Publishing and Subscribing
Publish-Subscribe Model
DolphinDB uses a Publish-Subscribe (Pub-Sub) communication model to facilitate the publishing and subscription of streaming data through message queues. This model enables event producers (publishers) and event consumers (subscribers) to operate independently. By decoupling publishers and subscribers, the Pub-Sub model supports modular development, simplifies system management, enhances scalability, and improves response efficiency for publishers.
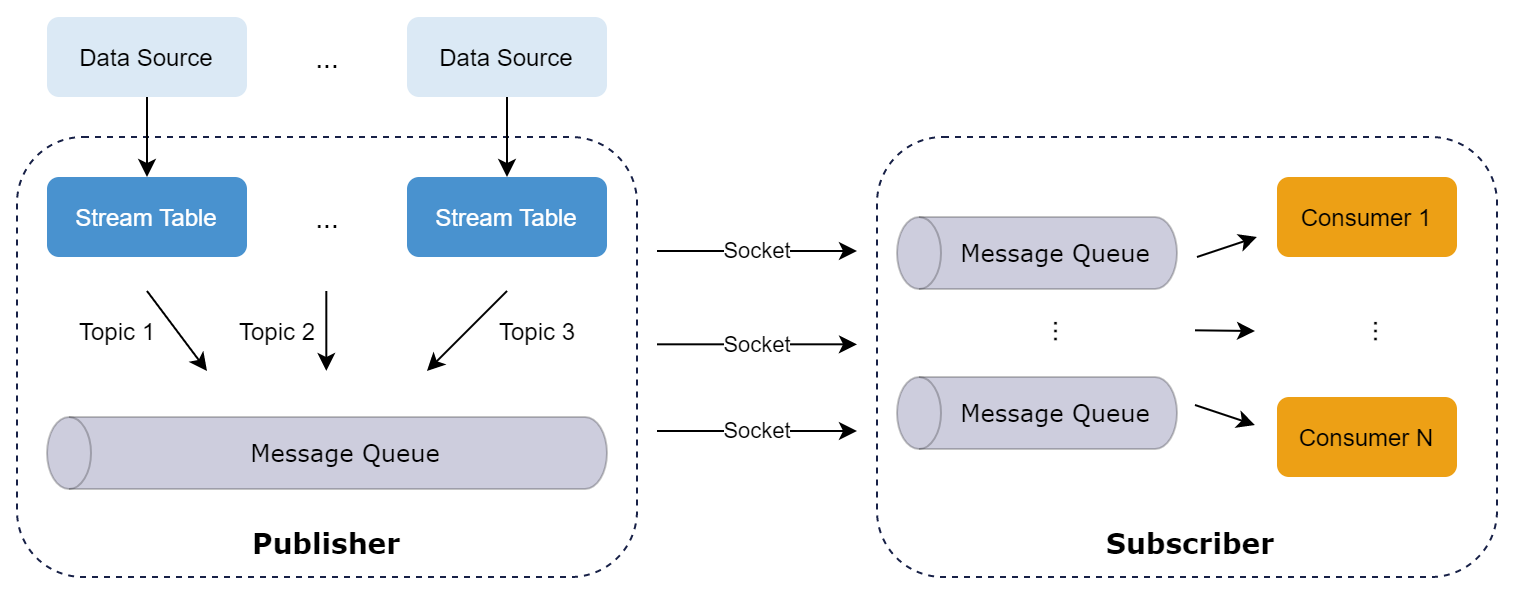
- Publisher: The publisher, which can be a data node or compute node, maintains a publishing queue. When data streams are injected into a publishing table, they are first pushed to the corresponding message publishing queue. The publishing thread then distributes the data to the subscription queues of all subscribers.
- Subscriber: Each subscriber thread corresponds to a specific subscription queue. Upon initiating a subscription request, subscribers are notified of incoming streams. The subscription thread fetches data from its queue for incremental processing.
Data Consumption
This section provides a simple working example of subscribing to and processing streaming data.
(1) Create a partitioned DFS table for data storage
drop database if exists "dfs://minuteBar"
create database "dfs://minuteBar"
partitioned by VALUE(2020.01.01..2021.01.01)
engine='OLAP'
create table "dfs://minuteBar"."minuteBar"(
securityid SYMBOL
tradetime TIMESTAMP
price DOUBLE
volume INT
amount DOUBLE
)
partitioned by tradetime(2) Create a stream table for publishing data
colNames = ["code", "tradetime", "price", "volume"]
colTypes = [SYMBOL, TIMESTAMP, DOUBLE, INT]
share(table=streamTable(1:0, colNames, colTypes), sharedName="pubTable")(3) Define function dataETL for subscription callback
def dataETL(msg){
result = select *, price*volume as amount from msg where price>=10.6
loadTable("dfs://minuteBar", "minuteBar").append!(result)
}(4) Submit subscription
subscribeTable(tableName="pubTable", actionName="dataETL", offset=-1, handler=dataETL, msgAsTable=true, batchSize=2000, throttle=0.01)Where
offset=-1means subscribing from the most recent record.handler=dataETLspecifies the user-defined callback functiondataETLto process the data.msgAsTable=trueindicates that the message object is treated as a table.batchSize=2000andthrottle=0.01define the conditions under which the callback will be triggered (either when 2000 records are ready or 0.01 seconds have passed).
If a message like localhost:8200:local8200/pubTable/dataETL is
returned, the subscription is successfully established.
(5) Write mock data to the publishing table.
tableInsert(pubTable, "000001SZ", 2023.12.15T09:30:00.000, 10.5, 200)
tableInsert(pubTable, "000001SZ", 2023.12.15T09:31:00.000, 10.6, 1000)
tableInsert(pubTable, "000001SZ", 2023.12.15T09:32:00.000, 10.7, 600)
tableInsert(pubTable, "000001SZ", 2023.12.15T09:33:00.000, 10.8, 800)
tableInsert(pubTable, "000001SZ", 2023.12.15T09:34:00.000, 10.7, 500)
tableInsert(pubTable, "000001SZ", 2023.12.15T09:35:00.000, 10.6, 1200)(6) Check data in table minuteBar.
res = select * from loadTable("dfs://minuteBar", "minuteBar") where date(tradetime)=2023.12.15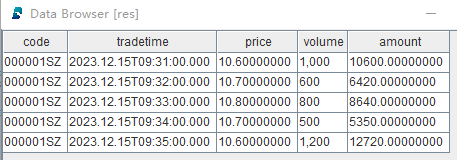
The query result shows that records with price < 10.6 are filtered out, and the amount column (calculated as price * volume) is added.

(7) Unsubscribe from the stream table. Note that all subscriptions to a stream table must be cancelled before deleting the table.
unsubscribeTable(tableName="pubTable", actionName="dataETL")(8) Delete the stream table.
dropStreamTable(tableName="pubTable")(9) Delete the database.
drop database if exists "dfs://minuteBar"Automatic Reconnection
To enable automatic reconnection after network disruption, the stream table must be
persisted on the publisher. When parameter reconnect of function
subscribeTable is set to true, the subscriber will record the
offset of the streaming data. When the network connection is interrupted, the
subscriber will automatically re-subscribe from the offset. If the subscriber
crashes or the stream table is not persisted on the publisher, the subscriber cannot
automatically reconnect.
subscribeTable(tableName="pubTable", actionName="dataETL", offset=-1, handler=dataETL, msgAsTable=true, batchSize=2000, throttle=0.01, reconnect=true)Filtering Published Data
Streaming data can be filtered at the publisher to significantly reduce network
traffic. Use setStreamTableFilterColumn on the stream table to specify the filtering
column, then specify a vector for parameter filter in function
subscribeTable. Only the rows with matching column values are
published to the subscriber. As of now a stream table can have only one filtering
column. In the following example, the stream table trades on the publisher only
publishes data for IBM and GOOG to the subscriber:
share streamTable(10000:0,`time`symbol`price, [TIMESTAMP,SYMBOL,INT]) as trades
setStreamTableFilterColumn(trades, `symbol)
trades_slave=table(10000:0,`time`symbol`price, [TIMESTAMP,SYMBOL,INT])
filter=symbol(`IBM`GOOG)
subscribeTable(tableName=`trades, actionName=`trades_slave, handler=append!{trades_slave}, msgAsTable=true, filter=filter);