基于 DolphinDB 的 MES 实时数据处理与分析解决方案
本文聚焦制造执行系统(Manufacturing Execution System,MES)在海量工业数据场景下面临的实时处理与复杂分析需求,围绕 MES 核心业务场景、工业数据特征以及传统技术架构存在的处理瓶颈,提出一套基于 DolphinDB 的实时数据处理与分析解决方案。
方案基于 DolphinDB 高性能时序分析、多模态存储、流批一体计算及多源数据统一处理能力,构建覆盖数据接入、实时计算、质量追溯与历史分析的统一数据处理架构,在不替代现有 MES 系统的前提下,帮助企业构建面向未来的实时数据底座,并提升生产统计、设备分析及生产运营等场景下的数据处理效率与实时分析能力。
同时,本文结合实际制造业客户案例,展示 DolphinDB 在高并发、海量数据 MES 场景下的落地效果与性能价值。
1. 行业背景与发展趋势
在制造业数字化转型持续深化的当下,MES 正从“过程记录系统”向“实时运营决策中枢”演进。过去,MES 主要承担工单执行、工艺下发、报工采集、质量记录等基础职能;如今,企业更希望它能回答:“当前正在发生什么”,“接下来可能发生什么”。
尤其在汽车零部件、装备制造、电子装配、流程制造等行业中,产线自动化程度持续提升,可编程逻辑控制器(Programmable Logic Controller,PLC)、工位终端、测试设备、视觉检测、射频识别(Radio Frequency Identification,RFID)及数据采集与监视控制系统(Supervisory Control and Data Acquisition,SCADA)等系统源源不断地产生海量高频数据。面对多源异构、高频实时的数据环境,传统处理方式难以满足业务对实时分析与快速反馈的需求。现场并不缺乏数据,真正缺失的,是一套能够实时接入、高效处理、在线分析并反哺 MES 业务的能力体系。
在上述背景下,MES 数据处理正在呈现四大趋势:实时化、数据多样化、追溯精细化、系统协同化。传统关系型数据库与离线报表已难以支撑这些实时化诉求。MES 要真正成为制造现场的实时中枢,必须配备适合工业时序数据的处理与分析底座。DolphinDB 作为高性能分布式时序数据库,具备海量存储、流批一体与实时分析能力,是构建下一代 MES 实时数据底座的理想选择。
2. MES 核心业务场景与数据处理挑战
本章将结合 MES 的核心业务场景,分析制造业生产过程中的数据特征与处理需求,并进一步讨论传统技术架构在实时处理、统计分析及历史数据管理等方面面临的主要问题。
2.1 MES 核心业务场景
MES 的核心业务场景,本质上围绕生产过程管理、设备运行管理、质量管理及生产运营分析展开。
在生产过程管理场景中,MES 需要实时掌握生产进度、产量状态及生产节拍,实现生产过程透明化管理。
在设备运行管理场景中,MES 需要对设备状态、停机事件及报警信息进行统一监控与分析,通过设备综合效率(Overall Equipment Effectiveness,OEE)指标推动设备运行状态的持续优化。
在质量管理场景中,MES 需要基于产品、批次及工单信息,对生产过程、工艺参数及检测结果进行全过程追溯,实现质量问题快速定位与责任追踪。
在生产运营分析场景中,MES 需要对工单执行、产线效率、良率变化及生产异常进行长期分析,为生产调度、工艺优化及经营决策提供数据支撑。
2.2 MES 数据特征与处理需求
MES 场景中的数据通常同时具备数据来源复杂、写入频率高、时序特征明显、业务关联复杂以及历史数据长期持续积累等特点,针对这些特点对系统的数据接入、存储、实时计算与历史分析能力提出了较高要求。
在数据来源方面,MES 通常需要同时处理工单、产品等业务数据,PLC、SCADA 等产生的工业时序数据,以及 MQTT、Kafka 等流转的实时消息数据。不同数据在结构、频率及处理方式上差异明显,数据统一接入与管理难度较高。
在实时处理方面,设备状态、报警事件、工艺参数及检测结果等数据高频产生,而班次产量、设备状态及活动告警等关键指标又要求当班实时可见,形成典型的高频实时数据处理场景。
在统计分析方面,小时产量统计、停机时长分析等核心场景,都高度依赖时间窗口切分、状态识别及多维聚合。
在质量追溯方面,工艺参数、设备状态、报警记录及检测结果通常分散在不同业务系统与数据表中,需要基于产品序列号(Serial Number,SN)、批次号及工单号进行全过程关联。
在历史数据管理方面,制造业通常要求生产数据长期留存,以满足质量复盘、工艺优化及历史分析需求。
2.3 传统技术方案及其局限性
针对 MES 场景中的多源数据接入、实时统计分析、质量追溯及历史数据管理需求,传统方案通常采用“数据采集 + 关系型数据库 + ETL/中间处理 + MES 应用 + 报表分析”的组合架构。该类方案在项目初期能够较快落地,但随着数据规模增长和业务持续扩展,其局限性会逐渐显现。
在数据接入方面,传统方案通常通过采集程序、协议网关、消息中间件及 ETL 工具分别处理工业设备数据、业务数据及消息流数据。不同类型的数据往往分散在多个数据库、中间库及缓存系统中,导致系统间关联复杂、数据链路较长,后续统计分析往往需要跨系统进行数据关联与重复加工。
在实时处理方面,传统 MES 架构中的实时统计能力通常依赖 ETL、定时任务及中间结果表实现。设备状态、报警事件及工艺参数虽然持续实时产生,但很多班次统计、设备分析及报警汇总等结果仍需要经过离线汇总后才能查询使用,难以满足生产现场对实时数据分析与异常响应的需求。
在统计分析方面,传统关系型数据库通常采用复杂 SQL、窗口函数、中间结果表及多层嵌套查询实现小时产量统计、停机时长分析、报警汇总及工单加工时间计算等业务逻辑。当历史数据持续积累后,大量时间窗口聚合与多维关联分析会显著增加数据库查询开销,容易出现查询响应逐渐变慢的问题。
在质量追溯方面,工艺参数、设备状态、报警记录及检测结果等数据通常分散在不同业务系统及专题分析模块中,缺少统一的数据关联与查询能力。一旦发生质量异常,往往需要通过复杂 SQL、甚至将数据导出后借助离线脚本进行跨系统关联分析,问题定位效率较低。
在历史数据管理方面,传统关系型数据库在长期海量工业时序数据场景下,容易面临存储膨胀、索引维护压力增加及历史查询性能下降等问题。随着业务持续扩展,为满足日益复杂的统计分析需求,系统中会不断增加新的 ETL、中间结果表及专题统计模块,导致整体系统复杂度与维护成本持续上升,系统查询性能与实时分析能力也会逐渐成为制造企业 MES 升级过程中的核心瓶颈。
3. DolphinDB 行业解决方案
针对第 2 章所述的多源异构数据接入复杂、实时统计链路冗长、质量追溯跨系统关联困难及海量历史数据查询缓慢四大挑战,本章提出基于 DolphinDB 的统一工业数据底座方案。该方案从数据接入、存储、计算到系统协同四个层面进行能力重构,将原本分散的工具链与数据链路收敛至单一平台,重点解决 MES 在实时分析、质量追溯及长期历史管理场景下的性能瓶颈与架构复杂度问题。
3.1 方案总体设计
DolphinDB 在 MES 系统下建设一层面向制造场景的实时数据处理与分析底座,与 MES 形成"MES 管业务流程,DolphinDB 管实时数据"的协同模式。这一设计的核心思路是:将原本分散在采集程序、ETL 工具、关系型数据库、中间结果表及专题分析模块中的工业数据处理能力,统一收敛至单一平台,从根本上简化数据链路与系统架构,同时保留现有 MES 业务体系的稳定性与连续性。
基于这一底座,MES 核心统计与历史分析场景的查询性能可获得显著提升:复杂统计场景下性能提升可达数十倍以上,查询响应延迟由传统分钟级缩短至毫秒级。同时,系统架构得以简化,指标计算逻辑趋于统一,存储与运维成本亦明显降低。
围绕上述目标,本方案在以下四个层面进行能力重构:
数据接入层:告别多套工具,实现一站式接入
以单一平台替代原本需要采集程序、协议网关、消息中间件与 ETL 工具协同的多套工具链,从源头消除多系统之间的数据搬运与重复加工。
数据存储层:以多模态存储引擎替代传统行式存储
以多模态存储引擎替代关系型数据库、工业实时库、消息中间件及文件系统等多套组件的组合架构,对高频时序数据、业务维度数据及历史归档数据进行统一建模与管理。
数据计算层:实时与批量分离,分而治之
针对单一计算引擎难以兼顾实时性与大规模历史分析的固有矛盾,采用流批分离的分层设计——实时计算保障核心指标当班可见,批计算与历史分析在海量数据下仍保持毫秒级响应。
系统协同层:标准 API 协同
通过标准 API 与现有 MES 系统形成协同,将分散在 ETL、报表及中间表中的统计与分析逻辑统一收敛至单一平台,支持渐进式改造与平滑升级。
3.2 方案架构
基于前述设计思路,本节将 3.1 中的四层框架进一步细化为七层落地架构:接入层向下对接各类工业设备与业务系统数据源,将协同层具体化为服务层与接口层,向上对接现有 MES 应用体系,形成从数据产生到业务消费的完整链路。
3.2.1 整体架构概览
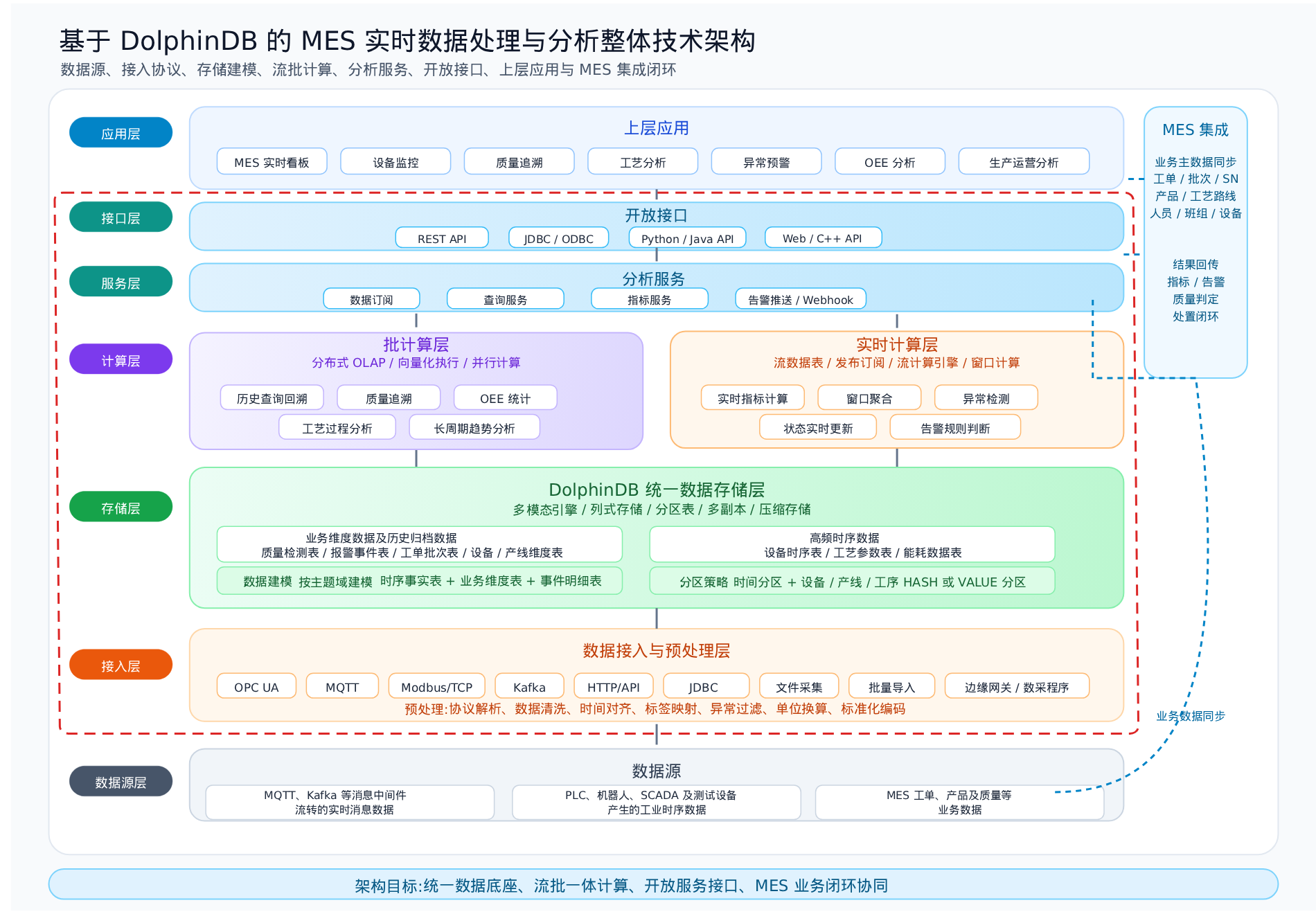
MES 整体架构说明
整体方案采用"数据源层—接入层—存储层—计算层—服务层—接口层—应用层"的七层架构。其中,数据源层与应用层为企业现有系统,DolphinDB 负责中间五层(接入层、存储层、计算层、服务层、接口层)的能力建设。
1)数据源层
负责产生现场工业实时数据与业务系统数据,主要包括 PLC、机器人、SCADA、测试设备等工业设备产生的时序数据,以及 MES、ERP、QMS 等业务系统中的工单、产品、质量等业务数据。同时支持 MQTT、Kafka 等消息中间件产生的实时流式数据,为上层分析提供统一数据来源。
2)数据接入层
负责多源异构工业数据的统一接入与标准化处理。DolphinDB 支持 Kafka、MQTT、OPC UA、TCPSocket、httpClient、API、JDBC、文件采集及边缘网关等多种工业协议与接入方式,实现设备数据、业务数据与消息流数据的统一汇聚。在接入过程中可同步完成协议解析、数据清洗、时间对齐、标签映射、异常过滤、单位换算、标准化编码等,从而降低传统 ETL 与中间缓存系统带来的架构复杂度。
3)存储层
基于 DolphinDB 多模态统一存储引擎,构建工业实时数据底座,对设备状态、工艺参数、能耗数据、报警事件、质量检测及工单批次等数据进行统一存储与分区管理。存储引擎结合实时过程数据、业务维度数据与事件明细数据,形成面向 MES 场景的统一工业数据模型,为实时计算与历史分析提供统一的数据基础。
4)计算分析层
基于 DolphinDB 流计算引擎与多模态存储引擎,分别支撑两类计算场景:流计算负责实时指标统计、窗口聚合与异常检测,实现核心数据秒级可见;批计算负责历史数据关联查询、多维聚合与复杂统计分析,满足大规模数据分析需求。
5)服务层
封装面向 MES 业务场景的统一数据服务,包括数据订阅、数据查询、指标计算及告警推送。将原本分散在 ETL、报表及中间表中的业务逻辑统一收敛,形成可复用的数据服务能力,避免各应用重复开发。
6)接口层
将服务层能力以标准化技术协议对外暴露,支持 Python/Java API、JDBC/ODBC 及 Web 接口等多种接入方式,满足 MES、ERP、QMS 及报表、移动端、第三方应用的对接需求。接口层屏蔽底层服务的实现细节,保证上下游系统在协议、格式与权限层面的标准化对接。
7)应用层
承载 MES 实时看板、设备监控、质量追溯、异常预警、OEE 分析、生产运营分析等具体业务应用。应用层基于服务层与接口层提供的统一数据能力,专注于业务逻辑呈现与现场交互,无需关心底层数据处理与存储细节。
3.2.2 数据接入与存储方案
针对 2.3 节所述的多源数据分散接入、链路冗长问题,DolphinDB 在接入与存储层提供一体化的数据汇聚与建模能力。
在数据接入层,数据接入过程中,DolphinDB 插件可同步完成协议解析、字段映射、时间对齐、异常值过滤、单位换算、标签标准化及数据清洗等处理,使原始工业数据在进入存储层前完成标准化,降低多系统维护与数据同步带来的复杂度,同时提升高频工业数据的实时写入、长期存储及历史分析能力。
在数据存储层,DolphinDB 基于多模态存储引擎,针对不同数据特征采用差异化建模策略:
-
高频时序数据(设备状态、工艺参数、能耗、报警事件、检测结果等):按时间、产线、设备、工位等维度进行分区设计,兼顾写入吞吐与查询效率。
-
业务维度数据(工单、产品、设备台账等):结合维度表与关系型数据模型进行管理,支撑后续多维关联分析。
两类数据在同一平台内完成建模与关联,MES 中原本分散在多个系统与中间表中的设备数据、生产数据和质量数据,可直接在平台内完成跨域查询与关联分析,企业无需在采集、存储、加工各环节维护多套异构组件,即可获得一套稳定的工业实时数据底座,为后续实时计算、质量追溯及历史趋势分析提供稳定的数据基础。
3.2.3 实时计算与数据分析方案
基于 DolphinDB 的流计算、向量化计算及多模态存储能力,平台能够在数据接入过程中同步完成实时指标计算,将原始设备流、事件流及过程数据直接转化为业务统计结果,减少传统多级处理链路。
平台可围绕班次产量、小时产量、合格(OK)/ 不合格(NG)数量、设备状态、停机时长、活动告警及关键工艺参数等核心指标,持续进行实时聚合、窗口计算与状态分析;同时结合时间分区裁剪、列式存储及向量化聚合能力,实现海量历史数据场景下的高性能统计分析与历史查询。
此外,平台还可将实时指标与分析逻辑以函数视图或标准接口方式统一沉淀,为 MES 看板、设备监控、报表系统及移动端应用提供统一的数据服务,避免传统模式下“每个页面单独统计、每个模块重复开发”的问题。
该方案的核心价值在于:通过统一的实时计算平台,实现核心生产指标的实时聚合与秒级响应,帮助企业提升生产监控、异常预警及运营分析的实时性。
3.2.4 质量追溯与历史分析方案
基于 DolphinDB 的多模态存储引擎,平台可将产品 SN、批次、工单、设备状态、工艺参数、报警事件及检测结果等数据统一汇聚,并基于时间主线建立全过程关联关系,实现生产全过程数据的统一留存与快速回溯。
依托分布式存储、时间分区裁剪及向量化分析能力,平台能够快速完成产品、批次及工单维度下的历史数据关联分析,实现从“结果”到“过程”的秒级追溯,支撑质量复盘、工艺优化、报警分析及长期趋势分析等典型场景。
相比传统依赖复杂 SQL、离线脚本及多系统导出的实现方式,DolphinDB 能够在统一平台内完成历史数据查询与全过程关联分析,降低跨系统数据处理复杂度,同时提升海量历史工业数据场景下的查询效率与分析能力。
该方案的核心价值在于:通过统一的全过程数据关联能力,实现生产数据、设备数据与质量数据的快速追溯与历史分析,帮助企业提升问题定位效率与质量分析能力。
3.2.5 MES 协同与数据服务方案
在本方案的整体架构中,DolphinDB 与现有 MES 系统形成“MES 管业务流程,DolphinDB 管实时数据”的协同模式。MES 继续负责工单执行、工艺管理、作业控制及业务闭环,而 DolphinDB 则统一承接高频工业数据接入、实时指标计算、质量追溯及历史分析等能力,实现数据处理与业务流程的解耦。
在系统协同层面,DolphinDB 可通过 Python/Java API、JDBC/ODBC 及 Web 接口等方式,对 MES 看板、设备监控、报表系统、移动端应用及周边业务系统提供统一的数据服务能力,避免传统模式下多个系统分别建设数据链路、重复加工数据的问题。
同时,平台支持渐进式改造方式。企业无需一次性重构现有 MES 架构,而是可以优先将实时看板、慢查询、报警分析、质量追溯等性能瓶颈场景逐步迁移至 DolphinDB 平台,在降低项目实施风险的同时,实现系统实时能力的持续升级。
相比传统分散式架构,该方案能够将原本分散在数据库、报表系统及中间处理程序中的统计与分析逻辑统一收敛至 DolphinDB 平台,降低系统复杂度与后续运维成本。
该方案的核心价值在于:在保留现有 MES 业务体系的基础上,逐步构建统一的数据服务与分析能力,实现系统实时能力的持续升级,并降低整体架构复杂度与运维成本。
3.3 适用场景
基于 DolphinDB 的 MES 实时数据处理与分析方案,适用于汽车及零部件制造、电子与半导体制造、装备制造(离散制造)、流程制造(化工/能源)、智能工厂/工业 4.0 等制造型企业,尤其适合存在海量工业时序数据、高频设备数据采集、实时生产监控、质量追溯、多系统协同分析及 MES 实时化升级需求的场景。方案可在不改变原有 MES 业务体系的前提下,构建统一的工业实时数据底座,实现生产过程实时感知、异常预警、质量追溯、运营分析与数据服务能力提升,帮助企业完成从传统生产执行系统向实时数据驱动型智能制造平台的升级。
4. 实际客户案例—— 某汽车零部件供应商 MES 生产统计模块高性能改造
本章以汽车零部件制造企业的 MES 生产统计模块改造项目为例,介绍 DolphinDB 在制造业实时数据处理与历史分析场景中的实际落地方式。
4.1 项目背景与现状问题
随着生产数据持续积累,该企业同样遭遇了第 2.3 节所述的典型瓶颈:在生产现场,部分班次产量、小时产量等核心统计查询耗时已达到数分钟甚至几十分钟,报警分析与停机统计依赖大量嵌套 SQL 与临时表,质量追溯需跨系统关联,已开始明显影响实时看板、设备监控及异常排查的现场运营效率。
该企业希望在不重构现有 MES 业务体系的前提下,提升实时统计与历史分析能力,构建能够支撑长期工业数据增长的实时数据平台。
4.2 DolphinDB 实施方案
本项目采用第 3 章所述的 DolphinDB 统一工业数据底座方案,在不重构现有 MES 业务体系的前提下,对 PLC、机器人、测试设备、SCADA 及 MES 业务系统数据进行统一接入,并将生产统计、历史分析及质量追溯等核心查询逻辑统一收敛至 DolphinDB 执行。
在此基础上,本节重点介绍在该企业场景下针对班次产量、小时产量、报警与停机统计三类高频查询的具体优化实践,以及在持续累积的历史数据规模下的性能表现。
三类场景的优化均基于 DolphinDB 多模态存储引擎的共同能力——时间/产线复合分区、分区剪枝、列式存储与向量化聚合。各场景的差异主要体现在分区策略与统计逻辑的针对性设计上,下文不再重复展开通用原理,只聚焦每个场景的特定实现。
本次性能测试的硬件与软件环境配置如下:
-
CPU:Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz
-
逻辑核心数:16
-
内存:64 GB
-
存储:SSD
-
操作系统:64-bit CentOS Linux 7 (Core)
-
DolphinDB Server:3.00.5
传统关系型数据库侧采用标准 SQL 聚合查询实现,DolphinDB 侧相关统计逻辑基于 Dlang(DolphinDB 官方脚本语言)实现。测试前均清理数据缓存与执行计划缓存,基于冷缓存(Cold Cache)模式进行验证,以更真实地评估底层扫描与聚合性能。
4.2.1 班次产量统计优化
班次产量统计是 MES 中最高频的核心查询之一,需要按班次维度对生产记录进行实时聚合,支撑生产看板、班次交接报表及车间日常运营。
原有方案瓶颈
原有关系型数据库架构下,班次产量统计需对生产记录表进行大量聚合与关联计算。随着历史数据持续积累,单次查询的扫描与聚合开销显著上升,在 5,000 万条数据规模下查询响应已达秒级,难以支撑实时刷新场景。
DolphinDB 优化方案
针对该场景,DolphinDB 采用 生产日期(WorkDate)+ 产线编码(LineCode) 复合分区策略。由于班次统计具备明确的时间范围与产线过滤条件,可通过分区剪枝快速定位目标数据,避免全表扫描;同时 SUM、COUNT 等聚合属于典型向量化场景,能够充分发挥 DolphinDB 列式存储与批量计算的性能优势。
改造后,在约 5,000 万条生产记录数据规模下,班次产量统计查询实测性能对比如下:
| 数据规模 | 原有架构 | DolphinDB | 提升倍数 |
|---|---|---|---|
| 5,000 万 | 5,857 毫秒 | 92 毫秒 | 63 倍 |
测试结果表明,在班次产量这类强时间过滤 + 标准聚合的场景下,DolphinDB 凭借按生产日期与产线的复合分区策略,能够将查询响应稳定控制在百毫秒级,相比传统关系型方案具备明显优势,可有效支撑实时生产看板等高频刷新场景。
4.2.2 小时产量统计优化
小时产量统计需要基于生产时间窗口对合格(OK)/ 不合格(NG)数据进行分桶聚合,同时关联工单、设备及班次等业务信息,是 MES 统计分析中典型的多维关联 + 时间窗口聚合场景。
原有方案瓶颈
与班次产量统计的单一时间维度聚合不同,小时产量统计涉及更细粒度的时间窗口切分与多维业务关联。原有关系型数据库架构下,随着数据规模增长,时间窗口分桶、排序及多表关联的开销叠加,复杂聚合查询逐渐成为高频性能瓶颈。
DolphinDB 优化方案
针对该场景,DolphinDB 利用 TSDB 时序存储引擎下数据天然有序的特点,在时间窗口聚合时减少排序与临时结果生成开销。同时,由于小时产量统计仅涉及少量字段的聚合计算,列式存储能够进一步降低列扫描成本,避免传统行式存储中读取大量无关字段的 I/O 浪费。
改造后,在约 5,000 万条生产记录数据规模下,小时产量统计查询实测性能对比如下:
| 查询场景 | 原有架构查询时间 | DolphinDB 查询时间 | 性能提升倍数 |
|---|---|---|---|
| 单产线单班次小时产量统计 | 8,235 ms | 78 ms | 约 105 倍 |
| 全厂 20 条产线小时产量统计 | 15,620 ms | 135 ms | 约 116 倍 |
测试结果表明,在涉及多时间窗口聚合与多维业务关联的复杂统计场景下,DolphinDB 基于 TSDB 时序引擎的天然有序特性,能够显著降低排序与中间结果开销,无论单产线还是全厂多产线场景均能保持百毫秒级响应,更适合支撑现场实时监控与多维度产量分析需求。
4.2.3 报警与停机统计优化
报警与停机统计是 MES 中查询复杂度最高的场景之一,涉及报警起止识别、停机时长计算、跨班次时间分摊及多维度聚合分析,是设备综合效率(OEE)分析与故障根因定位的核心数据基础。
原有方案瓶颈
与前两类场景的聚合计算不同,报警与停机统计的核心难点在于连续状态变化数据的识别与区间计算。传统关系型数据库架构下,需要依赖大量窗口函数、临时表及多层 SQL 嵌套完成报警起止配对、停机区间计算及班次分摊,执行计划复杂度远高于常规聚合查询,且中间结果频繁落盘,随数据规模增长性能衰减尤为明显。
DolphinDB 优化方案
针对该场景的特殊性,DolphinDB 基于时间顺序快速识别状态切换过程,直接完成停机区间计算、报警聚合及班次分摊分析,从而避免传统方案中多层嵌套 SQL 与临时表带来的执行计划膨胀与中间结果开销。这一能力是 DolphinDB 相对前两类场景最显著的差异化优势——不仅是"算得快",更是"算得简",将原本需要数十行嵌套 SQL 的复杂逻辑收敛为简洁的时序分析表达。
改造后,在约 5,000 万条报警与设备状态数据规模下,报警与停机统计性能对比如下:
| 查询场景 | 原有架构查询时间 | DolphinDB 查询时间 | 性能提升倍数 |
|---|---|---|---|
| 报警汇总统计 | 12,680 ms | 165 ms | 约 77 倍 |
| 报警小时分摊统计 | 18,350 ms | 320 ms | 约 57 倍 |
| 全厂十天停机统计 | 46,200 ms | 580 ms | 约 79 倍 |
测试结果表明,在涉及连续状态变化识别、停机区间计算及多层业务分摊的高复杂度场景下,DolphinDB 能够避免传统方案中多层嵌套 SQL 与临时表带来的执行开销,将原本需要数十秒的复杂查询压缩至秒级以内。这是三类场景中相对传统架构优化幅度最大的部分,可有力支撑设备综合效率(OEE)分析、故障根因定位等深度应用。
4.2.4 高负载场景下的性能表现
前述 4.2.1–4.2.3 三类场景验证了 DolphinDB 在常规生产数据规模下的查询性能优势。为进一步验证 DolphinDB 在海量工业数据场景下的稳定性与扩展能力,本次测试选取 MES 中最典型的“班次产量统计”场景进行压力验证。测试基于生产过程记录表 MFM_ProcessRecord 进行,该表包含产线、班次、工单、工位、产品、生产时间及过程参数等字段,属于典型的 MES 生产过程明细宽表。
本次测试重点模拟制造业场景下“历史数据持续累积”的真实业务特征。随着 MES 长期运行,生产过程记录、设备状态及报警数据会持续增长,系统需要在海量历史数据基础上完成生产统计、实时看板及历史分析等高频查询。本次测试在保持查询 SQL 与过滤条件不变的情况下,逐步扩大生产过程明细表中的历史累计数据规模,分别构建约 1,000 万、2,000 万、5,000 万及 1 亿条生产记录数据场景。
测试环境配置详见 4.2 节统一说明。
DolphinDB 查询脚本如下:
pt = loadTable("dfs://mes_process_data", "MFM_ProcessRecord")
select
LineCode,
ShiftCode,
WorkDate,
sum(iif(OrderType == "Normal", 1, 0)) as NormalCount,
count(ProcessRecordID) as TotalCount
from pt
where WorkDate between 2026.04.14 and 2026.04.23
and LineCode = "T1"
and IsFinalInspection == 1
group by LineCode, ShiftCode, WorkDate测试结果如下:
| 数据规模 | 传统架构查询时间 | DolphinDB 查询时间 | 性能提升倍数 |
|---|---|---|---|
| 1,000 万 | 1,219 ms | 28 ms | 约 43 倍 |
| 2,000 万 | 2,398 ms | 45 ms | 约 53 倍 |
| 5,000 万 | 5,857 ms | 92 ms | 约 63 倍 |
| 1 亿 | 12,524 ms | 164 ms | 约 76 倍 |
从测试结果可以看出,在亿级数据规模下,DolphinDB 仍能将核心生产统计查询响应时间稳定控制在秒级以内,且响应时间随数据量呈接近线性的可预期增长,具备良好的长期可扩展性。
综合 4.2.1–4.2.4 的测试结果,DolphinDB 在工业数据场景下,既能应对当前千万至亿级数据规模的高频实时查询,也具备支撑未来数据持续累积增长的能力,可为后续业务扩展提供充足的性能余量。
4.3 项目价值总结
本次 MES 高性能查询改造项目,重点解决了生产统计、报警分析、停机统计及质量追溯等场景下的查询性能瓶颈问题。
在改造前,部分复杂统计与历史分析场景查询耗时可达数分钟甚至几十分钟,严重影响现场问题排查与生产分析效率。通过引入 DolphinDB,对原有分散在传统数据库、ETL 及中间结果表中的统计逻辑进行统一收敛后,班次产量统计、小时产量统计、报警分析及停机统计等核心场景查询性能均得到明显提升,性能提升达到数十倍以上。
同时,原有大量依赖 ETL、中间结果表及离线统计任务的数据处理链路得到简化,系统复杂度与维护成本明显下降,现场数据分析与问题定位效率得到有效提升。
项目落地后,系统已能够稳定支撑千万级以上工业数据场景下的实时统计与历史分析需求,并为后续质量追溯、工艺优化及智能制造相关场景提供统一的数据分析基础。原有大量依赖人工导出的统计分析场景已逐步实现在线化查询,生产、设备及质量团队的问题定位效率明显提升。
5. 总结
基于 DolphinDB 的 MES 实时数据处理与分析方案,能够帮助制造企业构建统一的工业实时数据底座,实现从数据接入、时序存储、实时计算到质量追溯与运营分析的一体化能力建设。
相比传统多组件架构,该方案在海量工业数据场景下具备更稳定的实时处理与查询响应能力,同时降低系统复杂度与运维成本。
适用前提:本方案适用于产线自动化程度较高、存在高频时序数据、希望在不替换现有 MES 的前提下渐进式升级的场景。落地前需明确核心业务模型、具备工业数据采集接口及基础集群环境。
实践验证:在某汽车零部件供应商等企业实践中,该方案已验证可有效支撑 MES 实时化升级,并为质量分析、工艺优化、预测性维护等场景提供长期数据基础。
DolphinDB 的价值,不仅在于性能优化,更在于帮助企业建立面向未来智能工厂的实时数据处理能力体系。