将逐单的资金流计算结果写到流数据表中。
此外,本例还增加了一层对逐单资金流的降频处理,使用日级时序聚合引擎(Daily Time Series Engine)将逐单资金流降频为小时级别的数据。在实践中,这并不是必选的操作,此处主要是为了展示时序聚合引擎功能。
定义大小单标签函数
@state
def tagFunc(qty){
return iif(qty <= 20000, 0, iif(qty <= 200000, 1, 2))
}-
成交股数小于等于 2 万股的订单标记为小单,标签为 0 ;成交股数大于 2 万股、小于等于 20 万股的订单标记为中单,标签为 1 ;成交股数大于 20 万股的订单标记为大单,标签为 2 。
-
本例中,资金流大小单的判断条件基于成交股数,划分了大单、中单、小单三种,判断的边界值是随机定义的,开发者必须根据自己的实际场景进行调整。
-
该函数将在响应式状态引擎中使用,所以需要用 @state 表示函数是自定义的状态函数。
定义并行处理
parallel = 3
stream = sourceStream.parallelize("SecurityID", parallel)
/* ... transformations ... */
.sync()-
以上为定义并行处理的伪代码。
DStream::parallelize和DStream::sync接口必须同时调用。在两个接口之间的数据转换操作会被自动拆分成多个流计算子任务(Stream Task)并行进行。 -
本例中将逐笔成交数据流按证券代码(SecurityID)哈希分组,分发给 3 个流计算子任务,每个子任务都做相同计算逻辑的逐单资金流计算。
-
合理的并行度可以有效提升系统处理速度与吞吐量、降低时延。
定义买单合并逻辑
通过 DolphinDB 的响应式状态引擎和内置的cumsum,
prev函数实现流式增量计算。在各个分组内做累加计算,即按订单号合并订单总金额。
buyProcessing = sourceStream.parallelize("SecurityID", parallel)
.reactiveStateEngine(
metrics = [
<TradeTime>,
<OfferApplSeqNum>,
<TradeMoney>,
<TradeQty>,
<TradePrice>,
<cumsum(TradeMoney) as `TotalBuyAmount>,
<tagFunc(cumsum(TradeQty)) as `BuyOrderFlag>,
<prev(cumsum(TradeMoney)) as `prevTotalBuyAmount>,
<prev(tagFunc(cumsum(TradeQty))) as `prevBuyOrderFlag>
],
keyColumn = ["SecurityID", "BidApplSeqNum"]
)-
分组字段为
SecurityID和BidApplSeqNum,即股票代码和买单订单号。 -
<TradeTime>,<OfferApplSeqNum>,<TradeMoney>,<TradeQty>是无状态的计算,作用是保留原始表中这些字段的原始信息,输入给下一层的响应式状态引擎计算使用。 -
<cumsum(TradeMoney)>,<tagFunc(cumsum(TradeQty))>,<prev(cumsum(TradeMoney))>,<prev(tagFunc(cumsum(TradeQty)))>是有状态的计算,含义如下:-
<cumsum(TradeMoney)>计算了每一条成交记录所代表的股票按照此记录的买单订单号合并后的累计成交金额 -
<tagFunc(cumsum(TradeQty))>计算了当前这一条成交记录合入后根据累计成交量判断的大小单标签 -
<prev(cumsum(TradeMoney))>计算当前这一条成交记录合入前的累计成交金额 -
<prev(tagFunc(cumsum(TradeQty)))>计算当前这一条成交记录合入前根据累计成交量判断的大小单标签。
-
定义卖单合并逻辑
sellProcessing = buyProcessing
.reactiveStateEngine(
metrics = [
<TradeTime>,
<TradeMoney>,
<TradePrice>,
<cumsum(TradeMoney) as `TotalSellAmount>,
<tagFunc(cumsum(TradeQty)) as `SellOrderFlag>,
<prev(cumsum(TradeMoney)) as `PrevTotalSellAmount>,
<prev(tagFunc(cumsum(TradeQty))) as `PrevSellOrderFlag>,
<BidApplSeqNum>,
<TotalBuyAmount>,
<BuyOrderFlag>,
<PrevTotalBuyAmount>,
<PrevBuyOrderFlag>
],
keyColumn = ["SecurityID", "OfferApplSeqNum"]
)计算逻辑与买单基本相同,区别是保留了买单合并后的结果字段,分组字段为SecurityID和OfferApplSeqNum,即股票代码和卖单订单号。
定义大小单资金流指标聚合逻辑
capitalFlow = sellProcessing
.reactiveStateEngine(
metrics = [
<TradeTime>,
<TradePrice>,
<cumsum(TradeMoney) as TotalAmount>,
<dynamicGroupCumsum(TotalSellAmount, PrevTotalSellAmount, SellOrderFlag, PrevSellOrderFlag, 3) as `SellSmallAmount`SellMediumAmount`SellBigAmount>,
<dynamicGroupCumcount(SellOrderFlag, PrevSellOrderFlag, 3) as `SellSmallCount`SellMediumCount`SellBigCount>,
<dynamicGroupCumsum(TotalBuyAmount, PrevTotalBuyAmount, BuyOrderFlag, PrevBuyOrderFlag, 3) as `BuySmallAmount`BuyMediumAmount`BuyBigAmount>,
<dynamicGroupCumcount(BuyOrderFlag, PrevBuyOrderFlag, 3) as `BuySmallCount`BuyMediumCount`BuyBigCount>
],
keyColumn = "SecurityID"
)
.sync()-
通过 DolphinDB 的响应式状态引擎和内置的
cumsum,dynamicGroupCumsum,dynamicGroupCumcount函数实现流式增量计算,分组字段为SecurityID,即股票代码。 -
<TradeTime>是无状态的计算,作用是保留每一条计算结果的原始时间信息。 -
metrics 参数中其余元素都是有状态的计算
-
<cumsum(TradeAmount)>表示从开盘到当前记录,该只股票的总成交额。 -
dynamicGroupCumsum和dynamicGroupCumcount函数是专为大小单资金流这类场景设计的增量流式计算算子。面对大小单这样的动态分组、并按分组进行聚合计算的场景,dynamicGroup系列函数通过比较大小单标签(分组)的变化实现了增量计算。 -
以
为例,其输入是当前成交记录所代表的股票按照此记录的卖单订单号合并后的累计成交金额、当前成交记录合入前的累计成交金额、当前成交记录合入后根据累计成交量判断的大小单标签、当前成交记录合入前根据累计成交量判断的大小单标签、大小单标签数量,输出是表示从开盘到当前记录,该只股票的卖方向小单的总成交额、卖方向中单的总成交额、卖方向大单的总成交额。<dynamicGroupCumsum(TotalSellAmount, PrevTotalSellAmount, SellOrderFlag, PrevSellOrderFlag, 3)>
-
-
DStream::sync方法和前文的DStream::parallelize方法必须一起使用,划定了并行计算的子任务,至DStream::sync处多条并行分支汇合。
(4) 指定计算结果输出表
capitalFlow = capitalFlow.sink("capitalFlowStream")-
与 2.2 小节的代码基本相同,我们将计算结果输出到一张流表中。
-
在整个流计算作业中可以进行多次输出,本例中我们将在旁路输出逐单资金流 capitalFlowStream 表,此外基于它继续做数据转换。在后续的处理中,通过时序聚合引擎(time series engine)对逐单资金流进行了降频,每 60 分钟输出一条当前的资金流情况。
hourlyAggr = capitalFlow
.timeSeriesEngine(
windowSize = 60000*60,
step = 60000*60,
metrics = [
<last(TotalAmount)>,
<last(SellSmallAmount)>,
<last(SellMediumAmount)>,
<last(SellBigAmount)>,
<last(SellSmallCount)>,
<last(SellMediumCount)>,
<last(SellBigCount)>,
<last(BuySmallAmount)>,
<last(BuyMediumAmount)>,
<last(BuyBigAmount)>,
<last(BuySmallCount)>,
<last(BuyMediumCount)>,
<last(BuyBigCount)>
],
timeColumn = "TradeTime",
useSystemTime = false,
keyColumn = "SecurityID"
)
hourlyAggr.sink("capitalFlowStream60min")-
windowSize 和 step 指定了做 60 分钟滚动窗口计算。使用数据里的交易时间字段 TradeTime ,而非系统时间作为窗口划分的依据。
-
分组字段为
SecurityID,即股票代码,在每组内求每个指标的最新值(last 函数)。 -
实时计算的数据源为日累计资金流结果表 capitalFlowStream ,虽然该表的数据流量较大(和原始逐笔成交表的数据流量一样大),但是由于是做简单的60分钟滚动指标计算,所以只需要单线程处理,不需要使用并行流处理。
(5) 提交流图
g.submit()在提交流图后,在Web 流图监控界面里查看已经定义好的流图结构,如下图所示:
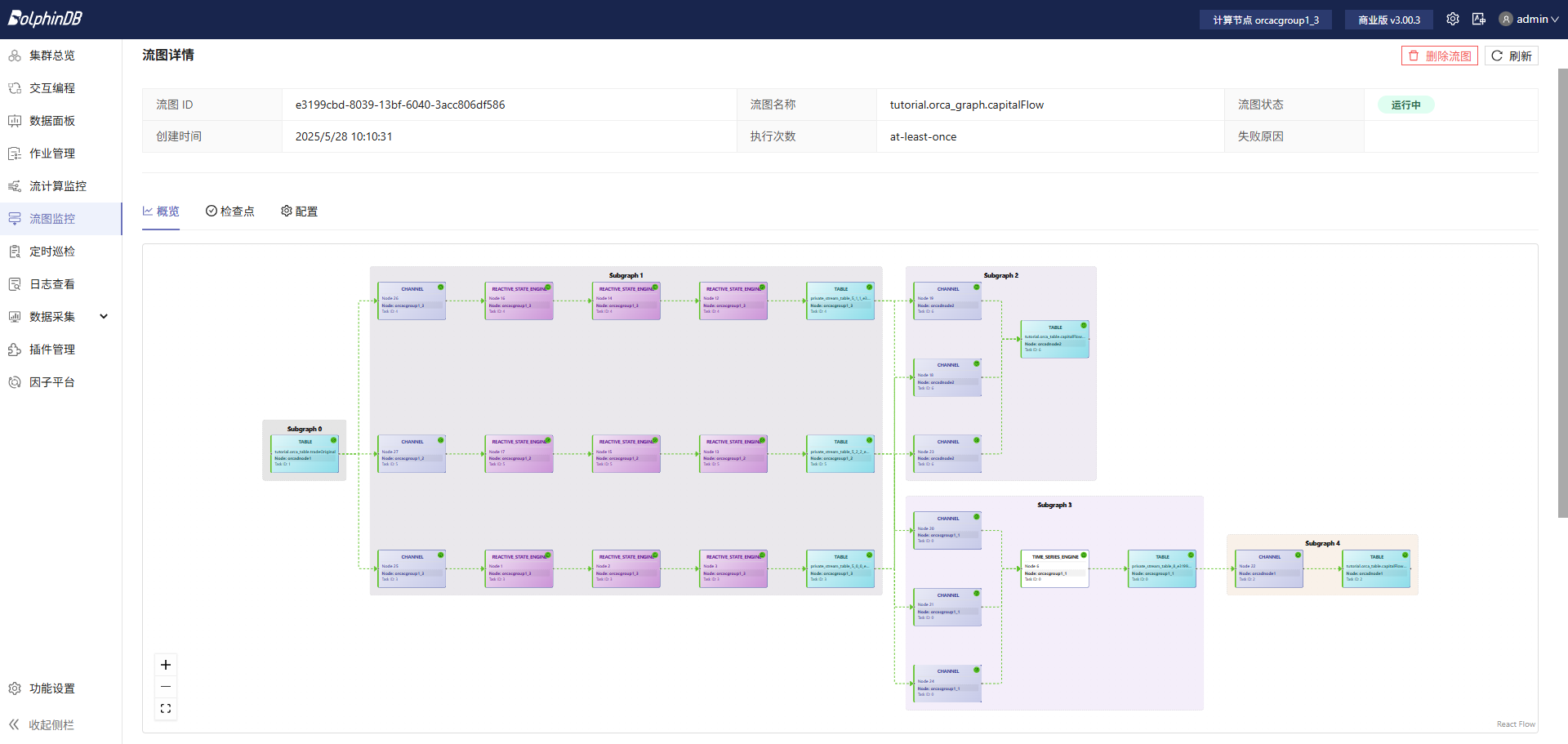
可以看到,资金流计算是一个多步骤级联的流式处理任务,Orca 会根据集群每个节点的负载,自动将子任务分配至相对空闲的节点,实现负载均衡。同时,集群模式也能提供流计算任务高可用功能,满足生产要求。
3.4 数据回放
useOrcaStreamTable("tutorial.orca_table.tradeOriginal", def (table) {
submitJob("replay", "replay", def (table) {
ds = replayDS(<select * from loadTable("dfs://trade", `trade) where TradeDate=2024.10.09>, datecolumn=`TradeDate)
replay(inputTables=ds, outputTables=table, dateColumn=`TradeTime, timeColumn=`TradeTime, replayRate=1, absoluteRate=false, preciseRate=true)
}, table)
})-
在 Orca 集群中,流数据表都存储在数据节点上。系统提供了 useOrcaStreamTable 函数,方便用户在计算节点上发起对数据节点上的流数据表的远程调用,如 replay 等。使用 useOrcaStreamTable 时, 用户不需要事先知道流数据表具体在哪个节点上。
-
在本例中,在 tradeOriginal 表所在的数据节点上,通过 submitjob 提交了一个后台回放任务。回放任务将存储在分布式表的数据注入到流数据表中,以模拟股票市场实时传入的数据。
3.5 Dashboard 可视化展示
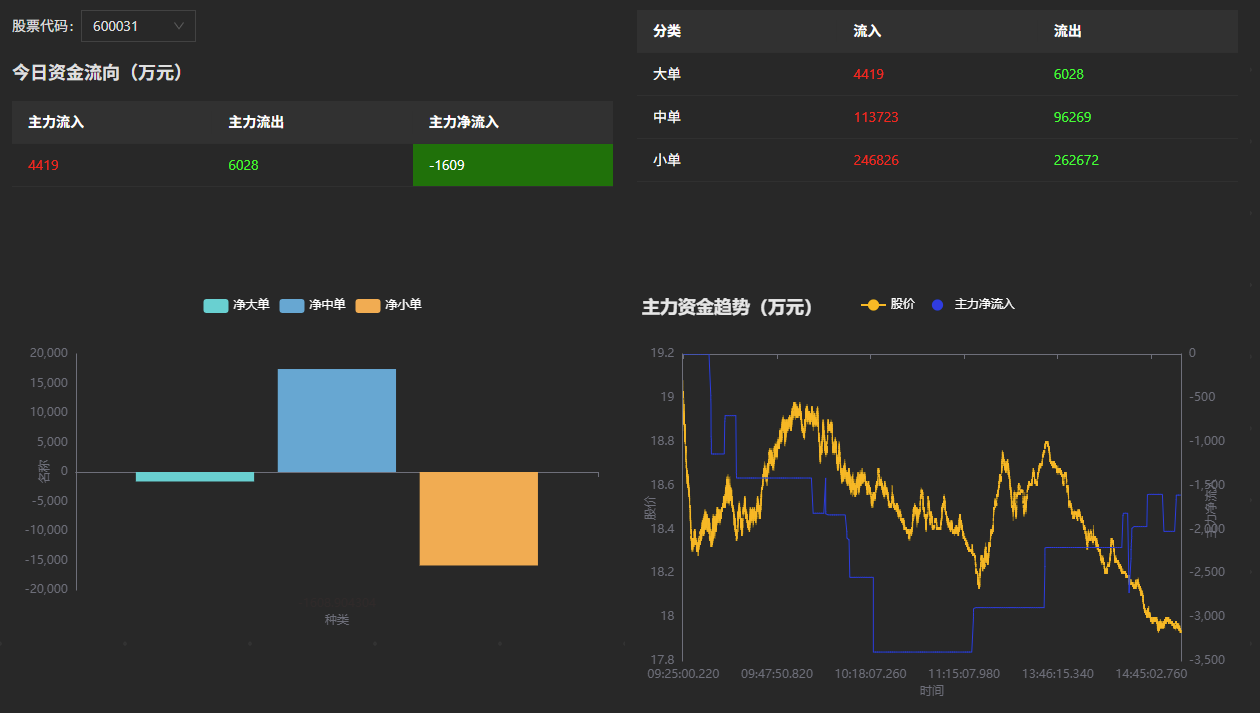
对于输出结果,除了使用 SQL 语句查看或者 API 订阅之外,DolphinDB 提供了另一种更加直观的数据结果展示方案——Dashboard。流计算作业提交后, DashBoard 将实时更新图表。具体使用方法可以参考官网教程:数据面板。
基于本文计算的资金流数据配置的数据面板效果如下,在附录中将给出对应的 json 配置文件:
3.6 DStream API 优势分析
回顾这一整章,对于使用过 DolphinDB 传统的 Stream API 的用户,可以很明显地感受到 Orca 声明式 DStream API 在易用性上的进步。DStream API 以链式编程风格,简化了流计算框架构建流程,使用户可以专注于业务逻辑的实现。主要优化如下:
开发更便捷
-
通过链式调用完成引擎级联等全部数据转换逻辑,更接近常规思维方式。各种转换得到的结果字段和字段类型自动推导,无需手动指定。这使得脚本开发中省去了大量繁琐的建表语句。
-
通过
DStream::sync方法和DStream::parallelize方法,快速定义并行计算。不再需要用户手动拆分多个作业并且指定消费线程。 -
接口高度抽象,使得用户不再需要共享会话机制、消费线程分配等底层细节
运维更便捷
-
引入了数据目录概念,能够清晰地管理不同用户、不同项目、不同资产类型的数据和作业。
-
引入了流图来描述一个完整的流计算作业,使得作业管理更便捷。在运维过程中,各个流计算作业边界清晰。此外,通过释放流图也可以快速地释放掉该作业涉及的流计算引擎、流数据表等资源。
-
作业管理更加可视化,web 页面提供了更完善的流计算作业(流图)管理页面。同时,作业中的引擎、流数据表、订阅、并行等复杂依赖关系在脚本提交后,便会自动生成 DAG 图并在Web 页面提供展示。
除了开发与运维效率上的提升外, Orca 也在自动调度、计算高可用等方面较之前版本做了进一步的增强。
4. 性能测试
本文通过原速回放 2024.10.09 当日 100 只上交所股票的逐笔数据,测试了对每条记录的的响应时延。并且比较了基于 Dstream API 和传统的 Stream API 实现的性能差异。
4.1 性能测试结果
我们对单次响应计算时间做了统计,单次响应计算时间定义为从第 1 个响应式状态引擎收到输入至第 3 个响应式状态引擎输出结果所经历的时间,这期间完成了买卖两个方向共 12 个指标的计算。对全天全部输出记录的响应时间取平均值作为本次性能测试结果。
| 解决方案 | 单次响应计算耗时 |
|---|---|
| Orca Dstream API | 0.238 ms |
| 传统 Stream API | 0.247 ms |
DStream API 在提供了高度抽象和简洁性的编程接口的前提下,计算性能与传统 Stream API 基本相同。依然保持着亚毫秒级的处理性能,这主要得益于 DolphinDB 的流计算引擎和增量算子。
4.2 测试环境配置
安装 DolphinDB server,配置为集群模式。本次测试所涉及到的硬件环境和软件环境如下:
-
硬件环境
硬件名称 配置信息 内核 3.10.0-1160.88.1.el7.x86_64 CPU Intel(R) Xeon(R) Gold 5220R CPU @ 2.20GHz 内存 16*32GB RDUNN, 3200MT/s 总共512GB -
软件环境
软件名称 版本及配置信息 操作系统 CentOS Linux 7 (Core) DolphinDB
server 版本:3.00.3 2025.05.15 LINUX x86_64 license 限制:16 核 512 GB 配置文件中测试节点最大可用内存:232 GB
5. 总结
本文通过两个层次的案例循序渐进地展示了 Orca 声明式 DStream API 的强大能力:
-
简洁性:开发者无需手动创建流数据表、引擎级联,可以专注于业务逻辑;
-
高抽象性:通过声明式接口隐藏系统实现细节;
Orca 提供的声明式流处理接口为 DolphinDB 在企业级实时计算中应用提供了强有力的支持。在后续版本中, Orca 将继续扩展 DStream API 算子,丰富其表达能力,以帮助用户应对各种复杂实时计算场景。
附录
- 样例数据:trade.csv
- 建库建表与样例数据导入脚本:CreateDB&LoadText.dos
- 快速上手:过去 5 分钟主动成交量占比脚本:QuickStart.dos
- 应用案例:实时日累计逐单资金流脚本:CapitalFlow.dos
- dashboard配置文件:dashboard.CapitalFlowTutorial.json