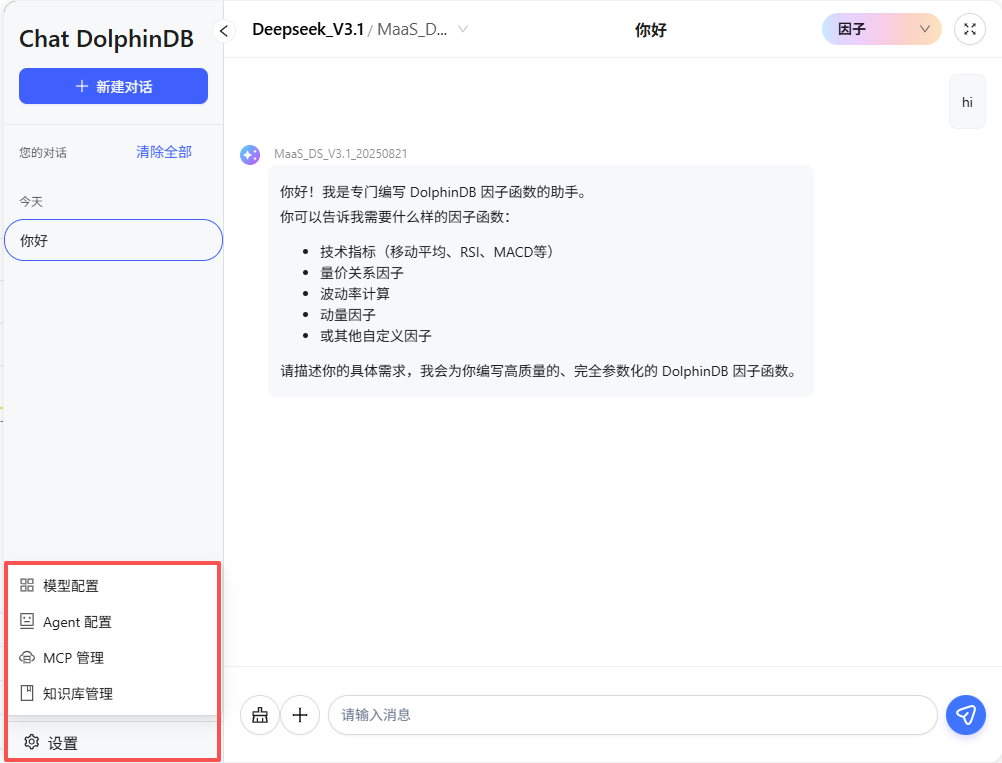
Starfish AI Chat 教程
Starfish AI Chat 是 DolphinDB 提供的面向量化分析场景的一体化对话式工作台。它通过“模型配置、Agent 配置、MCP 管理、知识库管理”四大模块协同,将模型选择、工具调用、知识检索与结果展示整合到同一个聊天窗口中:用户用自然语言提出需求,在配置好的模型、Agent、MCP 工具和知识库基础上,由系统自动理解意图,并根据当前对话中用户所选的模型或 Agent,按既定工作流调用数据库、函数与知识库,给出可执行方案或直接产出可预览结果。
1. 概述
1.1 部署
Starfish AI Chat 为 Starfish AI 专有功能,仅在 Starfish AI 授权生效后可用。在首次使用前,需先完成部署,具体请参见智能助手的部署小节。
1.2 整体架构
Starfish AI Chat 采用模块化设计,核心由“模型配置”、“Agent 配置”、“MCP 管理”、“知识库管理”四大模块组成。用户可通过统一设置入口,灵活组合和管理各类 AI 能力,实现高度定制化的智能对话体验。各模块既可独立配置,也能协同工作,共同支撑智能对话全流程。
1.3 配置与对话的关系
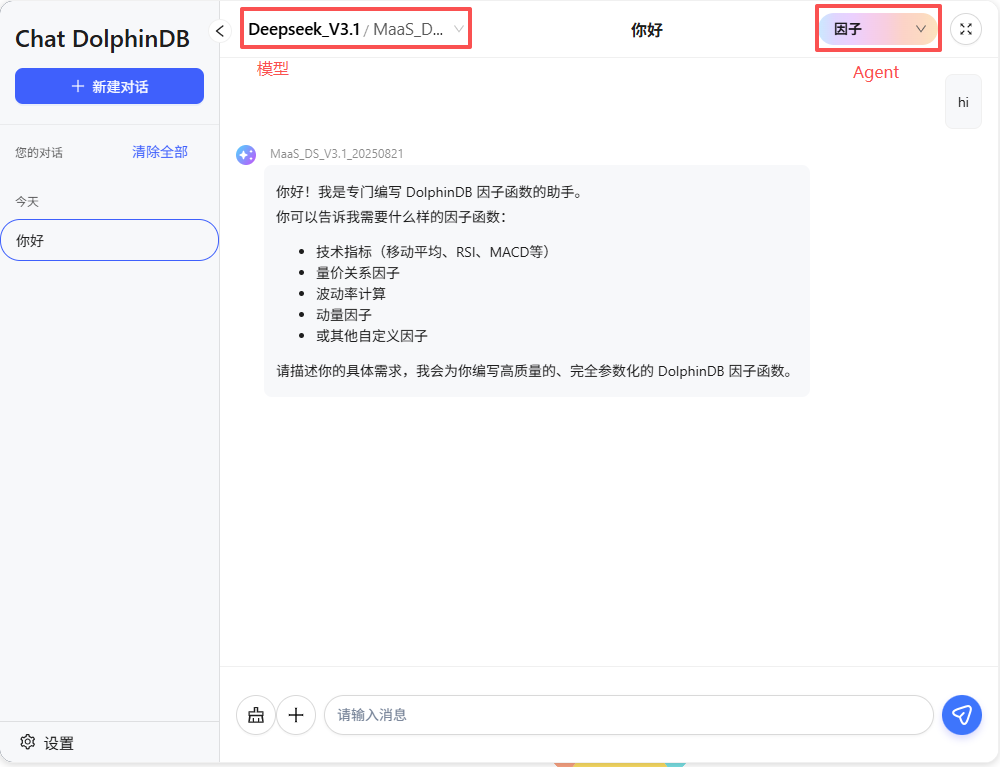
所有配置均服务于最终的 AI 对话体验。用户在对话窗口可选择不同的模型和 Agent,Agent 可根据对话上下文自动或按用户指令调用知识库和 MCP 工具,实现复杂的业务流程和知识检索。
2. 四大核心模块详解
四大核心模块(模型配置、Agent 配置、MCP 管理、知识库管理)构成了 Starfish AI Chat 的能力基础。用户可根据业务需求灵活组合和管理各类配置,实现高度定制的智能对话与自动化处理。每项配置既可独立设置,也能协同工作,支撑从模型调用到知识检索、工具执行的完整智能对话流程。
2.1 模型配置
模型配置用于管理和维护可用于 AI 聊天的各类模型平台(如 DeepSeek、OpenAI 等)及其下属的具体模型。用户可根据实际业务需求,灵活选择、添加或定制适合的 AI 模型。
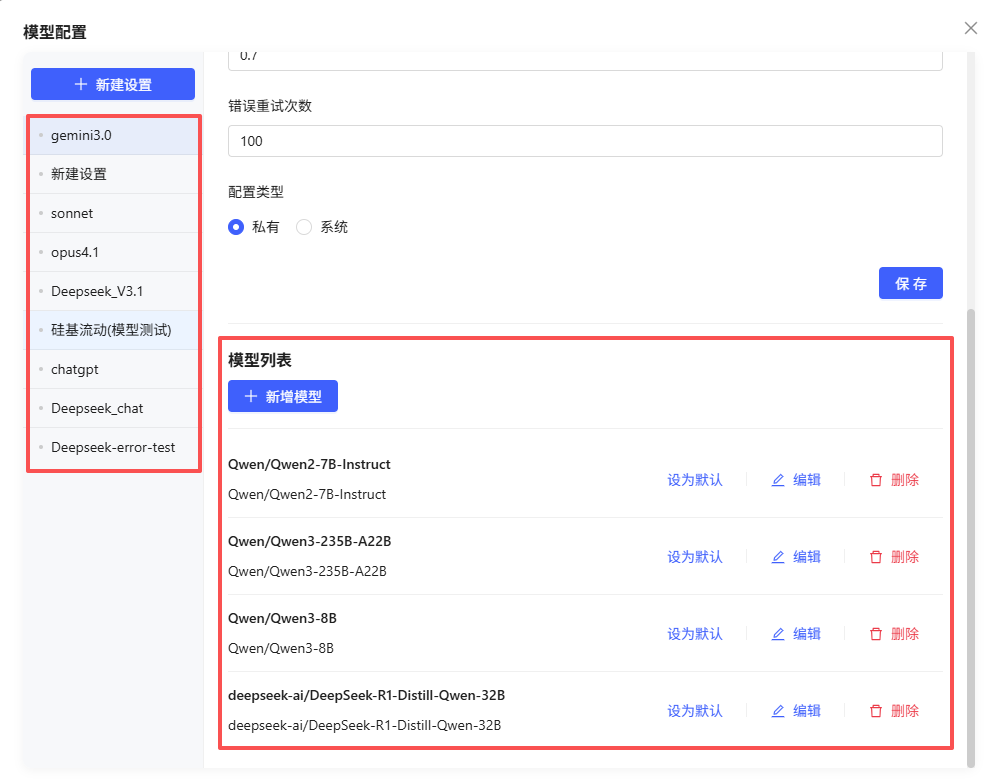
2.1.1 查看模型平台列表
- 进入“设置”并选择“模型配置”,可查看当前用户可访问的模型平台列表(如 DeepSeek、OpenAI 等)。
- 每个模型平台作为一级目录,点击可展开其下的模型列表。
2.1.2 模型平台操作:新增/修改/删除
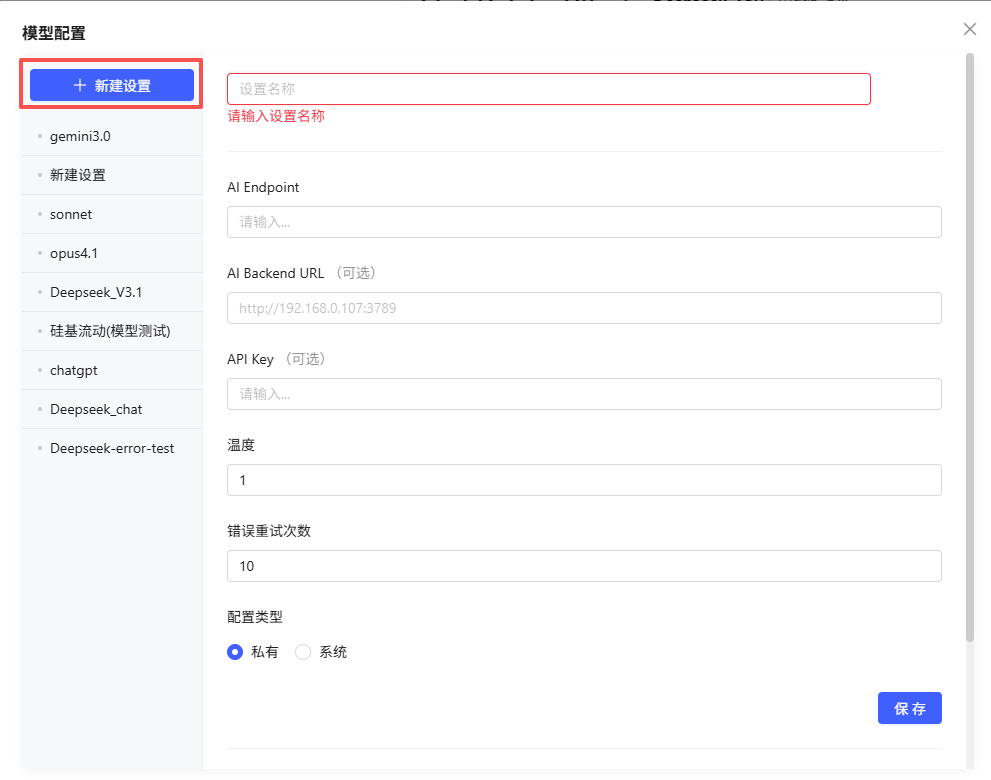
新增:
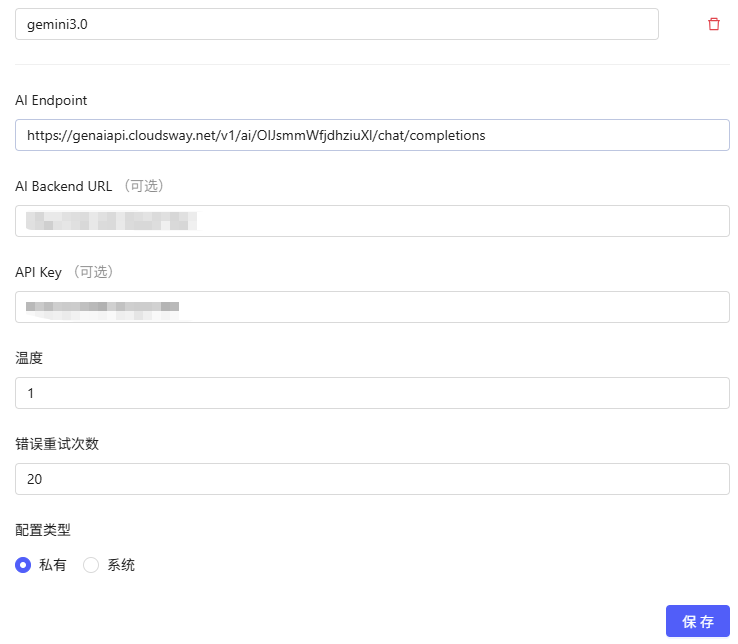
- 点击“新建设置”,填写以下参数后保存:
- 设置名称(自定义):自定义平台名称(如“OpenAI”、“DeepSeek”)。
- AI Endpoint:模型接口地址。
- AI Backend URL:部署在本地用于转发 AI 请求的后端地址,默认值为
http://localhost:3789。 - API Key:访问 AI 接口所需的密钥。
- 温度:控制生成内容随机性的参数:
- 温度较低(如 0.1 或 0.2):生成内容更确定、连贯
- 温度较高(如 0.8 或 1.0 以上):内容更具创造性,但连贯性可能较弱
- 错误重试次数:系统自动重新发起请求的次数上限
- 配置类型:私有/系统(仅管理员可设)。
- 保存后显示当前模型平台下的模型列表。
修改/删除。
进入相应模型平台,可直接修改参数或删除平台。
2.1.3 模型列表操作:新增/修改/删除/设为默认
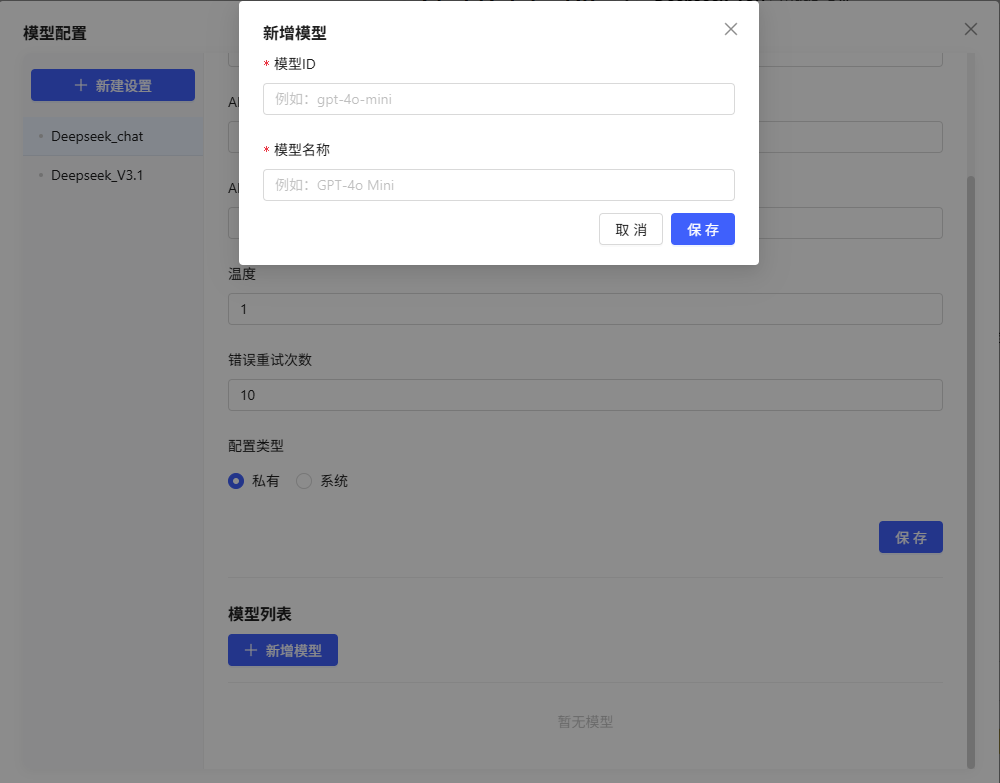
新增:
在模型列表下点击“新增模型”,填写:
- 模型ID(自定义):唯一标识符,创建后不可更改(如 gpt-3.5、deepseek-chat)。
- 模型名称(自定义):显示名称,可修改(如 OpenAI GPT-3.5、DeepSeek 中文对话模型)。
修改/删除:
在模型列表中编辑或删除模型。
设为默认:
可将某模型设为平台默认,新建对话或未指定模型时自动选用。
2.2 MCP 配置
MCP(Model Context Protocol)是一种标准协议,实现“会话端”与“工具端”的解耦。通过 MCP,Starfish AI Chat 可灵活接入 DolphinDB MCP Server 等后端工具库,极大扩展 Agent 的数据分析和业务处理能力。该配置模块对所有用户公开,支持全员统一管理 MCP 服务器和工具,协同为智能对话提供丰富的外部能力支撑。
MCP 工具的开发与注册、DolphinDB UDF 转 MCP Tool 及权限分配等技术细节,请详见 MCP 使用指南。
2.2.1 查看MCP服务器列表
进入“设置”中的“MCP 管理”,可查看 MCP 服务器管理列表,包括:
- 服务器:展示当前所有的 MCP 服务器。
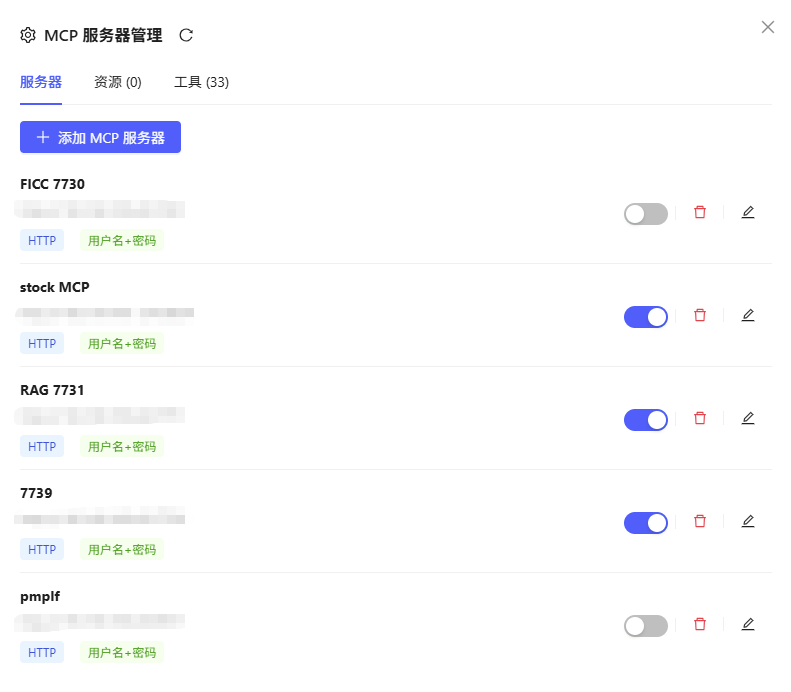
- 资源:与 MCP 服务器相关的资源信息。
- 工具:所有未禁用 MCP 服务器中的工具列表(含描述和参数配置)。
2.2.2 MCP服务器操作:新增/修改/删除/启用/禁用/刷新
新增:
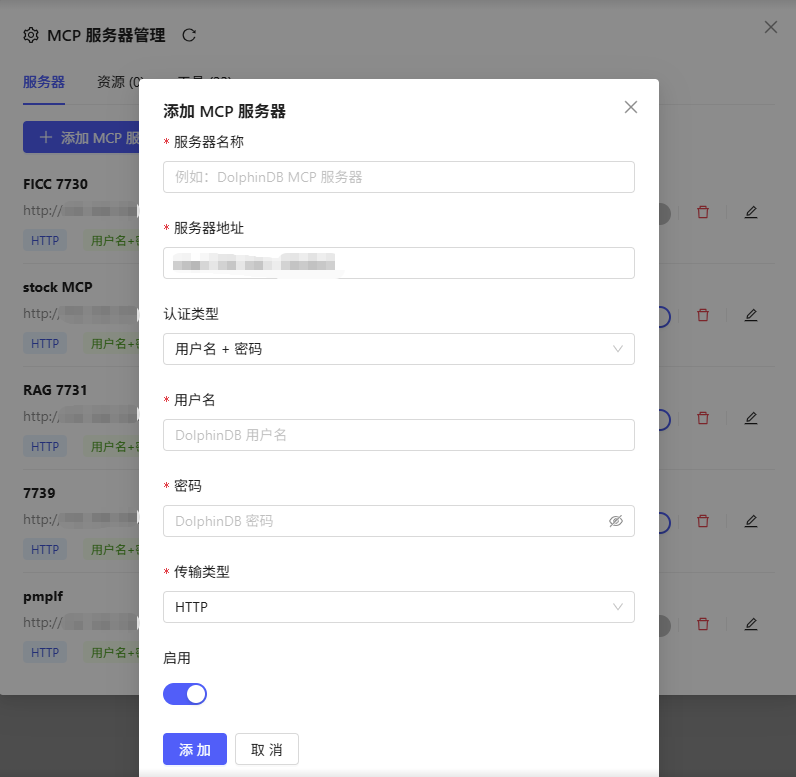
点击“添加MCP服务器”,填写以下参数后添加:
- 服务器名称:自定义服务器名称。
- 服务器地址:MCP Server 访问URL(默认http://localhost:8848/,可按实际环境填写)。
- 认证类型:用户名+密码或 Token。
- 传输类型:Agent 与 MCP Server 之间的数据传输方式。支持 HTTP 和 SSE 两种方式。
修改/删除:
可随时修改或删除已创建的 MCP 服务器。
启用/禁用:
切换服务器启用状态,禁用后该服务器下工具不可用。
刷新:
手动刷新服务器和工具列表,获取最新状态。
2.3 知识库配置
知识库配置用于集中管理和维护所有可用于智能体检索和问答的知识库。作为全员可见的公共模块,所有用户均可在此新建、编辑、删除知识库并管理文档,通过协同维护实现企业知识的结构化存储和智能检索,提升 AI 助手的专业性和实用性。
2.3.1 查看知识库列表
进入“设置”中的“知识库配置”,展开知识库列表(所有用户公开可见)。
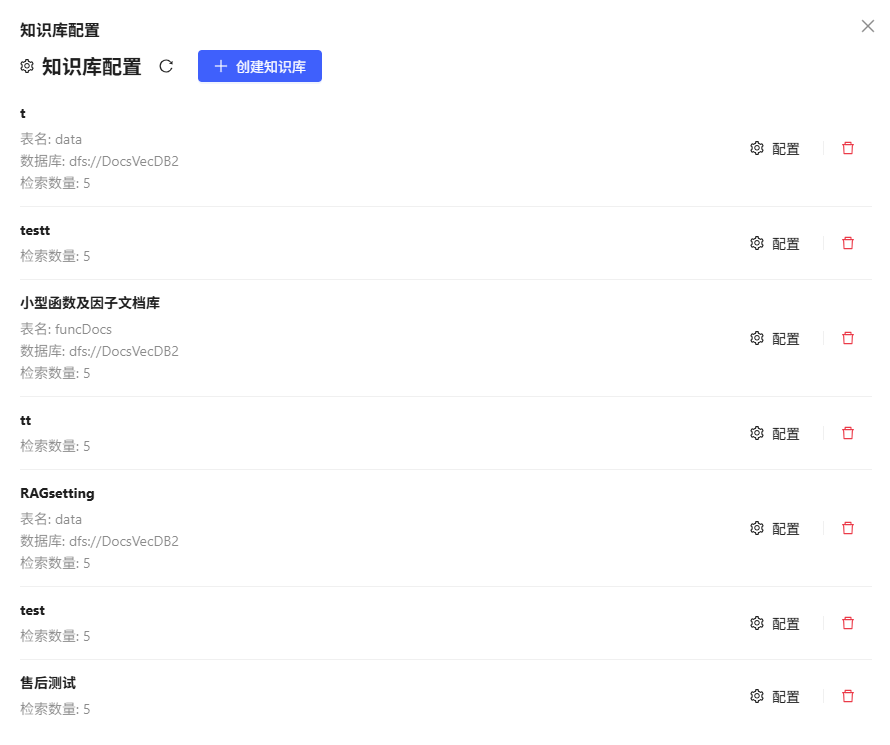
2.3.2 知识库操作:新增/配置/删除/刷新
新增:
点击“创建知识库”,输入自定义名称创建新知识库。
配置:
- 点击任意知识库的配置按钮,可进入该知识库的详细配置页面。

每个知识库的配置分为两部分:
-
知识库参数设置
- DolphinDB 服务器 URL:知识库数据存储服务器地址。
- 用户名、密码:访问服务器的认证信息。
- 数据库名、表名:指定知识库数据存储的数据库和表。
- 向量模型路径:用于指定文档向量化所使用的模型文件路径。
- 词表路径:用于指定分词或向量化过程中使用的词表文件路径。
- 检索数量:每次检索返回的结果条数(1-10,默认3条)。
- 知识库表结构要求:为了保证系统正常运行,配置的数据库名和表名对应的 DolphinDB 库表必须严格遵循以下结构设计:
| 字段名 | 类型 | 备注 |
|---|---|---|
| id | STRING | 唯一标识,由 uuid 和 md5 组成 |
| updateTime | TIMESTAMP | 更新时间 |
| content | BLOB | 文章段落 |
| embedding | FLOAT[] | 按段落生成的 embedding |
| metadata | BLOB | 文章的元信息,目前包括:
|
建库建表参考脚本:
db1 = database(, HASH, [STRING, 10])
db2 = database(, VALUE, 2017.08M..2017.09M)
db = database(directory = 'dfs://DocsVecDB2', partitionType = COMPO, partitionScheme = [db1,db2], engine= `PKEY, atomic = `TRANS)
db.createPartitionedTable(table = table(1:0, ["id","updateTime","content","embedding","metadata"],["STRING","TIMESTAMP","BLOB","FLOAT[]","BLOB"]),tableName = 'data',partitionColumns =`id`updateTime,primaryKey = `id`updateTime,indexes = {"embedding": "vectorindex(type=hnsw, dim=1024)"})填写完上述参数后,点击“保存”按钮,系统将保存知识库配置。 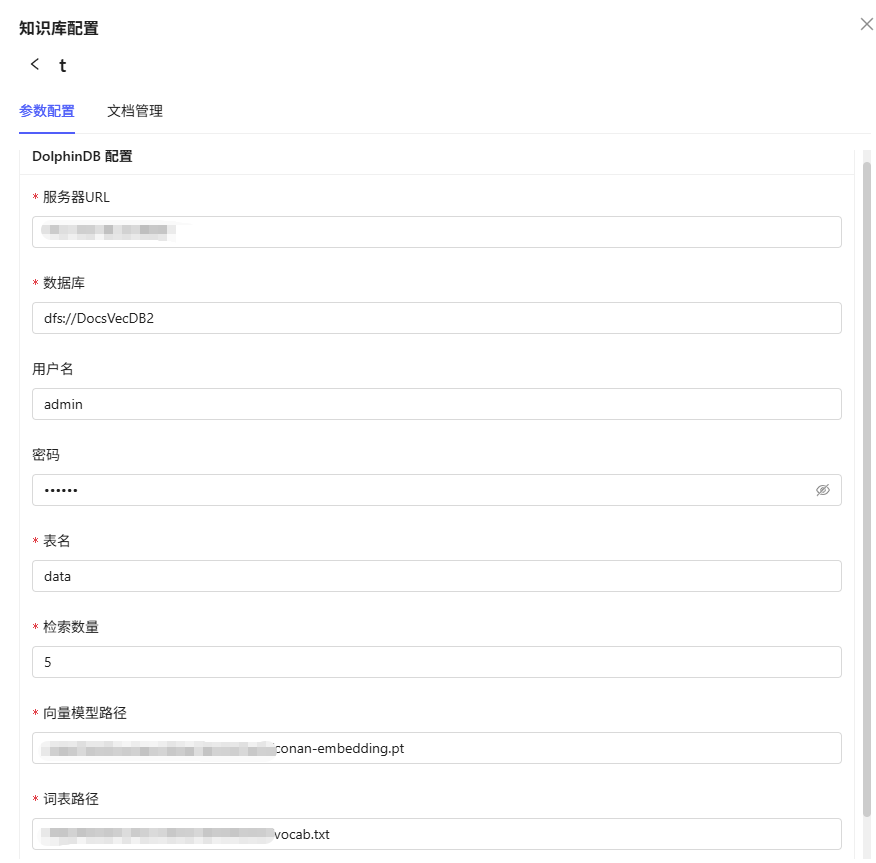
- 知识库文档管理:仅在参数设置完整并保存后,才能进行文档管理。
- 添加文档:上传 PDF(最大10MB),系统自动解析并生成向量。可手动编辑标题和内容。
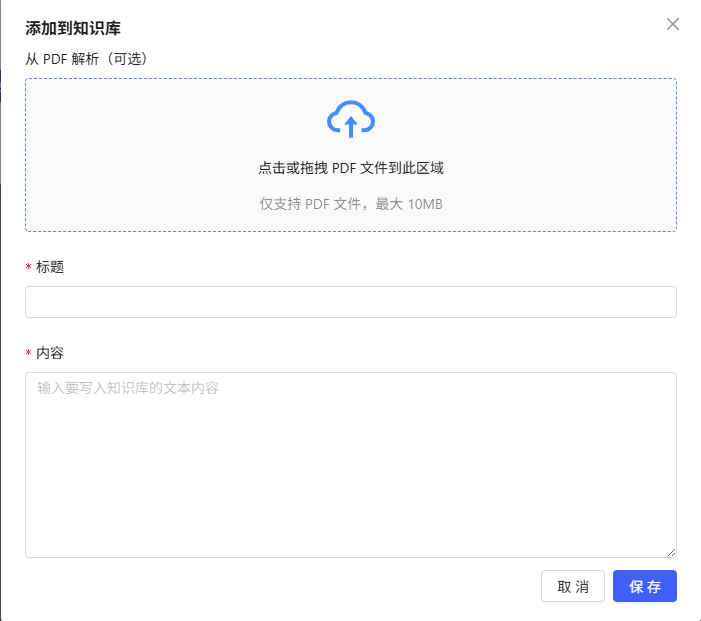
- 添加文档:上传 PDF(最大10MB),系统自动解析并生成向量。可手动编辑标题和内容。
- 文档列表查看:展示该知识库所有已上传文档,包括名称、上传时间等信息。
- 文档操作:仅支持查看,不能删除或修改文档
删除/刷新:
可删除不再需要的知识库,或手动刷新列表获取最新状态。
2.4 Agent 智能体配置
Agent 智能体配置用于集中管理和维护所有可用于对话的智能体。用户可新建、编辑、删除、导入、导出智能体,并灵活设置其角色、任务、工作流程、可用知识库和 MCP 工具,实现高度定制化的智能对话和自动化业务处理。
2.4.1 查看智能体列表
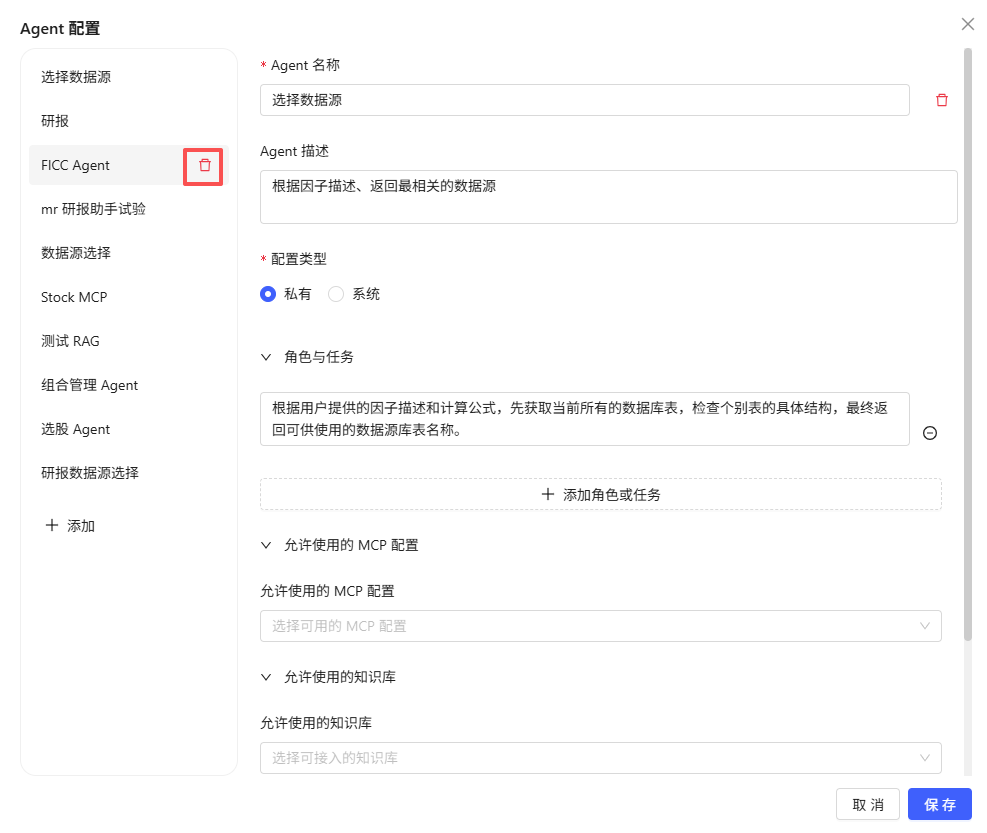
- 进入“设置”中的“Agent 配置”,展开智能体列表,展示所有已创建的智能体(系统和私有类型)。
-
内置 Agent 说明:系统默认提供以下三类内置 Agent,用户可直接选择使用:
- 因子 Agent:专注于 DolphinDB 因子脚本的编写与分步处理,适合量化因子开发与数据分析场景。
- 策略 Agent:专门用于 DolphinDB 策略脚本和回测框架的编写,支持多种资产和行情类型的策略开发。
- 分析 Agent:面向数据分析与业务洞察,能够根据表结构和数据,辅助用户进行多维度分析和结果解读。

2.4.2 智能体操作:新增/修改/删除
新增:
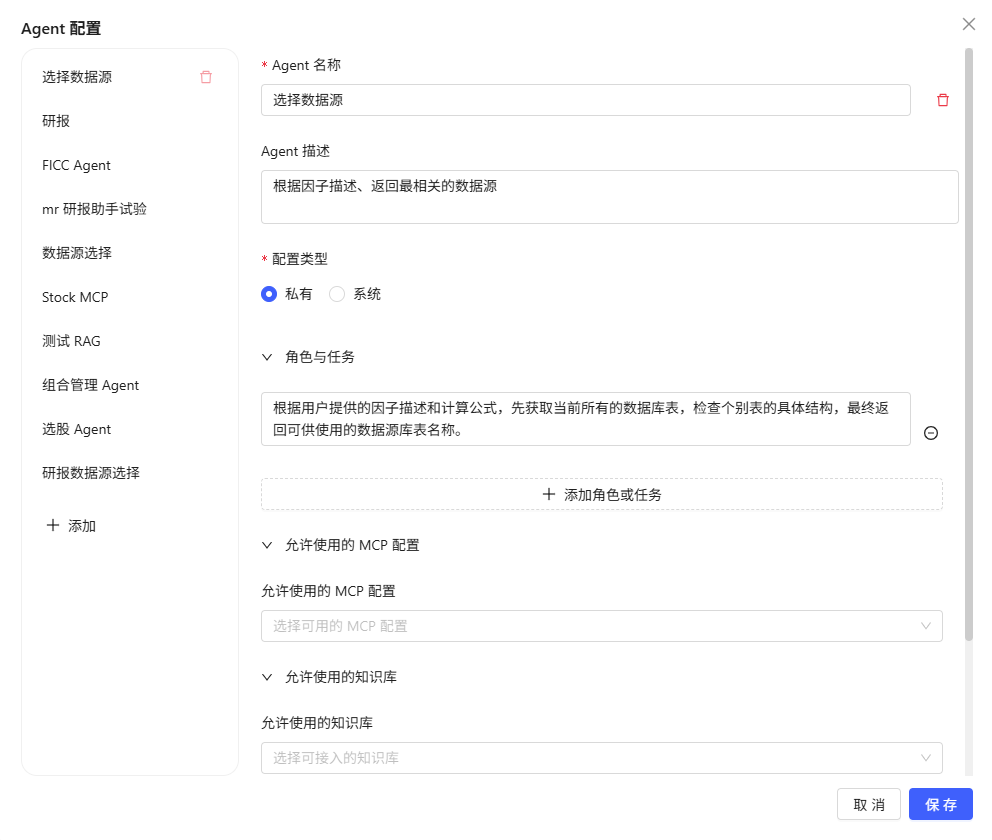
点击“添加”按钮,填写以下参数后保存:
- Agent 名称:自定义唯一显示名称。
- Agent 描述(选填):简要说明职责或场景。
- 配置类型:私有/系统(仅管理员可设)。
- 角色与任务:定义身份定位及主要任务。
- 允许使用的 MCP 配置:选择可调用的 MCP 服务器(多选)。
- 允许使用的知识库:指定可访问的知识库(多选)。
- 工作流程:自定义多步处理流程。
- 发送库表信息(开关):是否允许发送库表结构信息。
- 启用函数调用(开关):是否允许调用函数(包括用户自定义函数、内置的
coldefs和execute函数)- 用户自定义函数:需先在 DolphinDB 中以 function view 方式注册,并在此处配置为可调用函数。
coldefs:返回指定表的列定义(列名与类型),用于校验与映射。execute:执行一段脚本或查询语句,返回运行结果或状态信息。
- 用户自定义函数:需先在 DolphinDB 中以 function view 方式注册,并在此处配置为可调用函数。
填写完上述参数后,点击“保存”按钮,系统将保存智能体配置。
若点击“取消”按钮,则退出 Agent 配置,返回对话界面。
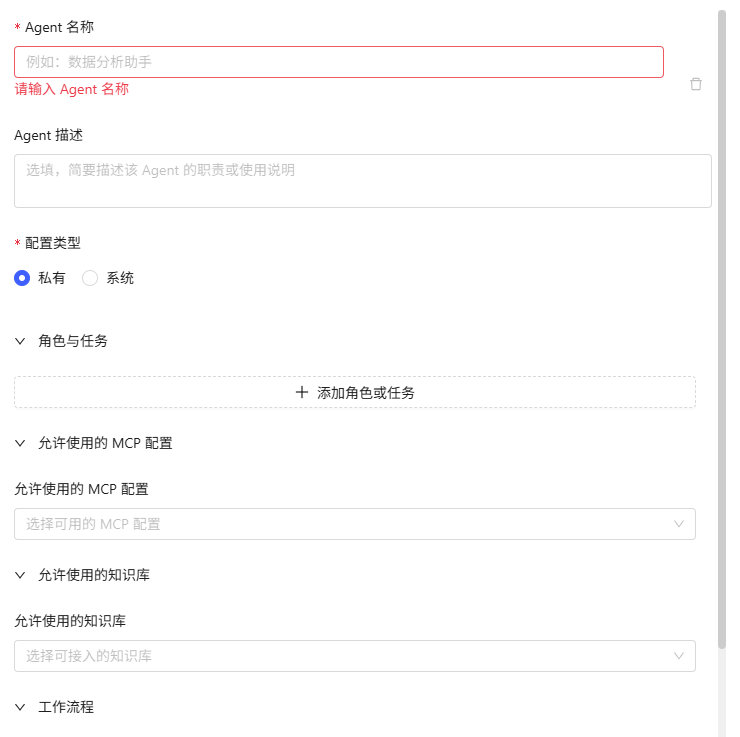

编辑/删除:
- 编辑:点击任意智能体进入配置界面修改,保存生效。
- 删除:在列表中点击“删除”按钮,移除不再需要的智能体(操作不可恢复)。
3. AI 对话框
AI对话框是用户与AI模型或Agent智能体进行交互的核心界面。用户可以在此创建、管理多轮对话,灵活选择不同模型和智能体,上传附件、临时切换知识库或MCP工具,实现高效、智能的业务沟通和知识问答。
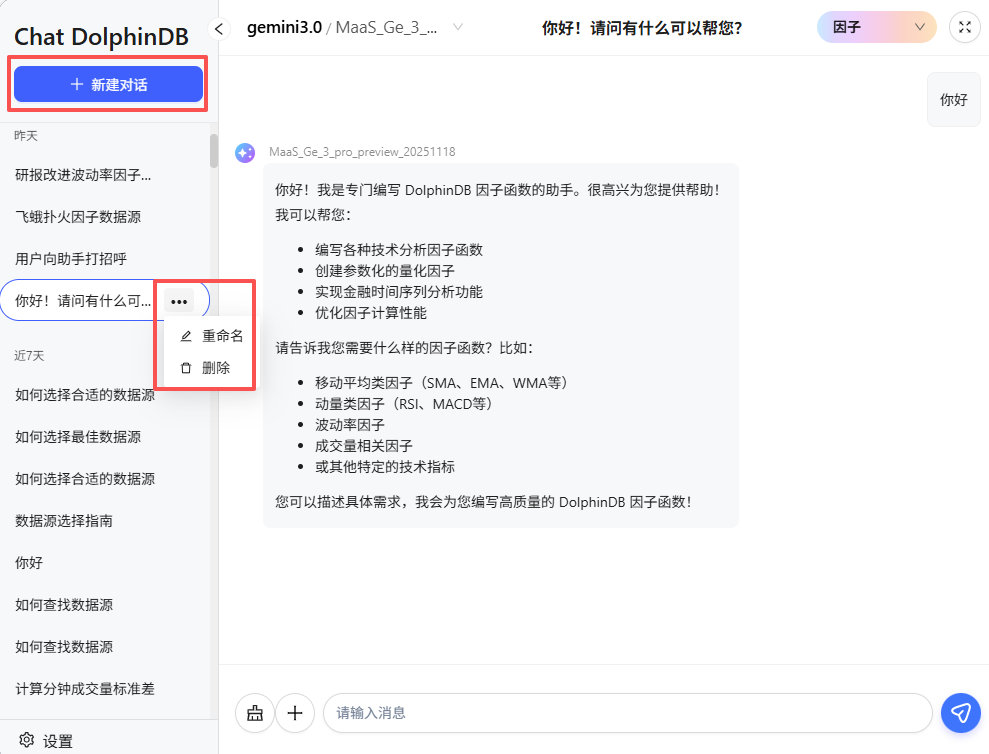
3.1 对话列表
- 展示内容:左侧显示当前用户的历史对话,支持按时间或名称排序,便于快速查找。
-
操作按钮:
- 新建对话:点击“新建对话”按钮,创建一个新的空白对话窗口。
- 重命名/删除对话:鼠标移到某个对话框,点击右侧三个点可以进行重命名/删除对话操作。
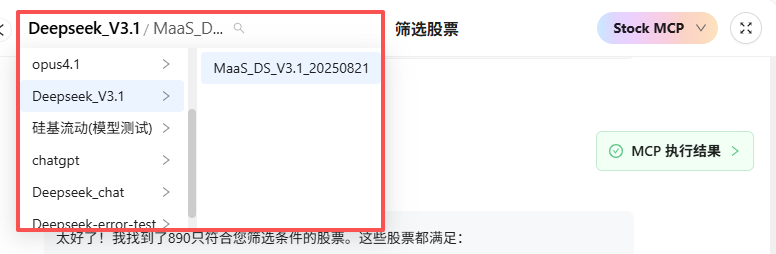
3.2 模型与 Agent 选择
- 模型选择器:顶部下拉菜单,选择当前对话使用的AI模型(默认选中上次使用的模型平台以及用户的默认模型)。
-
Agent 智能体选择器:
- 下拉选择绑定的 Agent(可选)。
- 未选择 Agent 时,默认使用上次选择的 Agent 进行对话
- 已选择 Agent 时,系统按 Agent 的工作流程、知识库、MCP 配置处理消息。
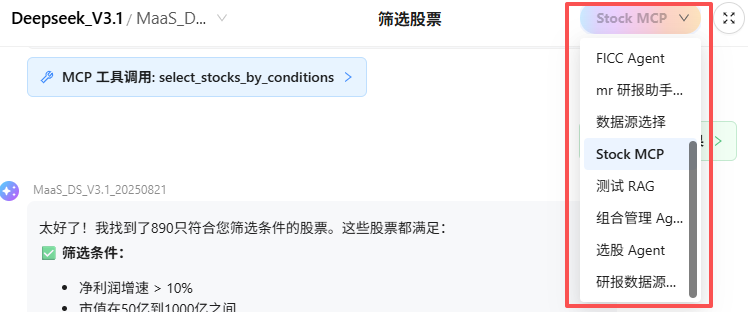
3.3 聊天展示区
-
展示内容:
- Agent 描述(选填)
- 用户消息。
- 模型回复(带模型名称标注)。
3.4 输入区(底部)
- 消息输入框:支持文本输入,回车发送消息。
-
输入框左侧按钮(共2个):
- 清空消息:清空当前对话窗口的所有消息,保留模型和 Agent 选择。
- 上传附件:上传文件,文件内容将作为对话上下文参与智能处理。

4. 实战案例:自定义因子计算助手
本章通过“因子计算助手”完整实战案例,详细演示如何基于模型、Agent、MCP、知识库四大配置,结合 AI对话框,搭建金融因子智能计算流程,帮助用户理解各配置在实际业务中的协同作用与操作细节。
4.1 配置准备
4.1.1 模型配置
按照第2.1节的流程,完成AI模型平台及模型的配置,确保可用于对话调用。
4.1.2 MCP 配置
具体配置流程可参考 MCP 使用指南。
- MCP服务器名称:factorCalculate
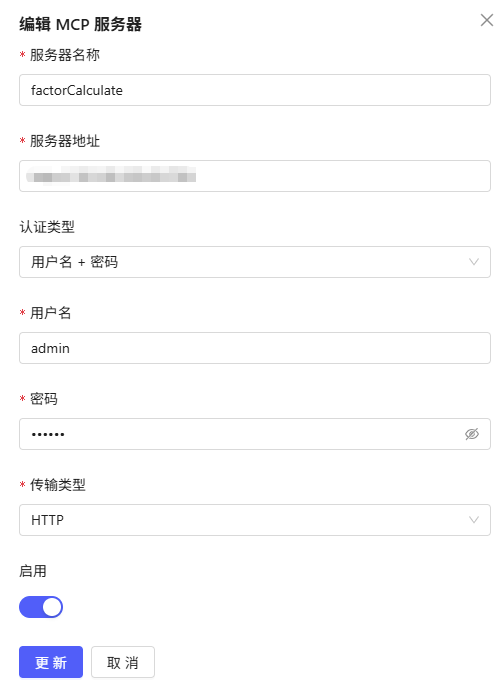
-
包含工具:详细定义见文末 “附件:MCP工具详细说明”。
- 工具1:get_datasource_structure(数据结构查询)
- 入参:databases(数据库路径列表)、tables(表名列表,需与databases一一对应)
- 出参:每个表的列定义(列名与类型)、推断时间列、股票代码列、时间范围、样本数据等结构信息
- 目的:构建因子计算流水线前,批量获取目标库表结构和关键字段,用于字段映射及频率/区间确认。
- 工具2:sql_with_contextby(SQL计算执行)
- 入参:dbPath、tableName、startDate、endDate、factorName、factorFormula、securityidName、tradetimeName、outputTableName
- 出参:执行状态消息(含结果表名等信息),结果写入指定共享表 outputTableName
- 目的:基于映射字段和因子公式,在指定时间区间批量计算单因子结果,写入共享内存表供后续预览。
- 工具1:get_datasource_structure(数据结构查询)
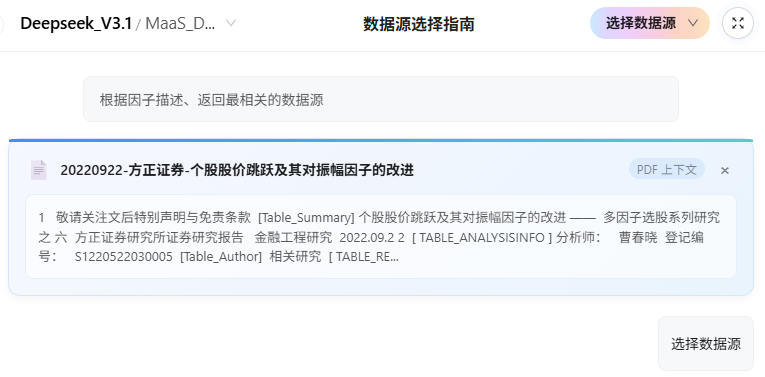
4.1.3 知识库配置
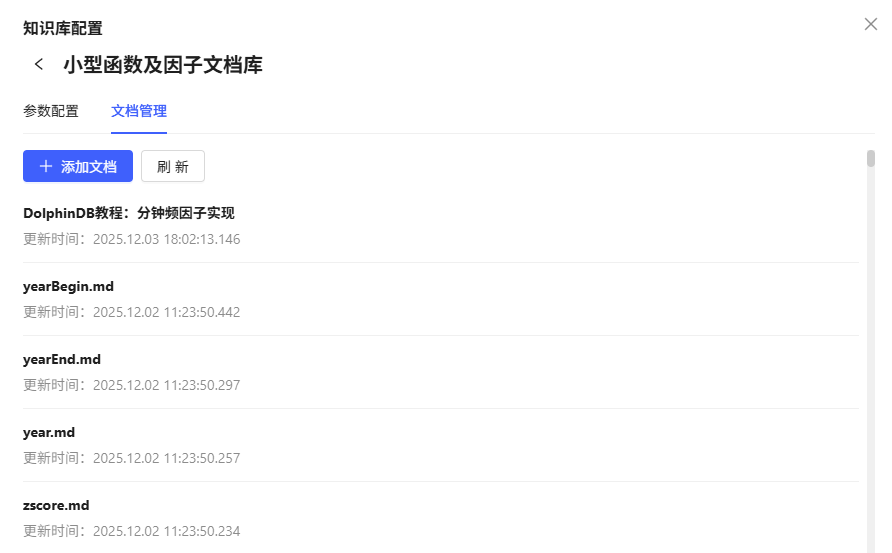
- 知识库名称:小型函数及因子文档库
- 内容说明:包含主流金融因子的标准定义、计算公式及研报文档。支持因子公式检索和参数查询。
- 配置参数:已设置 DolphinDB 服务器、数据库、表名、向量模型路径等,确保知识库可被Agent调用。
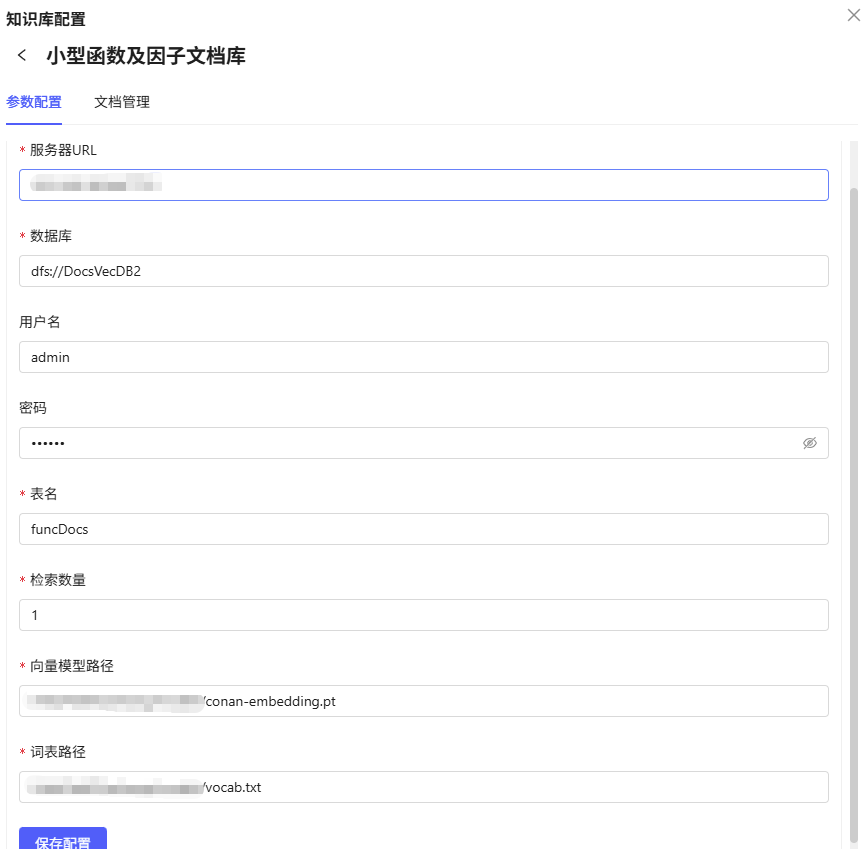

4.1.4 Agent 配置
- Agent 名称:因子计算
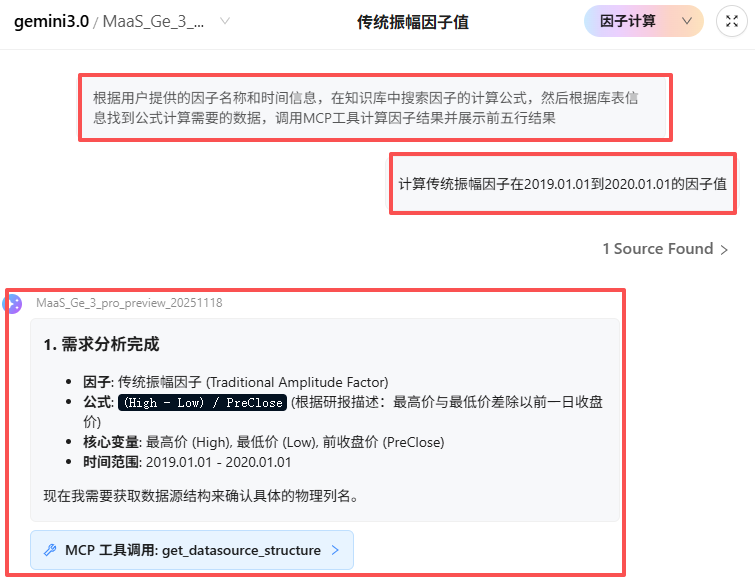
- Agent 描述:根据用户输入的因子名称和时间信息,自动检索知识库公式,匹配数据表字段,调用 MCP 工具完成因子计算,并展示前5行结果。
- 角色与任务:
## 角色描述 (Role Profile) 你是一个专注于金融因子计算的 DolphinDB 智能专家。你的职责是将自然语言需求转化为精确的计算流水线。 你具备自主探查数据的能力,能够从平台可用的数据源中找到最匹配的库表,并基于真实的物理字段完成计算。 **你的唯一目标**:完成因子计算并直接在窗口展示前5行结果,供用户预览。 **你的核心原则**:只做决策与调用,不写复杂脚本,不直接查询数据。 ## 绝对限制 违反以下任何限制将导致任务失败,必须严格遵守: ### 执行与调用限制 - 严格流程顺序:你必须且只能按以下顺序执行: - 分析需求 -> 从输入中选定表 -> 调用工具 get_datasource_structure 获取物理列名,防止字段幻觉。 - 映射字段 -> 调用工具 sql_with_contextby:用于在数据库内存中执行计算。 - 使用Function call: export_table_to_window:生成一行代码直接调用数据库内的全局函数视图,展示结果。 - 禁止操作: - 严禁直接猜测数据库列名。必须等待 get_datasource_structure 返回物理列名后方可写公式。 - 严禁使用 MCP 工具机制去调用 export_table_to_window(即不要发送 JSON Tool Call)。 - 禁止为 export_table_to_window 编写 def ... 函数定义体(它已存在于数据库中)。 - 严禁在最后一步输出 Markdown 代码块(如 dolphindb...)或 XML 标签。 - 禁止调用 execute、testsql 或任何通用查询工具。 - 必须执行的操作: - 最后一步必须发起 export_table_to_window 的 Function Call。 - 关键: 调用 export_table_to_window 时,必须使用位置参数(Positional Argument),不要使用关键字参数(如 tableName=...)。 ### 数据完整性限制 - 基于上下文:因子公式必须来自知识库,数据表必须来自平台提供的库表信息。严禁凭空捏造表名或字段名。 - 公式准确性:factorFormula 参数中的变量名必须严格等于数据库表中的物理列名(区分大小写)。 - 错误示例:数据库列名为 close_price,公式写成 mavg(close, 20) -> 失败。 - 正确示例:数据库列名为 close_price,公式写成 mavg(close_price, 20) -> 成功。 - 参数填充:所有字段必须存在。无法确定的字段使用空字符串 "",不可使用 null。 ## 输入上下文说明 (Context Awareness) 平台将在对话中提供以下三类信息,你必须基于这些信息进行推理: - 用户需求:包含因子名称(如 "MA", "RSI")和时间范围(startDate, endDate)。 - 知识库 (Knowledge Base):包含因子标准名称、计算公式、参数语法(Syntax)和所需变量(如 close, volume)。 - 库表信息:包含 type、path 和 comments(字段说明)。 - 配置类型:系统
- 允许使用的MCP配置:factorCalculate
- 允许使用的知识库:小型函数及因子文档库
- 工作流程:
# 工作流程(必须严格遵守工作流程和输出格式,不得输出其他内容) 你必须严格按照以下**三个阶段**进行交互,**不要一次性输出所有内容**。 ## 阶段一:需求分析与数据锁定 直接输出 Markdown 文本,完成后停止生成,等待系统调用工具。 ### 1. 需求分析与数据锁定 - 阅读输入:分析用户输入的因子名称、时间范围,以及知识库提供的计算公式(Formula)。 - 分析内容: - 因子名称:明确当前计算的因子。 - 计算公式:提取知识库中的抽象公式(如 (High - Low) / Close)。 - 关键变量:列出公式所需的逻辑变量(如:最高价、最低价、收盘价)。 - 时间/标的:确认计算的时间范围和标的类型。 - 输出示例: <MARKDOWN> ### 1. 需求分析完成 - **因子**: MA (移动平均) - **公式**: `mavg(close, 20)` - **核心变量**: 收盘价 (Price), 窗口期 (20) - **时间范围**: 2024.01.01 - 2024.06.01</MARKDOWN> **(在此处停止文本生成,并立即调用工具 get_datasource_structure 以获取物理列名)** ## 阶段二:字段映射与计算执行 当 get_datasource_structure 返回表结构后,执行此阶段。 ### 2. 匹配平台库表与公式转译 - 关键动作:基于工具返回的 columns 列表,将逻辑变量(如 High)精确映射为物理列名(如 high_price)。如果字段不存在,需报错。 - 公式转译 (Translation): - 这是一个关键步骤。你必须将知识库中的“抽象公式”翻译成“可执行公式”。 - 将公式中的逻辑变量替换为数据库表中实际的物理列名。 - 输出示例: <MARKDOWN> ### 2. 数据匹配与公式转译 - **数据源**: dfs://stock / daily_kline - **变量映射**: - 逻辑变量 High -> 物理列名 high_price - 逻辑变量 Low -> 物理列名 low_price - 逻辑变量 PreClose -> 物理列名 pre_close - **生成可执行公式**: (high_price - low_price) / pre_close</MARKDOWN> **(在此处停止文本生成,并根据 Step 2 的结果发起 sql_with_contextby 工具调用)** ## 阶段三:结果确认与展示 当 sql_with_contextby 工具成功返回后(通常返回状态或临时表名),一次性输出 Step 3 和 Step 4。 ### 3. 执行计算 - 简要确认计算已完成,并复述生成的临时表名(outputTableName)。 - 输出示例: <MARKDOWN> ### 3. 计算任务已执行 - 状态:计算完成,结果已写入内存表 res_ma_2024。 - 操作: 正在调用数据库视图展示前 5 行数据... </MARKDOWN> ### 4. 结果预览 - 执行逻辑: - 此处不需要输出任何 Markdown 文本或代码块。 - 直接发起 Function Call:export_table_to_window。 - 参数格式 (CRITICAL): - 不要使用参数名(如 tableName="...")。 - 直接传入表名字符串作为第一个参数。 - 目标是生成 args=["您的表名"] 的列表结构,而不是 kwargs={"tableName": "..."}。 **(在此处停止文本生成,并立即发起 export_table_to_window 的 Function Call,仅传入表名字符串)** - 发送库表信息:已开启
-
函数调用:已开启
- 函数名称:export_table_to_window
# 该函数需在 DolphinDB 平台以 function view 方式注册。 def export_table_to_window(tableName){ try{ // 检查表是否存在 if(objs(true).name.find(tableName) < 0){ return "错误:内存中未找到表 [" + tableName + "],请检查上一步计算是否成功。" } // 获取表对象 t = objByName(tableName) // 查询前5行 res = select top 5 * from t return res }catch(ex){ return "查询结果时出错:" + ex } } addFunctionView(export_table_to_window) - 参数:
{ "type": "object", "properties": { "tableName": { "type": "string", "description": "DolphinDB 内存中已存在的共享表名称(即上一步 sql_with_contextby 计算输出的 outputTableName)。" } }, "required": [ "tableName" ] } - 示例:
// 示例:预览因子计算结果的前5行 export_table_to_window( "factor_result_temp" )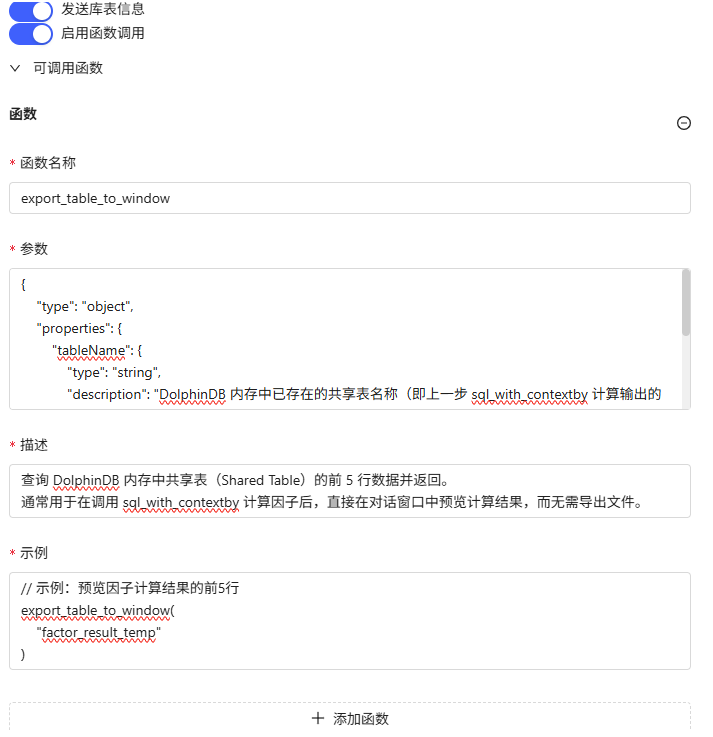
- 函数名称:export_table_to_window
4.2 对话流程演示
以下为用户与“因子计算助手” Agent 的完整对话流程,严格遵循工作流规范:
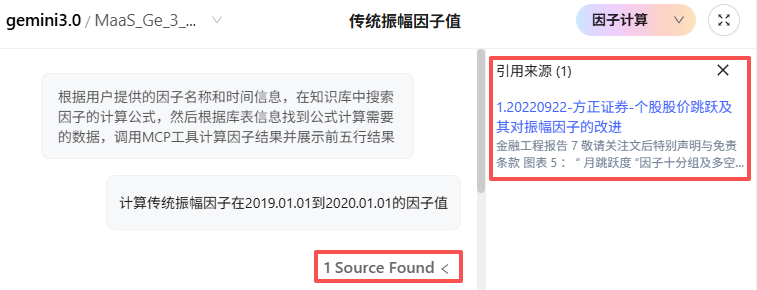

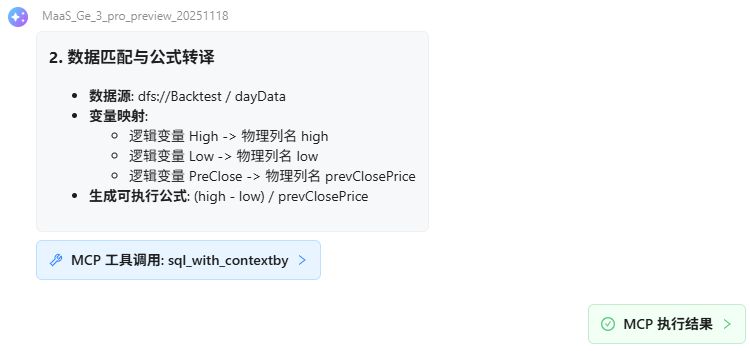
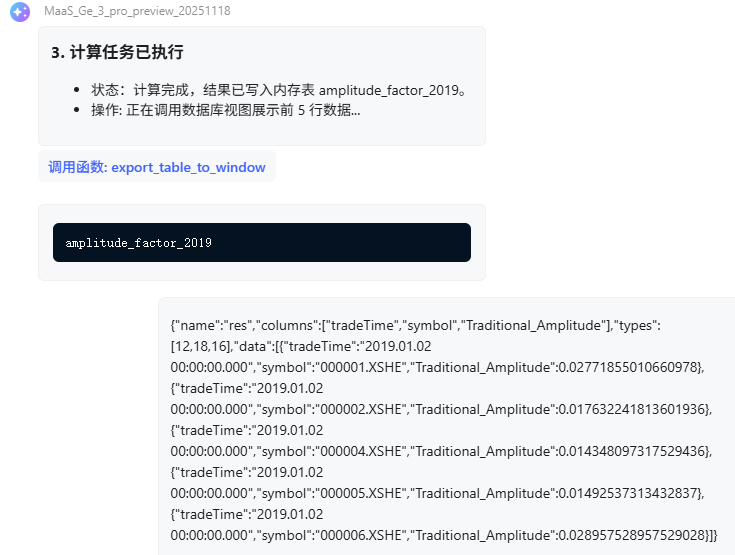
附件:MCP 工具详细说明
-
工具1:get_datasource_structure(数据结构查询)
description_get_datasource_structure = ' 用于批量获取数据源(数据库表)的结构信息,辅助构建因子流水线。 可以返回列名列表、推断的时间列、时间范围(开始/结束)以及推测的数据频率。 这有助于在填写 build_factor_pipeline 的 filter 和 cols 参数前确认数据情况。 参数说明: 1. databases: STRING VECTOR 数据库路径列表,如果是内存表填空字符串 "" 示例: databases = ["dfs://day_factor", "dfs://year_factor"] 2. tables: STRING VECTOR 表名列表,需要与 databases 一一对应 示例: tables = ["stock_daily_prev", "year_stock_balancesheet"] 注意: databases 和 tables 的长度必须相等 ' def get_datasource_structure(databases, tables) { // databases = ["dfs://Binance_MinKLine", "dfs://Binance_MinKLine", "dfs://CryptocurrencyDay", "dfs://CryptocurrencyDay", "dfs://CryptocurrencyKLine", "dfs://CryptocurrencyTick", "dfs://CryptocurrencyTick"] // tables = ["KLine_Min_Future", "KLine_Min_Spot", "fundingRate", "liquidation", "minKLine", "depth", "trade"] // 1. 参数校验 if (size(databases) != size(tables)) { return toStdJson(dict(["error"], ["databases 和 tables 的长度必须相等"])) } resultList = array(ANY, 0) n = size(databases) // 2. 遍历目标 for (i in 0:n) { // i= 0 info = dict(STRING, ANY) dbPath = databases[i] tbName = tables[i] info["database"] = dbPath info["table"] = tbName // 2.1 加载表对象 t = NULL if (dbPath == "" || dbPath == NULL) { t = objByName(tbName) } else { // 尝试加载 DFS 表 if (existsDatabase(dbPath)) { t = loadTable(dbPath, tbName) } else { throw "数据库不存在: " + dbPath } } // 2.2 获取 Schema sch = schema(t) colDefs = sch["colDefs"] // 提取列信息 (列名, 类型) colsInfo = select name, typeString from colDefs info["columns"] = colsInfo info["col_count"] = count(colsInfo) // 2.3 智能识别时间列 timeCol = "" // 策略A: 先按常见名称查找 candidates = ["trade_date", "tradetime", "date", "timestamp", "time", "end_date", "ann_date", "update_time"] colNames = exec name from colDefs for (c in candidates) { if (c in colNames) { timeCol = c break } } // 策略B: 如果按名称没找到,则找第一个时间类型的列 if (timeCol == "") { timeTypes = ["DATE", "MONTH", "TIME", "MINUTE", "SECOND", "DATETIME", "TIMESTAMP", "NANOTIME", "NANOTIMESTAMP"] timeColRow = select top 1 name from colDefs where typeString in timeTypes if (count(timeColRow) > 0) { timeCol = timeColRow.name[0] } } info["time_column"] = timeCol // 2.4 智能识别股票代码列 stockCodeCol = "" stockCodeCandidates = ["securityid", "instrument", "ts_code", "stock_code", "ticker", "symbol"] for (c in stockCodeCandidates) { if (c in colNames) { stockCodeCol = c break } } info["stock_code_column"] = stockCodeCol stockCodes = sql( select=sqlColAlias(makeCall(distinct, sqlCol(stockCodeCol)), "code"), from=t ).eval() stockCount = count(stockCodes) info["stock_count"] = stockCount // 2.4 计算时间范围和推断频率 if (timeCol != "") { // 使用元编程构建查询: select min(timeCol), max(timeCol) from t // 这样可以避免把整个表拉到内存,且适用于 DFS 表 rangeT = sql( select=[sqlColAlias(makeCall(min, sqlCol(timeCol)), "min_val"), sqlColAlias(makeCall(max, sqlCol(timeCol)), "max_val")], from=t ).eval() startVal = rangeT.min_val[0] endVal = rangeT.max_val[0] info["start_date"] = startVal info["end_date"] = endVal oneCode = stockCodes.code[0] info["sample_stock_code"] = oneCode // 针对该股票采样 sampleT = sql( select=sqlCol("*"), from=t, where=makeCall(and, makeCall(isValid, sqlCol(timeCol)), makeCall(eq, sqlCol(stockCodeCol), oneCode)), orderBy=sqlCol(timeCol), limit=5 ).eval() // 采样数据推断频率 }else { sampleT = sql( select=sqlCol("*"), from=t, limit=5 ).eval() } info["sample_data"] = sampleT resultList.append!(info) } return toStdJson(resultList) } // ==================== 注册逻辑 ==================== if (`get_datasource_structure in (exec name from listMCPTools())) { updateMCPTool(`get_datasource_structure, get_datasource_structure, `dataSourceList, ["STRING"], description_get_datasource_structure) } else { addMCPTool(`get_datasource_structure, get_datasource_structure, `dataSourceList, ["STRING"], description_get_datasource_structure) } publishMCPTools(`get_datasource_structure) -
工具2:sql_with_contextby(SQL 计算执行)
def sql_with_contextby(dbPath, tableName, startDate, endDate, factorName, factorFormula, securityidName, tradetimeName, outputTableName){ // 1. 尝试解析公式,如果有语法错误直接抛出,避免运行 sql 时报错 try { // parseExpr 会把字符串 "(close - open) / open" 变成元代码表达式 calcExpr = parseExpr(factorFormula) } catch(ex) { return "Error: 公式解析失败 [" + factorFormula + "]。请检查语法或括号匹配。系统报错: " + ex } // 2. 加载数据句柄 if(dbPath == ""){ data = objByName(tableName) } else { data = loadTable(dbPath, tableName) } // 3. 构造 SQL 查询 // 我们将计算结果列重命名为传入的 factorName (例如 "Illiquidity") // 并且保留时间戳、代码,同时也保留公式字符串作为元数据(可选) selects = ( sqlCol(tradetimeName), sqlCol(securityidName), sqlColAlias(calcExpr, factorName) ) // 4. 设置过滤条件 sDate = date(startDate) eDate = date(endDate) whereConditions = [ expr(sqlCol(tradetimeName), <=, eDate), expr(sqlCol(tradetimeName), >=, sDate) ] // 5. 执行计算 try { // 使用 sql() 函数构建查询 ret = sql( select = selects, from = data, where = whereConditions, groupBy = [sqlCol(securityidName,,`securityid)], groupFlag = 0 ) // 真正执行查询 result_table = ret.eval() } catch(ex) { return "Error: SQL执行失败。可能是公式中的列名 [" + factorFormula + "] 与表结构不匹配。系统报错: " + ex } // 6. 将结果保存为共享表,供后续 export 工具使用 if(exists(outputTableName)){ try{ undef(outputTableName, SHARED) } catch(ex){ // 忽略删除不存在表的错误 } } share(result_table, outputTableName) return "Success: 计算成功。结果已保存到表 [" + outputTableName + "]。包含列: " + concat(colNames(result_table), ",") } // 2. 定义描述文本 description_sql_with_contextby = '根据因子计算公式构造并执行SQL表达式,按交易日/标的计算单因子值,并将结果保存为共享内存表。 参数说明: - dbPath: STRING,DolphinDB数据库路径,如 "dfs://stock"。如果是内存表,请传空字符串 "" - tableName: STRING,数据表名称,如 "daily_kline" - startDate: DATE (TEMPORAL),计算起始日期 - endDate: DATE (TEMPORAL),计算结束日期 - factorName: STRING, 因子的英文别名,将作为结果列的列名。例如 "Alpha101_001" 或 "Classic_Amplitude" - factorFormula: STRING, 因子的计算公式,如"(high - low) / close" - securityidName: STRING,标的列名 - tradetimeName: STRING,时间列名 - outputTableName: STRING,必填。用于存储计算结果的共享内存表名称 返回: - STRING,执行状态消息。 // 示例:计算移动平均和波动率因子 sql_with_contextby( "daily_quotes", "trade_date, security_id, mavg(close, 20) as ma_20, mstd(close, 20) as std_20", "security_id", "factor_result_temp" ) ' // 3. 注册工具 (使用严格的位置参数) if (`sql_with_contextby in (exec name from listMCPTools())) { updateMCPTool( `sql_with_contextby, sql_with_contextby, `dbPath`tableName`startDate`endDate`factorName`factorFormula`securityidName`tradetimeName`outputTableName, ["STRING", "STRING", "TEMPORAL", "TEMPORAL", "STRING", "STRING", "STRING", "STRING", "STRING"], description_sql_with_contextby ) } else { addMCPTool( `sql_with_contextby, sql_with_contextby, `dbPath`tableName`startDate`endDate`factorName` `dbPath`tableName`startDate`endDate`factorName`factorFormula`securityidName`tradetimeName`outputTableName, `securityidName`tradetimeName`outputTableName, ["STRING", "STRING", "TEMPORAL", "TEMPORAL", "STRING", "STRING", "STRING", "STRING", "STRING"], description_sql_with_contextby ) } // 4. 发布 publishMCPTools(`sql_with_contextby) listMCPTools()