Orca Real-time Computing Platform
1. Overview of Orca
As multi-cluster deployments become the norm, enterprises are placing higher demands on streaming data products. The requirements for accessing stream data across clusters, performing complex computations, and managing operations are growing increasingly sophisticated. Traditional streaming architectures struggle to handle complex task dependencies, resource scheduling and high availability, gradually becoming a bottleneck to business development.
Current streaming architectures face several core challages:
- Complex codes and high error rate
Users must manually derive table schema and write code to handle parallel execution, cascading dependencies, and resource cleanup. This results in a complex development process that is prone to errors.
- Exposure to low-level concepts increases cognitive load
There is a lack of abstraction. For example, publishing a stream table requires the use of
sharekeyword, and users need to understand underlying system details such as shared session, increasing the learning curve. - Complex deployment and maintenance
Users must manually specify which physical node to deploy streaming task on. After a node restarts, the entire streaming framework must be rebuilt, as there is no built-in mechanism for automatic recovery.
- Managing operation is under many limits
Operations such as querying stream tables, writing data, and warming up engines must be executed on specific nodes, making unified management and automatic scheduling.
Orca provides an abstraction and enhancement layer on top of DolphinDB existing streaming architecture. Its core goals include:
- Computation abstraction
Orca offers a declarative API that supports chainable programming style, significantly simplifying the construction of streaming computation pipelines. Users are freed from concerns such as schema inference, parallelization, cascading subscriptions, and resource cleanup.
- Automatic scheduling
Based on the defined stream graph, cluster topology and resource availability, Orca automatically handles task deployment and execution, eliminating the need for manual intervention.
- High availability of streaming task
With built-in Checkpoint mechanism, Orca can automatically recover the task to the latest snapshot state in the event of nodes failure or crash, ensuring no data is lost during processing.
2. Core Concepts
This section introduces the fundamental concepts of Orca, including the declarative API programming model, the types and lifecycles of stream graphs, the roles of different stream table, and the decomposition of stream graph and tasks.
2.1 Fully Qualified Name
DolphinDB supports catalogs to organize various database objects, including distributed tables. Orca further extends the useage of catalogs by registering stream graphs, stream table, and engines into the catalog system. This allows users to access all types of objects in a unified manner.
To uniquely identify objects in the catalog, the current version adopts a
three-part naming convention in the format
<catalog>.<schema>.<name>, referred to as the
Fully Qualified Name (FQN). When naming an object, users only need to specify
the name, and Orca will automatically complete the FQN as follows:
- catalog is determined by the current catalog context.
- schema is set to one of orca_graph, orca_table, or orca_engine, depending on whether the object is a stream graph, stream table, or engine.
2.2 Declarative API
Orca provides a Declarative Stream API (DStream API) to simplify the construction of real-time stream graphs. This API abstracts away the complexities of low-level parallel scheduling, subscription logic, and resource cleanup, allowing users to focus on business logic.
Users do not need to manually derive table schemas, implement parallel engine
logic, write subscription declarations, or manage task cleanup and destruction.
The system automatically converts DStream definitions into corresponding
DolphinDB function calls (e.g., streamTable,
subscribeTable, createReactiveStateEngine)
and packages them into executable stream tasks, which are then dispatched to
appropriate nodes for execution.
Orca can convert stream graph defined by DStream API to function calls such as
streamTable, subscribeTable, and
createReactiveStateEngine, package them as stream tasks and
send to physical nodes.
The DStream API consists of the following main categories:
- Node Definition APIs: e.g.,
source,buffer,sink,timeSeriesEngine,reactiveStateEngine - Node Modifier APIs: e.g.,
setEngineName,parallelize,sync - Edge Operation APIs: e.g.,
map,fork
For the complete list of interfaces, refer to the Appendix.
The interface list is shown in the Appendix. Users should think in terms of building a chain-like structure: continuously appending or modifying nodes at the end to progressively construct the full stream graph.
2.3 Stream Graph
The computation pipeline constructed using the DStream API is abstracted as a Directed Acyclic Graph (DAG), referred to as a Stream Graph. In this graph, each node represents a stream table or an engine, and each edge denotes the data flow relationship between nodes—such as cascading or subscription.
Stream graphs are categorized into logical stream graphs and physical stream graphs:
- A logical stream graph is constructed step-by-step using the DStream API. It reflects the actual business logic, as illustrated in Figure 2-1.
- A physical stream graph is generated by the system upon submission of
the logical graph via
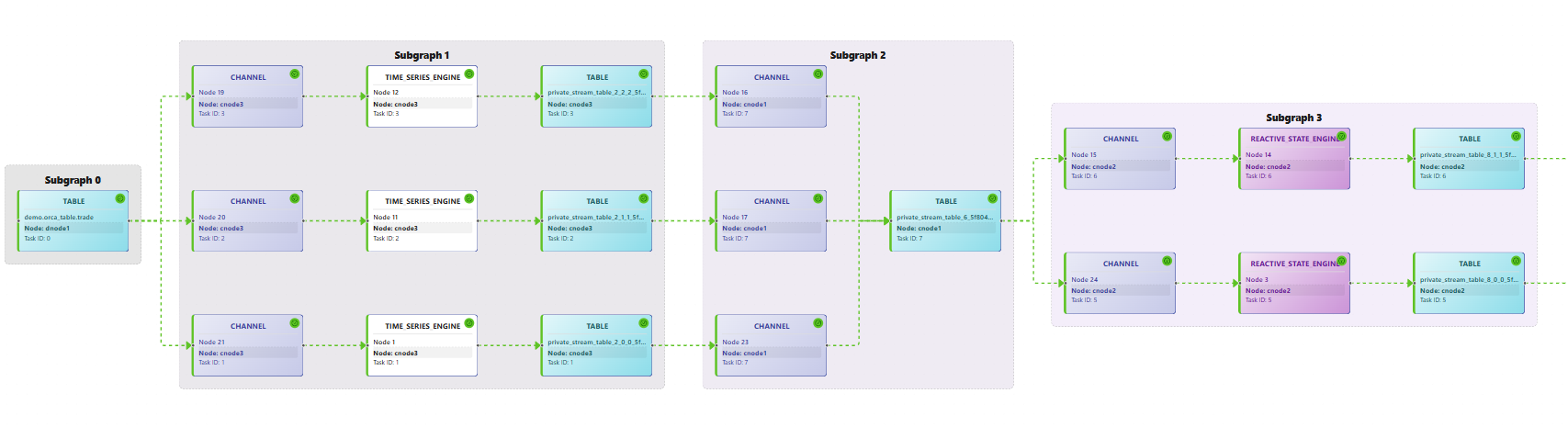
submit. During this process, the system automatically inserts private stream tables, applies scheduling optimizations, splits the graph into subgraphs, and generates parallel tasks. The resulting physical stream graph defines the concrete execution plan for streaming tasks, as shown in Figure 2-2.
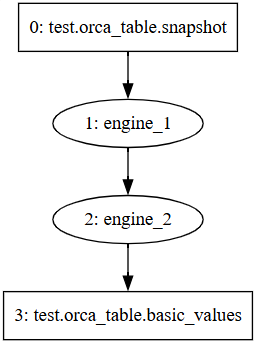
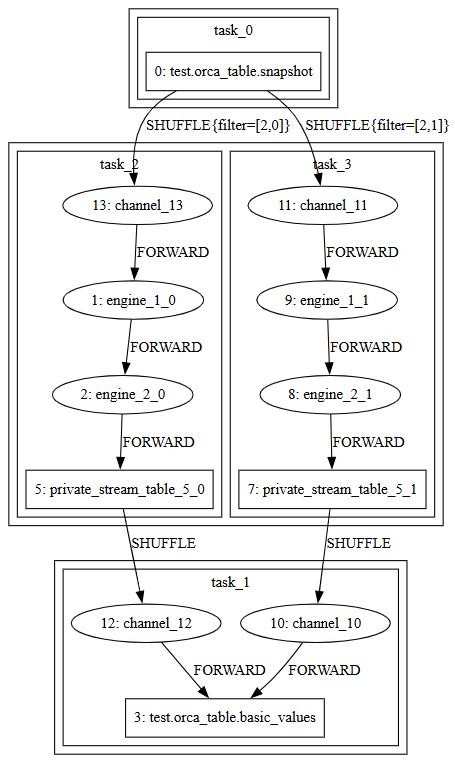
To manage the lifecycle of stream graphs, Orca defines a series of states and transitions:
- building: The task has been scheduled. It is currently not yet dispatched for execution, or the system is performing cascading or subscription construction.
- running: The task has been constructed and is running normally.
- error: A recoverable error has occurred.
- failed: An unrecoverable error has occurred—typically due to a logical problem in the task itself. User intervention is required to modify the script, or an out-of-memory error occurs.
- destroying: The user has requested to destroy the stream graph. The system is currently in the process of destroying it.
- destroyed: The stream graph has been fully destroyed, and the state machine has terminated.
2.4 Stream Table
Orca supports two types of stream tables for data transmission and buffering:
- Private stream tables are non-persistent and used exclusively within a single stream graph. They are primarily intended for caching intermediate results, aligning parallelism across nodes, or supporting multiple downstream subscriptions. These tables are not accessible via SQL queries. All private stream tables are automatically destroyed when their associated stream graph is destroyed.
- Public stream tables are persistent and can be shared across multiple stream graphs. They are used for external data interaction, persistent output, or as streaming data sources. Public stream tables are directly queryable via SQL. When a public stream table is no longer subscribed to by any stream graph, it is automatically destroyed and its fully qualified name (FQN) is released.
2.5 Subgraph and Stream Task
When a user submits a logical stream graph, Orca performs the following processing steps:
- Cycle detection: The system checks for cycles using topological sorting. If a cycle is detected, an error is thrown.
- Insert stream tables: Private stream tables are added to buffer
intermediate results. For example:
- If an engine has multiple downstream nodes, stream tables are required because engines support only cascading output (not subscription).
- If the parallelism levels of upstream and downstream nodes differ, a stream table is inserted to collect upstream data and redistribute it according to the downstream parallelism. This redistribution process is referred to as a shuffle.
- Optimization: Redundant private stream tables introduced during preprocessing are removed to simplify the graph.
- Subgraph partitioning: The entire stream graph is split into subgraphs with consistent parallelism. These subgraphs are constructed to be as long as possible, minimizing the number of tasks that need to be executed in parallel.
- Stream task generation: Within each subgraph, stream tasks are created based on the subgraph’s parallelism. A stream task is the basic unit of execution—it is dispatched to a single thread and consists of a sequential chain of engines and stream tables. Stream tasks communicate with each other by subscribing to upstream data. The total number of stream tasks determines the upper bound of thread usage in the system. Orca minimizes the number of tasks to maximize resource efficiency.
- Channel insertion: The system automatically inserts Channels to support Barrier alignment during Checkpoint operations (see Checkpoint mechanism).
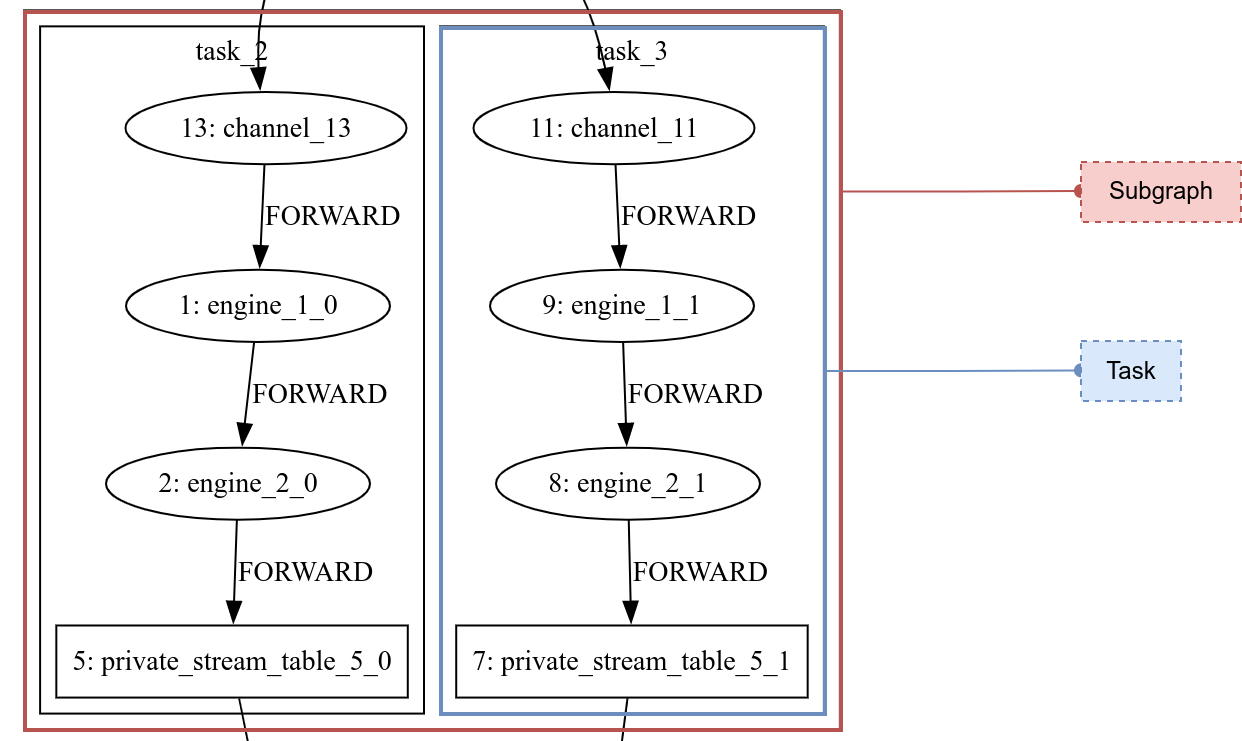
As shown in Figure 2-3, the red box represents a subgraph and the blue box represents a stream task:
3. System Architecture
Orca adopts a typical Master-Worker architecture, leveraging DolphinDB’s Distributed File System (DFS) to support automatic stream graph deployment, task scheduling, and fault recovery. The system components are clearly defined, and centralized state management ensures high availability for streaming computations.
3.1 Overall Architecture
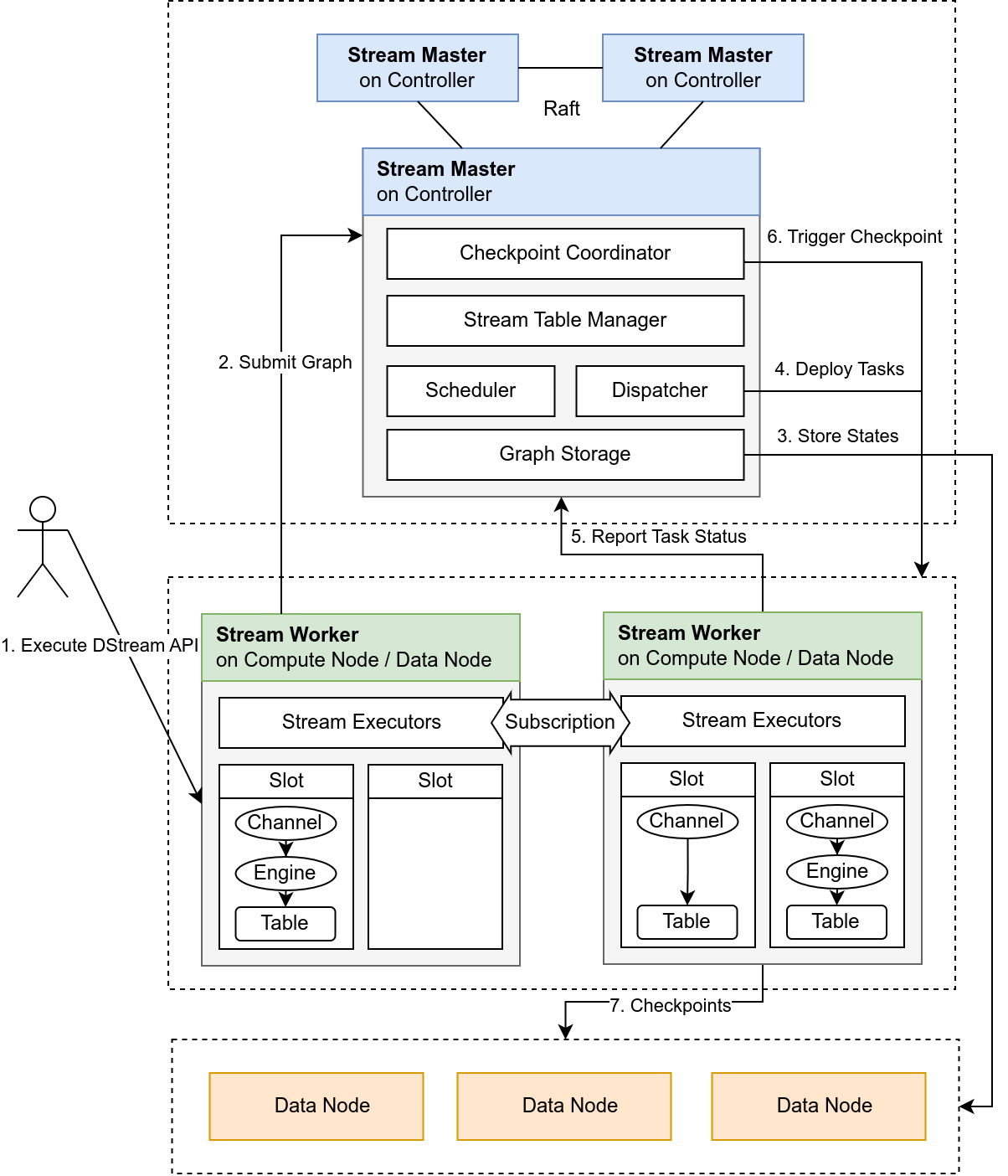
The architecture of Orca is illustrated inFigure 3-1:
- Users submit stream graph definitions by calling Orca APIs.
- The Stream Master receives the logical stream graph, and generates the physical stream graph and scheduling plan based on the graph topology and current cluster resource status.
- Stream Workers are responsible for building stream tables and engines, executing stream tasks, and performing Checkpoint operations.
- All critical states—including stream graph structure, scheduling records, stream table locations, and Checkpoint metadata—are persisted to DFS tables.
- Internally, heartbeat checks, state reporting, and the Barrier mechanism are used to ensure high availability and consistent execution of the stream graph.
3.2 Stream Master
The Stream Master runs on the controller node and is responsible for the following tasks:
- Receiving user requests (e.g., submitting or deleting stream graphs, querying status).
- Receiving status reports from Stream Workers.
- Executing the stream graph state machine (from building → running → error recovery → destroyed).
- Dispatching tasks to different nodes, managing parallelism and resource isolation.
- Periodically triggering Checkpoints, coordinating all tasks within the stream graph to take snapshots.
- Maintaining metadata and persisting it to DFS tables.
3.3 Stream Worker
The Stream Worker runs on data nodes or compute nodes and is responsible for the following tasks:
- Receiving tasks dispatched by the Stream Master, building stream tables, engines, and the cascade and subscription topology;
- Executing and monitoring streaming tasks (e.g., aggregation, state computation, metric generation);
- Performing local state snapshots and uploading Checkpoints.
All data processing on the Stream Worker is performed entirely in memory. Except for public stream tables, no local persistence is performed. Engine states are preserved through the Checkpoint mechanism.
4. Stream Task Scheduling
To ensure proper task distribution and efficient execution, Orca provides a built-in distributed scheduling algorithm. It dynamically dispatches stream tasks based on node resource scoring, scheduling rule matching, and stream graph topology analysis. The system also supports error recovery rescheduling and compute group isolation to ensure both resource isolation and runtime stability.
4.1 Scheduling Principles
The scheduler follows these principles:
- Load balancing: Preferentially dispatch tasks to nodes with more idle resources, avoiding CPU, memory, or disk overload.
- Compute group isolation: Tasks within the same stream graph run within the same compute group.
- Stream table placement constraints: Public stream tables must be deployed on data nodes.
- Sibling task affinity: Tasks that share both upstream and downstream nodes are considered sibling tasks and are scheduled to the same node to reduce communication overhead.
4.2 Node Scoring Mechanism
Each candidate node is assigned a score based on its available resources to represent its scheduling priority. Different node types use different scoring metrics:
- Compute nodes are scored based on their CPU usage and memory usage.
- Data nodes are scored based on their CPU usage, memory usage, and disk usage.
4.3 Scheduling Process and Task Assignment
The scheduling process follows a greedy strategy. The overall workflow is:
- Sort tasks by complexity: The system estimates task complexity based on the number of operators in the stream task. More complex tasks are scheduled earlier.
- Score candidate nodes: For each task, all eligible nodes are scored according to the rules defined above.
- Select preferred nodes:
- If the task contains public stream tables, only data nodes are considered.
- If not, the scheduler selects from compute nodes within the same compute group.
- If a node has already been assigned a sibling task, its score is increased.
- Assign the task: The task is dispatched to the highest-scoring node, and that node’s score is updated to reflect the new load, enabling adaptive scheduling for subsequent tasks.
5. High Availability of Computation Tasks
To ensure the stable execution of stream computation tasks in a distributed environment, Orca employs a stream-graph-level Checkpoint mechanism. This mechanism enables fast task recovery in the event of node failures, network interruptions, or storage errors, ensuring no data loss.
5.1 Checkpoint Mechanism
Orca's Checkpoint implementation is based on the Chandy–Lamport distributed snapshot algorithm, which introduces Barrier markers to define consistency boundaries within the data flow, thus producing globally consistent snapshots.
The core Checkpoint process includes the following steps:
- The Checkpoint Coordinator periodically triggers Checkpoint tasks and injects Barrier markers into all source nodes.
- Upon receiving a Barrier, the source node atomically writes it to the stream table and records the current data offset.
- As the Barrier flows through the stream graph, each engine or stream table that receives it from upstream performs a local state snapshot, and then passes the Barrier downstream.
- When a sink node receives the Barrier, it indicates that all its upstream nodes have completed their snapshots. Once all sink nodes receive the Barrier, the Checkpoint is considered complete.
5.2 End-to-End Consistency
There are two levels of consistency semantics:
- AT_LEAST_ONCE: Data is processed at least once—no data is lost, but duplicates may occur.
- EXACTLY_ONCE: Data is processed exactly once—no loss, no duplicates.
Orca provides end-to-end consistency—from source nodes to sink nodes—by implementing the following guarantees:
- Source-side consistency is achieved by persisting stream tables and tracking data offsets, enabling replay from a known position upon restart.
- Computation task consistency is guaranteed by the Chandy–Lamport snapshot algorithm, ensuring globally consistent snapshots across the distributed system.
- Sink-side consistency is determined by the type of stream table used.
EXACTLY_ONCE is only achievable if all public stream tables (except sources)
are either
keyedStreamTableorlatestKeyedStreamTable. These tables provide deduplication, filtering out redundant upstream data.
EXACTLY_ONCE semantics rely on in-memory key-level deduplication. Once a record with a given key is persisted, the system may still accept a new record with the same key.
Therefore, the system ensures uniqueness in memory, not globally. This is sufficient to handle multi-writer or delayed submission scenarios that may lead to duplicates.
5.3 Barrier Alignment
For EXACTLY_ONCE consistency, Barrier alignment is required when there are multiple upstream paths. A stream task must wait for all upstream Barriers before taking a snapshot. This process is known as Barrier alignment.
To achieve this, Orca introduces a lightweight intermediate component called Channel, inserted into every stream task except source nodes, with the following behavior:
- Each Channel is placed on a distinct upstream path to an engine or stream table. When a Barrier is received, the Channel pauses data transmission on that path.
- Once all Channels receive the Barrier, the stream task executes local snapshots of all downstream engines or stream tables in order.
- After snapshot completion, the Barrier is forwarded to the output stream table and subsequently to downstream tasks.
6. Operations and Access Control
To ensure the stable operation of stream computing tasks and support efficient troubleshooting, Orca provides a comprehensive set of operational interfaces and visual monitoring tools.
6.1 Stream Graph Operations
Orca offers a rich set of maintenance and monitoring functions. For a detailed list of functions, see the Appendix.
6.2 Visual Interface Support
In addition to operational functions, Orca includes a web-based visualization module that graphically displays the structure and runtime status of stream graphs. This module presents all stream graphs in the cluster.
Figure 6-1 shows the status of a node within a stream graph:
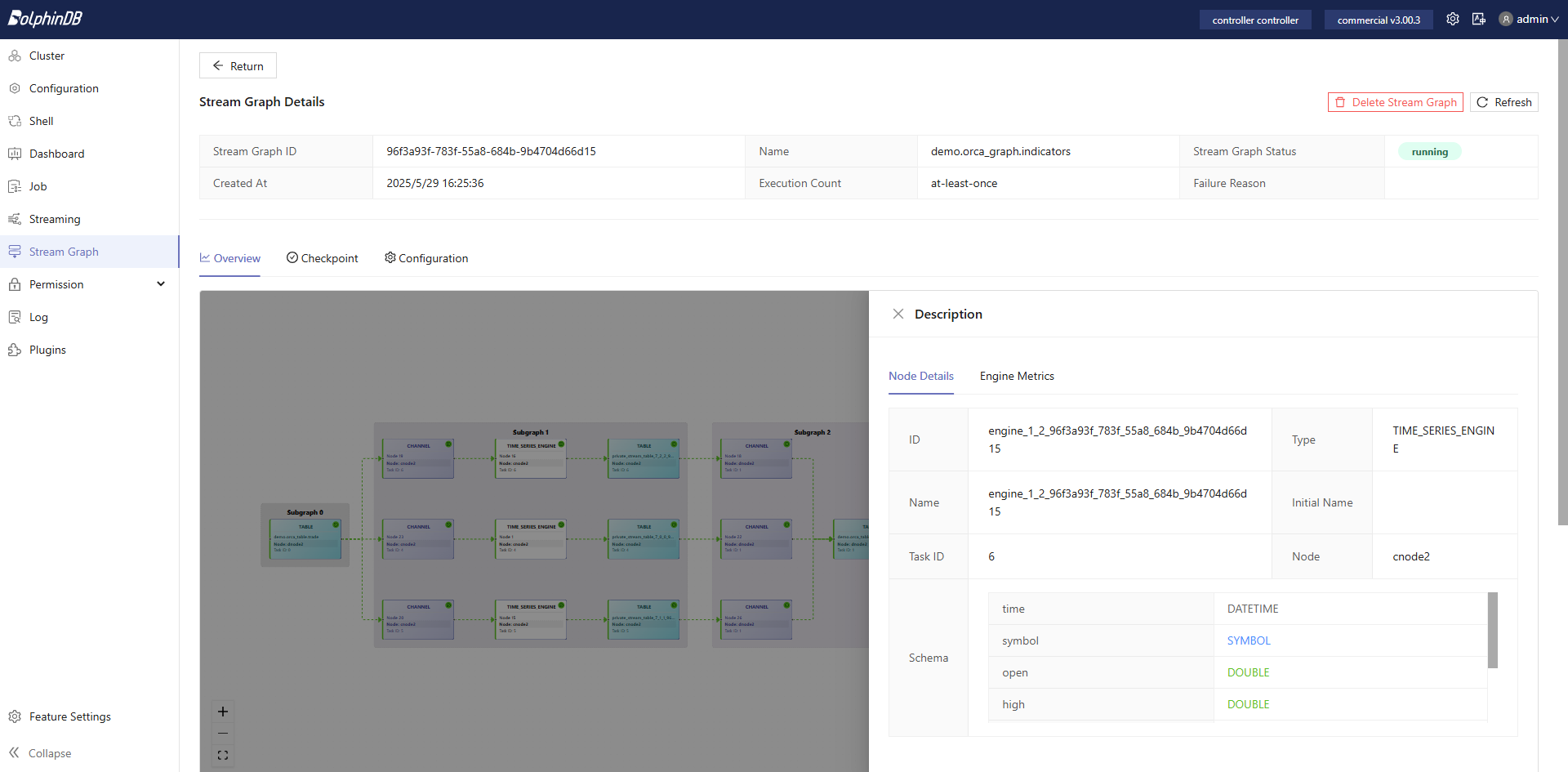
6.3 Access Control
Orca’s access control is built on top of the unified DolphinDB permission system and introduces Orca-specific privileges to provide fine-grained control over operations on stream graphs, stream tables, and streaming engines.
Operations on stream graphs that involve computing resources—such as submitting, deleting, or starting graphs—still require the corresponding base DolphinDB privileges, for example COMPUTE_GROUP_EXEC, which controls access to computing resources (compute groups).
6.3.1 Orca Privilege Types
On top of the required base compute privileges, Orca provides the following ORCA-related privileges to further control operations on stream graphs, stream tables, and streaming engines.
These privileges can be granted at the Catalog level, object level (stream graph / stream table / streaming engine), or global level, enabling fine-grained permission isolation in multi-user environments.
| Privilege Object | Privilege Type | Description | Scope |
|---|---|---|---|
| Orca Graph | ORCA_GRAPH_CREATE | Create Orca graphs | Catalog level |
| ORCA_GRAPH_DROP | Drop Orca graphs | Catalog level | |
| ORCA_GRAPH_CONTROL | Operate and manage Orca graphs, including starting, stopping, resubmitting, and configuring graph parameters | Catalog or graph level | |
| Streaming Table | ORCA_TABLE_CREATE | Create streaming tables | Catalog level |
| ORCA_TABLE_DROP | Drop streaming tables | Catalog level | |
| ORCA_TABLE_READ | Read data from streaming tables | Catalog or table level | |
| ORCA_TABLE_WRITE | Write data to streaming tables | Catalog or table level | |
| ORCA_ENGINE_MANAGE | Manage streaming engine operations, including
warmupOrcaStreamEngine,
stopTimerEngine,
resumeTimerEngine, and
useOrcaStreamEngine |
Catalog or engine level | |
| Orca Administration | ORCA_MANAGE | Orca administration privilege, which includes all ORCA-related privileges | Global or Catalog level |
6.3.2 Privilege Scope
Global-Level Privileges
After a global-level privilege is granted, the user has the corresponding permission on all stream graphs, streaming tables, and streaming engines across all catalogs.
Currently, only the ORCA_MANAGE privilege can be granted at the global level.
Catalog-Level Privileges
After a privilege is granted at the Catalog level, the user has the corresponding permission on all stream graphs, streaming tables, or streaming engines within that Catalog.
Object-Level Privileges
Object-level privileges allow permissions to be granted on a specific stream graph, streaming table, or streaming engine.
When granting object-level privileges, the target object must be specified using its fully qualified name (FQN):
-
Stream graph:
catalog.orca_graph.graphName -
Streaming table:
catalog.orca_table.tableName
Examples
Grant user1 the privilege to create stream graphs in myCatalog:
grant("user1", ORCA_GRAPH_CREATE, "myCatalog")Grant user1 the privilege to drop stream graphs in myCatalog:
grant("user1", ORCA_GRAPH_DROP, "myCatalog")Grant user1 the privilege to operate stream graphs:
// Grant permission to operate all stream graphs in myCatalog
grant("user1", ORCA_GRAPH_CONTROL, "myCatalog")
// Grant permission to operate a specific stream graph
grant("user1", ORCA_GRAPH_CONTROL, "myCatalog.orca_graph.myGraph")Grant user1 the privilege to create streaming tables in myCatalog:
grant("user1", ORCA_TABLE_CREATE, "myCatalog")Grant user1 the privilege to drop streaming tables in myCatalog:
grant("user1", ORCA_TABLE_DROP, "myCatalog")Grant user1 the privilege to read streaming tables:
// Grant permission to read all streaming tables in myCatalog
grant("user1", ORCA_TABLE_READ, "myCatalog")
// Grant permission to read a specific streaming table
grant("user1", ORCA_TABLE_READ, "myCatalog.orca_table.myTable")Grant user1 the privilege to write to streaming tables:
// Grant permission to write to all streaming tables in myCatalog
grant("user1", ORCA_TABLE_WRITE, "myCatalog")
// Grant permission to write to a specific streaming table
grant("user1", ORCA_TABLE_WRITE, "myCatalog.orca_table.myTable")Grant user1 the ORCA management privilege:
// Grant ORCA management privileges within myCatalog
grant("user1", ORCA_MANAGE, "myCatalog")
// Grant ORCA management privileges globally (across all catalogs)
grant("user1", ORCA_MANAGE, "*")6.3.3 Permission Evaluation and Effective Rules
Admin users are super administrators (not regular administrators) and have all Orca-related permissions. They are not subject to any permission checks.
The user who creates a stream graph or stream table is automatically considered the owner of that resource and is granted full operational permissions on the corresponding stream graph or stream table.
When creating a new stream graph, the system performs permission checks on any referenced stream tables. The stream graph can be created only if the user has both read and write permissions on the referenced stream tables.
Users with the ORCA_MANAGE permission automatically obtain all Orca permissions under the corresponding Catalog and do not need to be granted permissions on individual stream graphs or stream tables.
When Catalog-level permissions (broad scope) and stream graph / stream table–level permissions (narrow scope) coexist, the effective permissions follow these rules:
-
If you
grant/revoke/denyat a smaller scope, and then manage permissions at a larger scope, the smaller scope permissions will be invalidated and overridden by the larger scope permissions. -
If you
allowat a larger scope, and thendenyat a smaller scope, thedenyoperation will take effect while theallowpermissions still apply to the objects outside of the deny scope. -
If you
allow/denyat a larger scope, and thenrevokeat a smaller scope, therevokeoperation will be invalid while the allow permissions still apply to the original scope. -
If you
revokein a large scope, and then manage permissions at a smaller scope, the smaller scope permissions will take effect.
7. Usage Example: Building a Real-Time Stream Graph for 1-Minute OHLC Aggregation and Indicator Computation
This section provides a complete example to demonstrate how to build a stream graph using Orca. The graph aggregates tick-level trade data into 1-minute OHLC bars and computes common technical indicators in real time (e.g., EMA, MACD, and KDJ).
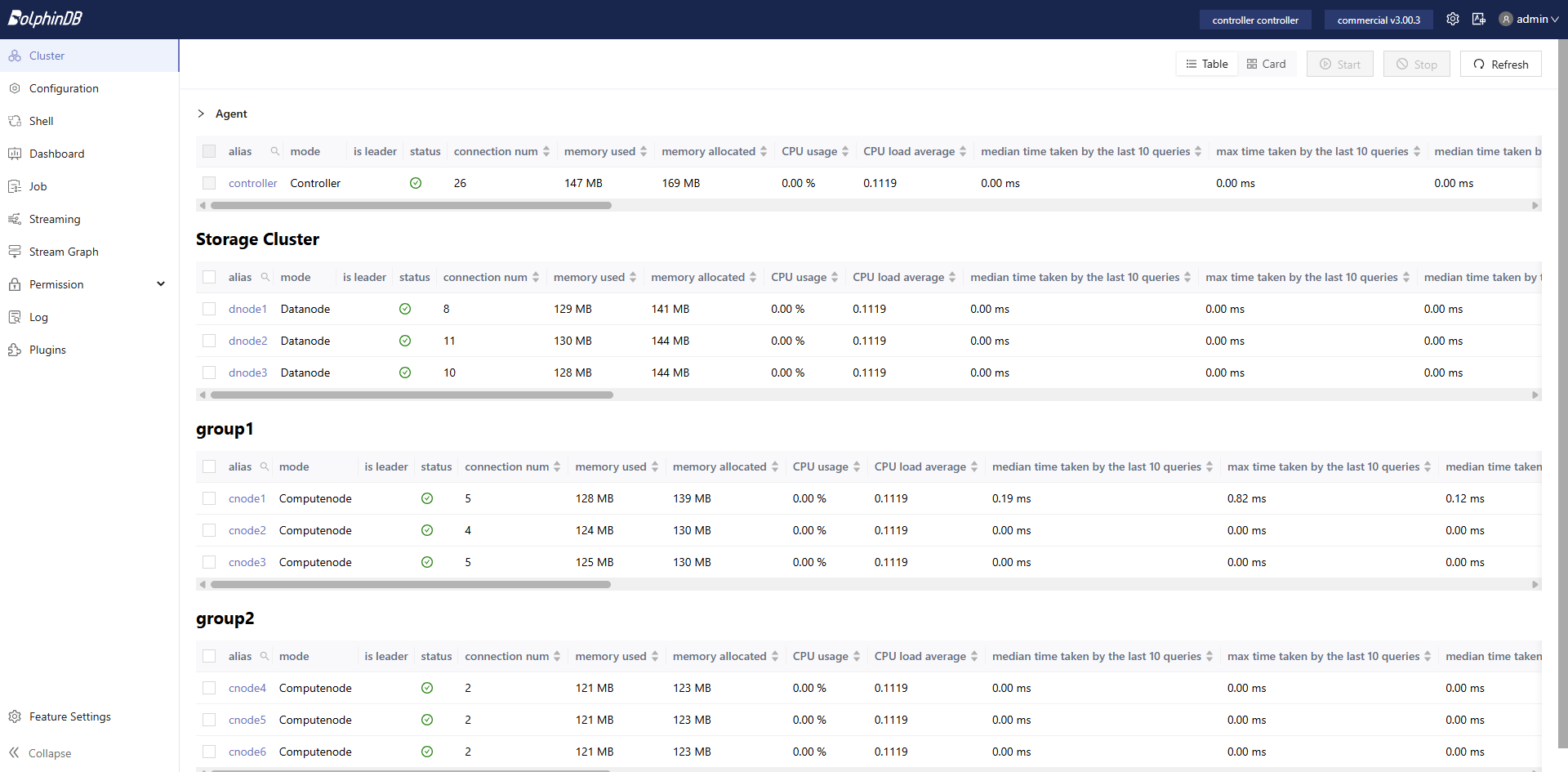
The entire workflow is divided into five steps. All scripts in this example are executed on compute nodes. In this example, the scripts are executed on cnode1 of the cluster. The cluster is as follows:
7.1 Preparation
Update the necessary configuration items:
-
In cluster.cfg and controller.cfg, set
enableORCA=trueto enable the Orca feature. - In
cluster.cfg, set thepersistenceDirpath to persist public stream table data.
Define the catalog, indicator functions, and custom operators:
if (!existsCatalog("demo")) {
createCatalog("demo")
}
go
use catalog demoImplement custom functions for technical indicators:
@state
def EMA(S, N) {
return ::ewmMean(S, span = N, adjust = false)
}
@state
def RD(N, D = 3) {
return ::round(N, D)
}
@state
def HHV(S, N) {
return ::mmax(S, N)
}
@state
def LLV(S, N) {
return ::mmin(S, N)
}
@state
def MACD(CLOSE, SHORT_ = 12, LONG_ = 26, M = 9) {
DIF = EMA(CLOSE, SHORT_) - EMA(CLOSE, LONG_)
DEA = EMA(DIF, M)
MACD = (DIF - DEA) * 2
return RD(DIF, 3), RD(DEA, 3), RD(MACD, 3)
}
@state
def KDJ(CLOSE, HIGH, LOW, N = 9, M1 = 3, M2 = 3) {
RSV = (CLOSE - LLV(LOW, N)) \ (HHV(HIGH, N) - LLV(LOW, N)) * 100
K = EMA(RSV, (M1 * 2 - 1))
D = EMA(K, (M2 * 2 - 1))
J = K * 3 - D * 2
return K, D, J
}Define aggregation and indicator operators:
aggerators = [
<first(price) as open>,
<max(price) as high>,
<min(price) as low>,
<last(price) as close>,
<sum(volume) as volume>
]
indicators = [
<time>,
<high>,
<low>,
<close>,
<volume>,
<EMA(close, 20) as ema20>,
<EMA(close, 60) as ema60>,
<MACD(close) as `dif`dea`macd>,
<KDJ(close, high, low) as `k`d`j>
]7.2 Construct and Submit the Stream Graph
Use the DStream API to define and submit the stream graph.
g = createStreamGraph("indicators")
g.source("trade", `time`symbol`price`volume, [DATETIME,SYMBOL,DOUBLE,LONG])
.parallelize(`symbol,3)
.timeSeriesEngine(windowSize=60, step=60, metrics=aggerators, timeColumn=`time, keyColumn=`symbol)
.sync()
.buffer("one_min_bar")
.parallelize(`symbol,2)
.reactiveStateEngine(metrics=indicators, keyColumn=`symbol)
.sync()
.buffer("one_min_indicators")
g.submit()Wait until the stream graph reaches the running state before proceeding. During this time, you can check the stream graph status via the following interfaces:
getStreamGraphMeta()Example output (status has changed to running):
| id | fqn | status | semantics | checkpointConfig | ... |
|---|---|---|---|---|---|
| df83...08 | demo.orca_graph.indicators | running | at-least-once | ... | ... |
As shown in Figure 7-2, in the stream graph module of the web interface, the stream graph submitted on cnode1 is split and then dispatched to cnode1, cnode2, and cnode3, which all belong to the same compute group group1. To ensure compute resource isolation, the system does not dispatch tasks to nodes in other compute groups.
7.3 Insert Simulated Data
The following script simulates real-time insertion of per-second OHLC data for a stock:
sym = symbol(`600519`601398`601288`601857)
ts = 2025.01.01T09:30:00..2025.01.01T15:00:00
n =size(ts) * size(sym)
symbol = stretch(sym, n)
timestamp = take(ts, n)
price = 100+cumsum(rand(0.02, n)-0.01)
volume = rand(1000, n)
trade = table(timestamp, symbol, price, volume)
appendOrcaStreamTable("trade", trade)7.4 Query the Results
Use SQL to retrieve the aggregated 1-minute OHLC bars and computed indicators:
select * from demo.orca_table.trade
select * from demo.orca_table.one_min_bar
select * from demo.orca_table.one_min_indicators7.5 Clean Up the Stream Graph
The script below will clean up all defined engines and stream tables associated with the graph:
dropStreamGraph("indicators")8. Roadmap
To further enhance Orca’s feature completeness, flexibility, and performance, we plan to optimize the system along the following directions:
8.1 Feature Enhancements
Cross-Cluster Capabilities: Support data streaming across DolphinDB clusters, including cross-cluster subscriptions, stream table access, and join operations, meeting integration needs in multi-cluster environments.
Enhanced State Management: Enable flexible control over computing tasks, such as pausing execution or resetting stream graph state, to improve operations and debugging efficiency.
Finer-Grained Parameter Tuning: Allow users to adjust parameters generated
in the DStream API, such as subscribeTable and
enableTableShareAndCachePurge, enabling more granular
performance tuning.
DStream API Extensions: Expand API capabilities to allow explicit
partition count configuration when defining stream tables and advanced usage
like sourceByName within the same graph, improving flexibility
in graph construction.
Optional High Availability Protocols: Introduce configurable stream data high availability protocols, allowing trade-offs between fault tolerance levels and latency, suitable for diverse business needs.
Optional Scheduling Algorithms: Provide flexible scheduling strategies that support custom trade-offs between throughput and latency, including the ability to integrate user-defined scheduling algorithms.
8.2 Performance Optimizations
Physical Graph Optimization: Improve join performance across stream tables and reduce data shuffle overhead, especially in cross-node scenarios.
Runtime Optimization: Replace certain subscription mechanisms with cascaded execution models to reduce latency and improve runtime efficiency.
Checkpoint Performance Improvements: Further optimize Barrier alignment and introduce incremental and asynchronous snapshot mechanisms to reduce Checkpoint overhead and shorten recovery time during fault tolerance.
9. Appendix
Orca provides following interfaces for managing stream graphs, stream tables, engines, checkpoints, and more.
- Before calling Orca functions, you must first enable the Orca feature by
setting
enableORCA=truein the configuration filecluster.cfgorcontroller.cfg. - In a cluster environment, this function can only be executed on compute nodes within the compute group.
| Category | Interface | Description |
|---|---|---|
| Definition | createStreamGraph | Create a StreamGraph object |
| StreamGraph::setConfigMap | Configure private stream tables and subscriptions in the graph | |
| StreamGraph::source / keyedSource / latestKeyedSource / haSource / haKeyedSource | Define an input source stream table | |
| StreamGraph::sourceByName | Retrieve an Orca public stream table | |
| DStream::anomalyDetectionEngine | Define an anomaly detection engine | |
| DStream::asofJoinEngine | Define an asof join engine | |
| DStream::crossSectionalEngine | Define a cross-sectional engine | |
| DStream::cryptoOrderBookEngine | Define a real-time crypto order book engine | |
| DStream::dailyTimeSeriesEngine | Define a daily time-series engine | |
| DStream::dualOwnershipReactiveStateEngine | Define a dual-ownership reactive state engine | |
| DStream::narrowReactiveStateEngine | Define a reactive state engine that outputs narrow tables | |
| DStream::pricingEngine | Define a pricing engine | |
| DStream::reactiveStateEngine | Define a reactive state engine | |
| DStream::reactiveStatelessEngine | Define a reactive stateless engine | |
| DStream::ruleEngine | Define a rule engine | |
| DStream::sessionWindowEngine | Define a session window engine | |
| DStream::timeBucketEngine | Define a time series aggregation engine with custom bucket sizes | |
| DStream::timeSeriesEngine | Define a time series aggregation engine | |
| DStream::equalJoinEngine | Define an equi join engine | |
| DStream::leftSemiJoinEngine | Define a left semi join engine | |
| DStream::lookupJoinEngine | Define a lookup join engine | |
| DStream::snapshotJoinEngine | Define a snapshot join engine | |
| DStream::windowJoinEngine | Define a window join engine | |
| DStream::buffer / keyedBuffer / latestKeyedBuffer | Define a stream table for immediate output | |
| DStream::sink / keyedSink / latestKeySink / haSink / haKeyedSink | Define an output stream table | |
| DStream::map | Define data transformation logic | |
| DStream::udfEngine | Define a user-defined function that supports side effects and state persistence. | |
| DStream::fork | Branch the stream graph | |
| DStream::parallelize | Set the parallelism of the stream graph | |
| DStream::sync | Aggregate the results of upstream parallel tasks | |
| DStream::setEngineName | Set name for a streaming engine | |
| DStream::getOutputSchema | Retrieve the table schema for downstream definition | |
| DStream::timerEngine | Define a time-triggered engine to periodically execute func at intervals | |
| Graph Management | StreamGraph::submit | Submit the stream graph to start execution |
| getStreamGraph | Retrieve the stream graph object | |
| dropStreamGraph / StreamGraph::dropGraph | Destroy the stream graph | |
| purgeStreamGraphRecords | Delete stream graph records | |
| Stream Table Operations | appendOrcaStreamTable | Insert data into stream tables |
| select * from orca_table. or select * from .orca_table. | Query a stream table | |
| Streaming Engine Operations | warmupOrcaStreamEngine | Warm up streaming engine to improve initial computation performance |
| Status Monitoring | getStreamGraphInfo / getStreamGraphMeta | Retrieve stream graph metadata |
| getOrcaStreamTableMeta | Retrieve stream table metadata | |
| getOrcaStreamEngineMeta | Retrieve streaming engine metadata | |
| getOrcaStreamTaskSubscriptionMeta | Retrieve subscription metadata | |
| getOrcaStateMachineEventTaskStatus | Get state machine task status | |
| StreamGraph::toGraphviz / str | Output the topology structure | |
| getUdfEngineVariable | Query the current value of a specified external
variable in a given DStream::udfEngine. |
|
| stopTimerEngine | Stop execution of jobs submitted by
DStream::timerEngine |
|
| resumeTimerEngine | Resume execution of jobs submitted by
DStream::timerEngine |
|
| Checkpoint Management | setOrcaCheckpointConfig | Configure checkpoint parameters |
| getOrcaCheckpointConfig | View checkpoint configuration | |
| getOrcaCheckpointJobInfo | View checkpoint job execution info | |
| getOrcaCheckpointSubjobInfo | View checkpoint subjob execution info |