Stream Tables
DolphinDB uses stream tables for storing, publishing, and subscribing to streaming data. Stream tables serve as simplified messaging middleware or subscription topics, allowing users to both publish and subscribe to data streams. Inserting a record into a stream table is equivalent to publishing a message from the data source.
Stream tables are essentially specialized in-memory tables. They support table query with SQL statements. The key distinction is that records in stream tables cannot be modified or deleted.
To address different stream processing scenarios, DolphinDB offers several functions for creating different types of stream tables:
| Table | Function | Primary Key | Max In-Mem Record Limit |
|---|---|---|---|
| Non-Persisted Stream Table | streamTable | × | × |
| keyedStreamTable, latestKeyedStreamTable | √ | × | |
| enableTableCachePurge, enableTableShareAndCachePurge | × | √ | |
| Persisted Stream Table | enableTablePersistence, enableTableShareAndPersistence | × | √ |
| haStreamTable | √ | √ |
Sharing Stream Tables
To publish streaming data, you can create a stream table and share it across sessions
using the share function or share statement.
Multiple subscribers in different sessions can subscribe to the same stream table.
Shared stream tables are designed to be thread-safe, supporting concurrent read and
write operations. Real-time data written to this table will be published to all
subscribers.
The following example demonstrates the workflow of creation, querying and deletion of a stream table:
First create and share a stream table:
colNames = ["code", "tradetime", "price"]
colTypes = [SYMBOL, TIMESTAMP, DOUBLE]
share(table=streamTable(1:0, colNames, colTypes), sharedName="pubTable")Write mock data to the stream table:
tableInsert(pubTable, "000001SZ", 2023.12.15T09:30:00.000, 10.5)
tableInsert(pubTable, "000001SZ", 2023.12.15T09:31:00.000, 10.6)
tableInsert(pubTable, "000001SZ", 2023.12.15T09:32:00.000, 10.7)
tableInsert(pubTable, "000001SZ", 2023.12.15T09:33:00.000, 10.8)
tableInsert(pubTable, "000001SZ", 2023.12.15T09:34:00.000, 10.7)
tableInsert(pubTable, "000001SZ", 2023.12.15T09:35:00.000, 10.6)Query the table with SQL statement:
res = select * from pubTable where price>=10.7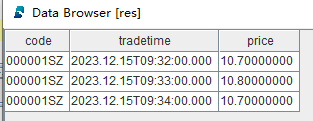
Execute the following script to draw a plot based on the input data:
price = exec price from pubTable
tradetime = exec tradetime from pubTable
plot(price, tradetime, title="minute price", chartType=LINE)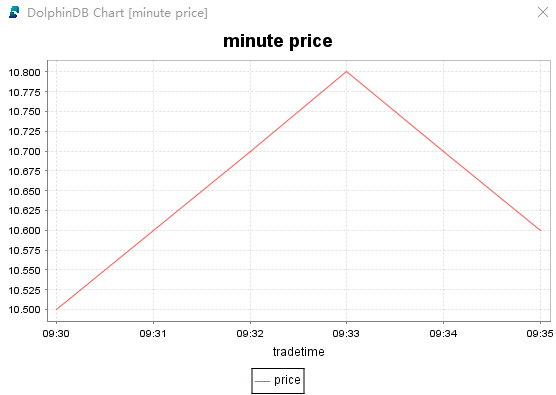
Use the following script to delete a stream table:
dropStreamTable(tableName="pubTable")Regular Stream Tables
A shared stream table publishes each data entry without deduplication. By default,
all data of a regular stream table is retained in memory, and published or expired
data will not be removed automatically. You can use
enableTableCachePurge or
enableTableShareAndCachePurge to enable automatic cleanup.
Create and share a regular stream table:
colNames = ["code", "tradetime", "price"]
colTypes = [SYMBOL, TIMESTAMP, DOUBLE]
share(table=streamTable(1:0, colNames, colTypes), sharedName="pubTable")Enable cache purge for this table:
enableTableCachePurge(table=pubTable, cacheSize=1000)Delete the stream table:
dropStreamTable(tableName="pubTable")Keyed Stream Tables
Keyed stream data tables are divided into two types:
keyedStreamTable and
latestKeyedStreamTable.
keyedStreamTable
A shared keyed stream table ensures that if data with the same primary key is written, only the first entry is retained, and subsequent records with the same key are discarded. Like regular stream tables, all data is retained in memory without automatic cleanup.
Create and share a keyed stream table with key column code and tradetime:
colNames = ["code", "tradetime", "price"]
colTypes = [SYMBOL, TIMESTAMP, DOUBLE]
share(table=keyedStreamTable(`code`tradetime, 1:0, colNames, colTypes), sharedName="pubTable")Write data with duplicate key entries:
tableInsert(pubTable, "000001SZ", 2023.12.15T09:30:00.000, 10.5)
tableInsert(pubTable, "000001SZ", 2023.12.15T09:30:00.000, 10.6)Query the table for the key "000001SZ":
res = select * from pubTable where code = "000001SZ"As can be seen from the query result, only the first record is written to the table.
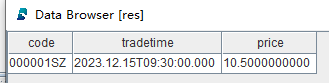
Delete the stream table:
dropStreamTable(tableName="pubTable")latestKeyedStreamTable
latestKeyedStreamTable extends keyedStreamTable by
adding a time column, which is used to determine whether a record should be written
based on its timestamp. For details, see latestKeyedStreamTable.
Persisting Stream Tables
DolphinDB keeps all data of stream tables in memory by default. Data stored in these tables cannot be recovered after a node restart. To prevent memory exhaustion from growing streaming data, DolphinDB offers stream table persistence to disk, which is suitable for environments with limited memory.
To enable persistence, first configure the persistenceDir parameter on the
publisher node. Then, use enableTableShareAndPersistence to share
and persist the table, or persist a shared stream table with
enableTablePersistence. Key parameters affecting performance
include:
- asynWrite: Enables asynchronous disk writes, improving throughput at the risk of data loss during restarts.
- compress: Compresses data before storage, reducing disk usage but potentially slowing write speeds.
- cacheSize: Limits the maximum in-memory records for data safety.
- flushMode: Controls synchronous disk flushing, ensuring data integrity at the cost of write speed.
- preCache: Specifies the number of records to be loaded into memory from the persisted stream table on disk when DolphinDB restarts.
Enabling stream table persistence offers several advantages:
- Prevents memory shortages by keeping only recent data in memory.
- Allows table reloading after unexpected node restarts.
- Enables subscriptions to resume from specified offsets.
Regular Stream Tables
Create, share and persist a regular stream table:
colNames = ["code", "tradetime", "price"]
colTypes = [SYMBOL, TIMESTAMP, DOUBLE]
enableTableShareAndPersistence(table=streamTable(1:0, colNames, colTypes), tableName="pubTable", cacheSize=10000, preCache=1000)Write 10000 records to the table:
rowNums = 10000
simulateData = table(
take(`000001SZ, rowNums) as code,
take(0..(rowNums-1), rowNums)*1000*3+2023.12.15T09:30:00.000 as tradetime,
take(10.6, rowNums) as price)
tableInsert(pubTable, simulateData)Check the number of records in the table:
select count(*) from pubTable
// output: 10000Then write 3000 records to the table:
rowNums = 3000
simulateData = table(
take(`000001SZ, rowNums) as code,
take(0..(rowNums-1), rowNums)*1000*3+2023.12.15T17:49:57.000 as tradetime,
take(10.6, rowNums) as price)
tableInsert(pubTable, simulateData)Check the number of records in the table:
select count(*) from pubTable
// output: 8000The result shows that 5000 older records are persisted to disk.
Delete the persisted stream table:
dropStreamTable(tableName="pubTable")Keyed Stream Tables
Create, share and persist a keyed stream table:
colNames = ["code", "tradetime", "price"]
colTypes = [SYMBOL, TIMESTAMP, DOUBLE]
enableTableShareAndPersistence(table=keyedStreamTable(`code`tradetime, 1:0, colNames, colTypes), tableName="pubTable", cacheSize=10000, preCache=1000)Delete the persistent stream table:
dropStreamTable(tableName="pubTable")High Availability of Stream Tables
A HA stream table is created using the haStreamTable function.
High-availability stream tables are suitable for scenarios that require continuous
data availability and recovery after failures. Key features include:
- The table is automatically shared without using the
sharefunction. - The table is persisted, meaning data can be restored after a node restart.
- It allows setting the maximum number of rows to retain in memory.
For more detailed instructions on configuring high-availability stream tables, please refer to haStreamTable.