Join Engines
Data analysis often involves joining data from multiple sources. In addition to various SQL join operations for historical data, DolphinDB also provides streaming join engines for real-time computing scenarios that require low-latency processing. These engines use incremental calculation to ensure millisecond-level latency performance even with massive data streams.
Table Joins: From Batch to Stream
Batch Joins
For batch processing scenarios, DolphinDB offers SQL-compatible join methods (including equi join, full join, left join, prefix join, and cross join), and also methods especially designed for time-series data including asof join and window join.
For example, perform asof join on historical data:
// data
t1 = table(take(`A, 4) as Sym, 10:10:03.000+(10 2100 2890 6030) as Time, 12.5 12.5 12.6 12.6 as Price)
t2 = table(take(`A, 4) as Sym, 10:10:00.000+(0 3000 6000 9000) as Time, 12.6 12.5 12.7 12.6 as BidPrice)
// asof join calculation
select * from aj(t1, t2, `Time)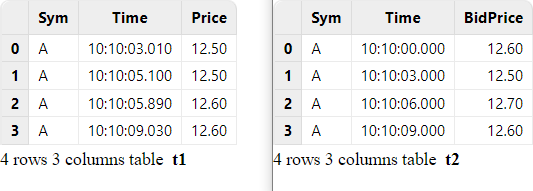
For each record with a timestamp T in the left table, the asof
join takes from the right table a record with the closest timestamp
that is prior or equal to T. In the above example where the join column
"Time" is specified, each record in table t1 is paired with the record in table
t2 whose "Time" value is less than or equal to the "Time" value in t1.
Streaming Joins
The joins over batch tables typically process bounded data sets, which means the input tables are processed all at once to generate a full output. Real-time streaming joins deal with data sets that are unbounded and have no defined end. In such cases, the streams have a starting point, but the arrival time of the next record is unpredictable. Unbounded streams must be continuously processed, i.e., incoming records must be promptly handled after ingestion, and the joined output will be generated incrementally.
To implement streaming joins, there are two technical challenges that need to be addressed:
- Triggering mechanism for join and output
Suppose the above asof join case processes streaming data. When
the first record (with a "Time" value of 10:10:03:010) of stream t1 arrives, the
join engine must decide whether to join the record with a record (with a "Time"
value of 10:10:00.000) in stream t2 and output the result immediately.
Alternatively, it can wait until a triggering condition is satisfied.
- Memory management
To accurately join streams, the join engine needs to cache historical data. Since the input streams are continuously ingested, a garbage collection mechanism is needed.
Streaming Join Engines
DolphinDB offers five types of streaming join engines: as of engine, window join engine, equi join engine, left semi join engine, and lookup join engine. Join engines adhere to join rules consistent with batch joins. Differences are explained in subsequent sections.
The streaming join engine functions as a module that enables real-time joins on streams. It can be conceptualized as a computational black box that applies join rules to two input streams, producing a joined output stream. The engine internally maintains the computing states.

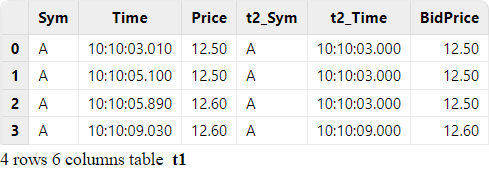
The following script implements asof join over streams (based on the
code example in section "Batch Joins").
createAsofJoinEngine function to create the asof join
engine, and the subscribeTable function to subscribe to the two streams. As data is
continuously ingested into the join engine, the number of records in the output
table will increase
accordingly.// create table
share streamTable(1:0, `Sym`Time`Price, [SYMBOL, TIME, DOUBLE]) as trade
share streamTable(1:0, `Sym`Time`BidPrice, [SYMBOL, TIME, DOUBLE]) as quotes
share table(1:0, `Time`Sym`Price`t2_Time`BidPrice, [TIME, SYMBOL, DOUBLE, TIME, DOUBLE]) as output
// create engine
ajEngine = createAsofJoinEngine(name="asofJoin", leftTable=trade, rightTable=quotes, outputTable=output, metrics=<[Price, quotes.Time, BidPrice]>, matchingColumn=`Sym, timeColumn=`Time, useSystemTime=false, delayedTime=1000)
// subscribe topic
subscribeTable(tableName="trade", actionName="joinLeft", offset=0, handler=getLeftStream(ajEngine), msgAsTable=true)
subscribeTable(tableName="quotes", actionName="joinRight", offset=0, handler=getRightStream(ajEngine), msgAsTable=true)// generate data
t1 = table(take(`A, 4) as Sym, 10:10:03.000+(10 2100 2890 6030) as Time, 12.5 12.5 12.6 12.6 as Price)
t2 = table(take(`A, 4) as Sym, 10:10:00.000+(0 3000 6000 9000) as Time, 12.6 12.5 12.7 12.6 as BidPrice)
// input data
quotes.append!(t2)
trade.append!(t1)To address the challenges of real-time streaming joins discussed in Section "Streaming Joins", the streaming join engines adopt built-in computational rules and parameter interfaces to enhance the trigger mechanism. Memory management is handled through the parameter garbageSize which cleans up unneeded historical data.
The join mechanisms can be classified as follows:
(1) For joins that involve the time order of the data, a join engine processes the inputs based on:
- The system time of data arrivals;
- OR the time columns of the inputs. In such case, the timestamps of subsequent records are unpredictable, and by default the engine processes ingested data as if it is ordered. Additional timeout triggers can be set to force the joins.
(2) For joins that ignore the time order of the data, a join engine:
- Calculates and outputs immediately when a record is ingested;
- OR waits until a record is matched. Additional timeout triggers can be set to force the joins.
The join and trigger rules determine the calculation results of the engine. We will explain the behavior of each join engine and elaborate the application scenarios separately in corresponding page.
Comparison of Join Engines
| Engine | Join Behavior | Join Column | Similar SQL Join | Number of Result Records | Application |
|---|---|---|---|---|---|
| asof join engine | Joins each record from the left stream with the matching record having the closest (or equal) timestamp from the right table. | matchingColumn | asof join | less than or equal to the number of left records | Calculating Transaction Costs |
| window join engine | Joins each record from the left stream with the aggregated value of the matching records in the specified window over the right table. | matchingColumn | window join | less than or equal to the number of left records | Joining 3-min OHLC with Trades Data |
| equi join engine | Joins each record from the left or right stream with the latest matching record from the other table. | matchingColumn +timeColumn | equi join | equal to the number of matched records from the two tables (provided that the values of join columns are unique) | Combining Metrics in Data Sources Captured at One-Minute Interval |
| look up join engine | Joins each record from the left stream with the latest matching record from the right table. | matchingColumn | left join/equi join | equal to the number of left records by default | Joining Real-Time Market Data with Historical Daily Metrics |
| left semi join engine | Joins each record from the left stream with the first or last matching record from the right table. | matchingColumn | equi join | less than or equal to the number of left records | Joining Trades With Orders Data Correlating Individual Stocks to Index |
| snapshot join engine | Joins each record from both tables with either the latest matching record or with all matching records from the other table. | matchingColumn | inner join or full outer join | less than or equal to all records from two tables | Joining account holdings with market prices to assess risk metrics such as leverage and net worth. |
Conclusion
In conclusion, DolphinDB offers built-in engines to enable efficient streaming joins with real-time triggering mechanism and memory management. Developers can easily implement complex real-time streaming joins through easy-to-configure parameters. Featuring streaming engines, stream pipeline processing, and parallel computing, the DolphinDB streaming framework can be applied to real-time business scenarios, providing timely insights and enabling faster decision-making.