基于 DolphinDB 构建高性能因子评价框架
在投资领域,因子是解释收益与资产定价的核心,追踪有效因子是获取超额收益的关键。而因子评价则是系统化评估因子的统计显著性与信息有效性的关键流程。本文基于 DolphinDB 构建了一套高性能因子评价框架,支持对单因子与双因子进行分析评价。
1. 因子评价框架介绍
与 Python 相比,DolphinDB 在因子评价场景中展现出更高的数据读写效率,能够为量化分析提供更高效的计算基础。目前在 DolphinDB 中,已支持 Alphalens 工具模块的部分功能,但由于 Alphalens 项目(GitHub - quantopian/alphalens: Performance analysis of predictive (alpha) stock factors)早已停止更新与维护,且使用门槛较高。因此我们以 GitHub - dkl0707/factor_backtest: 因子回测框架 为例,致力于构建一套可读性更强、指标体系更完整的因子评价框架。
相较于 DolphinDB 已实现的 Alphalens 模块而言, factorBacktest 模块主要使用了基于宏变量的元编程(需要 DolphinDB 2.00.12 版本及以上),这使得整体模块的可读性大幅提高。 factorBacktest 模块的主要评价指标包括如下:
表1-1 factorBacktest 模块主要评价指标
| 类别 | 评价指标 |
|---|---|
| 回撤 | 最大回撤 |
| 超额收益最大回撤 | |
| 收益率 | 年化收益率 |
| 超额年化收益率 | |
| 收益率的显著性检验 | |
| 波动率 | 年化波动率 |
| 超额年化波动率 | |
| 夏普比率 | 夏普比率 |
| 信息比率 | 信息比率 |
| 相对胜率 | 策略相对基准胜率 |
| 信息系数 | 信息系数均值 |
| 信息系数标准差 | |
| 信息系数> 0 的比例 | |
| 信息系数> 0.03 的比例 | |
| Rank_IC 均值 | |
| Rank_ICIR |
两个模块存在以下功能差异:
表1-2 factorBacktest 模块与 Alphalens 模块比较
| 功能 | factorBacktest | DolphinDB Alphalens |
|---|---|---|
| 不同持仓周期的远期收益计算 | × | √ |
| 因子收益率计算 | × | √ |
| 因子换手率分析 | × | √ |
| 策略相对基准胜率 | √ | × |
| Newey-West 调整消除残差异方差与自相关性 | √ | × |
| Fama-Macbeth 回归排除残差在截面上的相关性对标准误的影响 | √ | × |
| 因子收益率的风险调整 | √ | × |
| 序贯排序双分组 | √ | × |
下载文末的 factorBacktest.dos 文件并将模块同步至 DolphinDB 的 getHomeDir()+/modules 的目录下后,可以在 DolphinDB 中调用 factorBacktest 模块。使用该模块通常包括三个步骤:
- Step 1:准备因子数据与行情数据;
- Step 2:使用
preprocess等函数进行数据预处理; - Step 3:调用对应函数获取分析结果;
在接下来的章节中,将从数据准备开始逐步介绍 factorBacktest 模块的具体实现。
2.数据准备
2.1 数据导入
本因子评价框架使用了 factor_backtest_data 文件夹中各 csv 文件。读者可下载文末的
factor_backtest_data 压缩包,并解压至
<YOUR_DOLPHINDB_PATH>/server/ 路径下,后续可以直接使用
loadText 函数提取相关数据以便后续计算和分析。
factorTB = loadText("<YOUR_DOLPHINDB_PATH>/server/factor_backtest_data/factorTB.csv")
mktmvTB = loadText("<YOUR_DOLPHINDB_PATH>/server/factor_backtest_data/mktmvTB.csv")
industryTB = loadText("<YOUR_DOLPHINDB_PATH>/server/factor_backtest_data/industryTB.csv")
bp_factorTB = loadText("<YOUR_DOLPHINDB_PATH>/server/factor_backtest_data/bp_factorTB.csv")
bpTB = loadText("<YOUR_DOLPHINDB_PATH>/server/factor_backtest_data/bpTB.csv")
retTB = loadText("<YOUR_DOLPHINDB_PATH>/server/factor_backtest_data/retTB.csv")
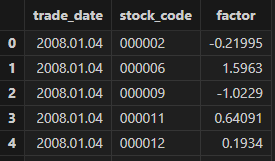
benchmarkTB = loadText("<YOUR_DOLPHINDB_PATH>/server/factor_backtest_data/benchmarkTB.csv")使用 select top 100 * from factorTB 预览查看 factorTB 表中的 factor
因子数据,其中 trade_date 为交易日期,stock_code 为股票代码, “factor” 为因子名称:
使用 select top 100 * from mktmvTB 预览查看 mktmvTB 表中的市值数据,其中 mktmv
为市值:

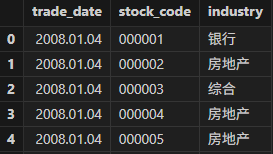
使用 select top 100 * from industryTB 预览查看 industryTB 表中的行业数据,其中
industry 为行业:
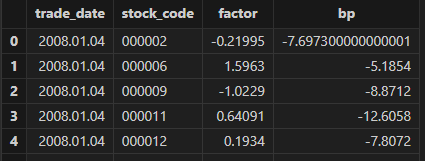
使用 select top 100 * from bp_factorTB 预览查看 bp_factorTB
表中的多因子数据,其中 factor 和 bp 均为因子名称:
使用 select top 100 * from bpTB 预览查看 bpTB 表中的 bp 因子数据:
使用 select top 100 * from retTB 预览查看 retTB 表中的股票收益率数据,其中 ret
为收益率:
使用 select top 100 * from benchmarkTB 预览查看 benchmarkTB
中的基准收益率数据:
值得注意的是,本模块并不限制输入表格的字段名,用户只需要确保输入表格的表结构与上述示例保持一致即可。为便于后续操作,建议用户在不同输入表中统一交易日期和证券代码的列名。除此之外,本模块也支持对日频、周频、月频等数据进行处理。
2.2 数据预处理
直接调用 preprocess 函数对 factor 、bp 因子数据进行去极值、标准化以及中性化处理。
具体代码示例和处理后结果预览如下:
use factorBacktest
// 数据预处理
factorNew = preprocess(factorTB,
"factor",
mktmvTB = mktmvTB,
industryTB = industryTB,
dateName = "trade_date",
securityName = "stock_code",
mvName = "mktmv",
indName = "industry",
delOutlierIf = true,
standardizeIf = true,
neutralizeIf = true,
delOutlierMethod = "mad",
standardizeMethod = "rank",
n = 3,
modify = false ,
startDate = 2008.01.04,
endDate = 2017.01.20)
// 观察factor因子预处理后结果
select top 100 * from factorNew
/*
trade_date stock_code factor
2008.01.04 000002 -0.06393232889798993
2008.01.04 000006 1.5546531851632837
2008.01.04 000009 -1.2096673940460276
2008.01.04 000011 0.7557481911404614
2008.01.04 000012 0.32144219178486666
*/在 preprocess 函数中,主要存在以下重要的函数参数:
- factorName 代表输入的因子数据表中因子值的列名,如在这段代码示例中,factorTB 表中因子值的列名为 “factor”。
- mvName 与 indName 分别表示市值表与行业表中表示市值数据与行业类别的列名。
- dateName 与 securityName 则表示交易日期与证券代码的列名。
3. 案例实战:单因子分析
在 factorBacktest 中,我们提供了系统而全面的单因子分析框架,能够从多个维度审视因子的表现,包括 IC 、ICIR 、Rank_IC 、信息比率、夏普比率、最大回撤等多个指标,能够多角度评估因子的表现,从而对其形成准确全面的认识和判断。
在本节中,我们将以前一章节所提取的 factor 因子为例,介绍如何使用 factorBacktest 模块进行单因子分析。
singleResult = singleFactorAnalysis(factorTB = factorNew , // 因子数据
retTB = retTB , // 收益率表
"factor" , // 因子名称
nGroups = 5, // 因子分组数量
rf =0.0, // 无风险收益率,默认为0
mktmvDF = mktmvTB , // 市值表
dateName ="trade_date", // 交易日期列名
securityName = "stock_code" , // 证券代码列名
retName ="ret", // 收益率列名
mvName = "mktmv" , // 市值列名
startDate = 2008.01.04 , // 开始日期
endDate = 2017.01.20 , // 终止日期
maxLags=NULL, // 滞后阶数,默认为NULL
benchmark = benchmarkTB , // 市场基准收益率表,默认为NULL
period = "DAILY" ) // 频率,可选参数包括"DAILY","WEEKLY","MONTHLY"在单因子分析方面,我们可以调用 singleFactorAnalysis 函数获取单因子分析的结果,结果 singleResult
为一个包括9个键的字典:
- “groupRet” 表示股票分组收益率表格结果;
- “retStat” 表示不同分组收益率的统计显著性字典结果;
- “ICTest” 表示对因子 IC 与 IR 等相关指标的计算;
- “backtest” 表示因子的分组回测结果;
- “timeIndex” 表示绘制图片时的 X 轴;
- “netValue” 表示因子的分组净值;
- “retTable” 表示因子的多空收益率;
- “title1” 和“title2” 则分别表示分组净值曲线与多空收益曲线的标题;
下面各节将对相关结果进行分析。
3.1 分组收益率
因子数据预处理完成后,我们按因子值对股票进行排序分组,并计算各组的收益率。其中,“H-L” 代表多空组合收益率,即表示做多最后一组并做空第一组的收益率。
观察分组收益率结果,并设置输出格式为六位小数,相关代码与结果如下:
// 观察分组收益率结果
groupRet = singleResult["groupRet"]
groupname = ["Group0" , "Group1" , "Group2" , "Group3" , "Group4" , "H-L"]
<select top 10 trade_date , round(_$$groupname , 6) as _$$groupname from groupRet>.eval()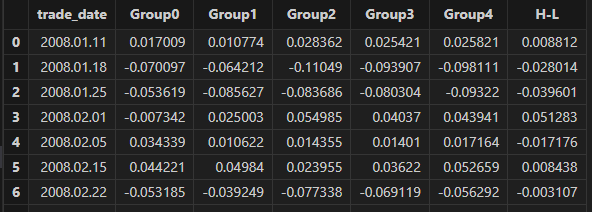
3.2 分组收益率的统计显著性
在计算完对应的分组收益率后,我们可以对不同组合收益率进行统计显著性检验。由于多因子回归模型中的残差常常存在异方差性和自相关性,若直接使用 OLS 方法估计 β 的标准误,可能会导致显著性检验结果不准确。本模块基于 Newey & West(1987)(A Simple, Positive Semi-Definite, Heteroskedasticity and AutocorrelationConsistent Covariance Matrix),实现了 Newey-West 调整函数。下述内容参考多因子回归检验中的 Newey-West 调整简单讲解了 newey-west 调整的数学原理与具体计算公式:
newey-west 调整的核心目标就是调整估计中间矩阵(middle matrix),并计算得出中间矩阵的相合估计,记为 S ,具体公式如下:

其中 T 代表时序的总期数,et 表示第 t 期的残差,Xi=[xi1,xi2,…,xiK]′ 是 X 的第 i 行的转置,L 是计算自相关性影响的最大滞后阶数。
将计算得到的 S 代入到 V_OLS 的表达式中,即可得到 Newey-west 自相关一致性协方差估计:

本节通过 neweyWestTest 函数对分组收益率进行均值估计,并输出经 Newey-West 调整后的 t 值与 p
值。调整过程的计算由 neweyWestCorrection 函数实现。
我们可以使用 singleResult["retStat"]["H-L"]
来获取对应多空组合的收益率均值与统计显著性。相关结果如下:
// output:
// ret_mean(%): 0.465416325805543
// p_value: 0.00000568582996640643
// t-value: 4.591311581999794输出结果包括收益率均值(ret_mean(%))、p 值(p_value)、t 值(t_value)。
分析上述结果可知,factor 因子的多空分组收益率的均值为 0.465%,且 p 值为 0.0000056,t 值为 4.59,表明多空收益率的均值显著不为 0。
3.3 IC 检验
IC 即信息系数(Information Coefficient),表示所选股票的因子值与股票下期收益率的截面相关系数。通过 IC 值可以判断因子值对下期收益率的预测能力。信息系数的绝对值越大,该因子越有效,预测能力越强。IC 为负表示因子值越小越好,IC 为正表示因子值越大越好。
IR 即信息比率(InformationRatio),是超额收益的均值与标准差之比,代表因子获取稳定 Alpha 的能力。
通过对因子 IC 与 IR 的相关检验,我们可以较为全面地评估该因子的预测力和有效性,判断其是否值得信赖和持续投资。
singleResult["icTest"]
/*
output:
Rank_ICIR: 0.10311019138174475
Rank_IC均值: 0.05030535697624222
IC均值: 0.03846492107792371
因子名称: 'factor'
IC标准差: 0.09652585561925417
IR: 0.39849344852894575
IC>0的比例(%): 64.57883369330453
IC>0.03的比例(%): 52.48380129589633
*/使用 singleResult["icTest"] 获取的结果为一个包含 8 个键的字典,包括 IC, IR,
Rank_ICIR, IC>0 的比例以及 IC >0.03 的比例等。
观察上述结果可知,IC 均值为 0.038,未达到"较强预测能力"的标准(≥0.05);IR 为 0.398,低于稳定性合格线(≥0.5);综合比较而言,factor 因子仅存在弱有效的预测能力,且因子的稳定性较差。
此外,我们也可以借助 getFactorIc 函数绘制因子 IC 、Rank_IC
的时序图与累计图,相关代码与绘制结果如下所示:
correlation = getFactorIc(factorNew, retTB, "factor" ,"trade_date" ,"stock_code", "ret" , 2008.01.02 , 2017.01.31)
correlation['IC_cumsum'] = correlation["IC"].cumsum()
correlation['Rank_IC_cumsum'] = correlation["Rank_IC"].cumsum()观察因子 IC 与 Rank_IC 结果,并设置输出格式为六位小数:
// 观察因子IC与Rank_IC结果
groupname = ["IC" , "Rank_IC" , "IC_cumsum" , "Rank_IC_cumsum"]
<select top 10 trade_date , round(_$$groupname , 6) as _$$groupname from correlation>.eval()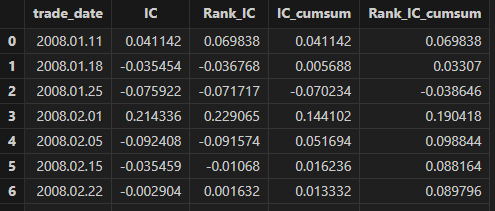
使用 plot 函数进行绘制:
plot(table(correlation["IC"] ,correlation['IC_cumsum']) , correlation["trade_date"] , title = "因子factor的IC时序图与累计图", extras={multiYAxes: true})
plot(table(correlation["Rank_IC"] ,correlation['Rank_IC_cumsum']) , correlation["trade_date"] , title = "因子factor的Rank_IC时序图与累计图", extras={multiYAxes: true})
在因子 IC 时序图与累计图中,我们常常关注图中所包含的不同信息,例如:图3.3中 IC 值在正负之间频繁波动,意味着该因子在不同市场环境下预测能力不稳定。而 IC 累计图是将每一期的 IC 值进行累加后的结果,它展示了因子长期的累积预测效果。图3.3中的累计 IC 值持续上升,表明因子在不断为投资组合创造正向的预期收益。
3.4 单分组下的因子分析与净值曲线
在本小节,我们将分析分组回测结果,并绘制因子分组净值曲线与因子多空收益曲线。使用
singleResult["backtest"] 获取对应的单分组下因子分析结果如下所示:
backtestTB = singleResult["backtest"]
// 观察分组回测结果
groupname = ["Group0","Group1","Group2","Group3","Group4","H_L","benchmark"]
<select index , round(_$$groupname , 6) as _$$groupname from backtestTB>.eval()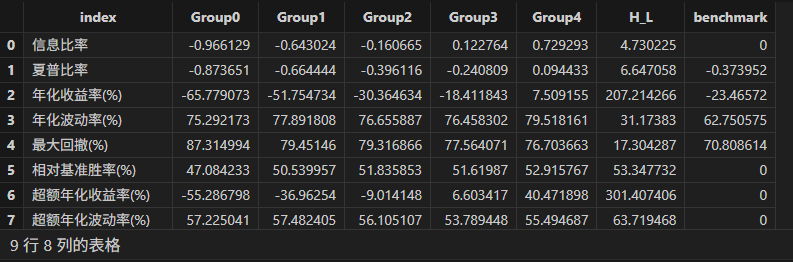
使用
plot(singleResult["netValue"],singleResult["timeIndex"],singleResult["title1"])
绘制因子分组净值曲线:

使用 plot(singleResult["retTable"] , singleResult["timeIndex"] ,
singleResult["title2"]) 绘制因子多空收益曲线:

观察上述结果可知,factor 因子在分组回测中展现出较强的收益区分能力,但波动率较高说明了较差的风险控制能力。多空策略相较而言表现优异,展现出更低的波动率与更高的收益率。
4. 案例实战:双因子分析
factorBacktest 模块同样支持对双因子进行分析。本节将以 factor 与 bp 两个因子为例,介绍如何使用 factorBacktest 模块进行双因子分析。
doubleResult = doubleFactorAnalysis(factorTB1 = bpNew , // 因子数据表1
factorTB2 = factorNew , // 因子数据表2
retTB = retTB , // 收益率表
"bp" , // 因子名称1
"factor" , // 因子名称2
nGroups1 = 5 , // 分组数量,默认为5
nGroups2 = 5 ,
mktmvTb = mktmvTB , // 市值表
dateName ="trade_date" , // 交易日期列名
securityName ="stock_code", // 证券代码列名
retName ="ret" , // 收益率列名
mvName ="mktmv" , // 市值列名
startDate = 2008.01.04, // 开始日期
endDate = 2017.01.20, // 截止日期
maxLags = NULL, // 滞后阶数,默认为 NULL
rf=0.0 , // 无风险利率,默认设置为 0
benchmark =NULL, // 市场基准收益率表,默认为NULL
period = "WEEKLY", // 数据频率,可选参数包括DAILY,WEEKLY,MONTHLY
regressionStep = false) // bool 值,表示是否进行 Fama-Macbeth 回归第一步计算我们使用 doubleFactorAnalysis 函数来获取双因子分析的结果,其中 factorNew 和 bpNew 为
factor 、bp 因子经过数据预处理后的结果。结果 doubleResult 为一个包括 4 个键的字典:
- “dbSortRet” 表示收益率经过 bp 因子与 factor 因子排序后的结果;
- “dbSortMean” 表示分组收益率均值与对应的 Newey-West 调整后的 t 值;
- “dbSortBacktest” 表示分组回测结果;
- “famaMacbethResult” 表示 Fama-Macbeth 回归后的结果。
4.1 序贯双重排序收益率
在因子评估中,双重排序可以评估两个因子叠加使用是否会优于单个因子,即分析两个因子的信息重叠程度以及否有信息增益。具体来说,对于两个因子 X、Y,同时按照 X、Y排序分组,即双重排序,构建投资组合,分析投资组合的表现。
使用 doubleResult["dbSortRet"] 获取结果示例如下图所示:
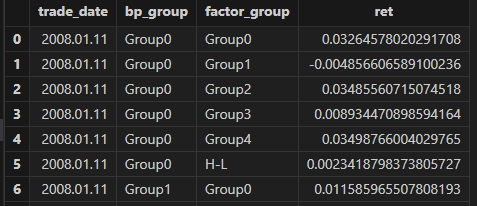
4.2 序贯排序双分组收益率均值
在计算 factor 与 bp 两个因子经序贯双重排序后的收益率后,我们同样可以对分组收益率进行收益率均值计算并输出经过 Newey-West 调整后的 t 值,具体代码示例与输出结果如下所示:
dbSortMean = doubleResult["dbSortMean"]
groupname = ["Group0" , "Group1" , "Group2" , "Group3" , "Group4" , "H_L" ]
<select index , round(_$$groupname , 6) as _$$groupname from dbSortMean>.eval()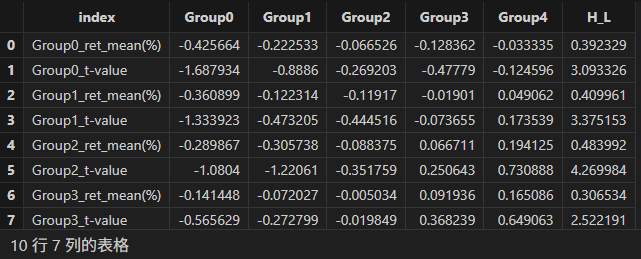
其中 index 列中 Group 表示 bp 分组,列名 Group 表示 factor 分组。
分析上述结果可知:
- 在所有 bp 分组下,H-L 多空收益率均为正,且 t 值(t-value)均处于较高水平,表明 factor 因子高分组收益率显著高于低分组,且在不同 bp 分组下均能有效区分资产收益。
- bp 因子分组从 Group0 到 Group4,收益率均值总体呈现上升趋势。表明 bp 因子分组越高,其对应的组合收益率在 factor 因子不同分组下有改善的迹象,bp 因子对收益率有一定正向影响。
- factor 因子在中高 bp 资产(如 Group3、Group4)中的单调性和显著性更强,表明 factor 因子有效性与资产规模存在一定相关。
4.3 序贯排序双分组回测指标
factorBacktest 模块同样支持对因子双分组结果进行回测指标的计算。具体可以调用
doubleResult["dbSortBacktest"] 对相关结果进行输出:
dbSortBacktest = doubleResult["dbSortBacktest"]
groupname = ["Group0" , "Group1" , "Group2" , "Group3" , "Group4" , "H_L" ]
<select index , round(_$$groupname , 6) as _$$groupname from dbSortBacktest>.eval()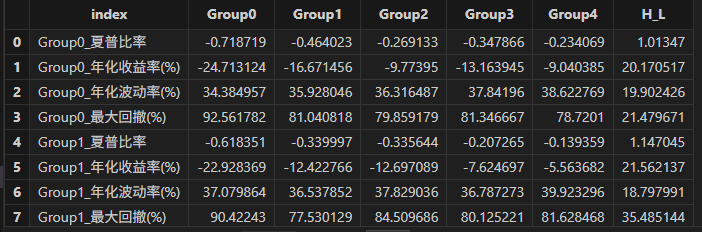
分析上述结果可知:
- bp 和 factor 因子与投资组合的表现呈正向关系:随着 bp 和 factor 分组从 Group0 递增至 Group4 ,投资组合的夏普比率逐渐升高,年化收益率逐渐增加,年化波动率和最大回撤逐渐降低。
4.4 Fama-Macbeth 回归
为了排除模型拟合残差在截面上的相关性对标准误的影响,本模块也基于 Fama & Macbeth(1973) (Risk, Return, and
Equilibrium: Empirical Tests),实现了 Fama-MacBeth 回归函数。相关功能主要基于
famaMacbethReg 函数实现,以下是参考 Fama-Macbeth中的两步回归的原理分别是什么? - 石川的回答 -
知乎对 Fama-Macbeth 回归的数学原理与计算公式的简单解释:
fama-macbeth 回归与传统截面回归类似,也采用两步回归估计:
在第一步中,对每一个资产截面,通过时间序列回归得到个股收益率在因子上的暴露 βi:

在第二步中,Fama-MacBeth 在每个时间 t 上对因子暴露 βi 进行了一次截面回归:

Fama-MacBeth 回归的第二步是在每个时间点 t 对所有资产进行一次独立的截面回归。举例来说,若有 T=500 个时间点的数据,则会进行 500 次截面回归,每次仅使用该时间点的资产横截面数据。最终,将这 500 次回归得到的系数取平均,作为回归的估计结果:


由于第二步回归的系数可能存在异方差、自相关等性质, 所以同样需要用 newey-west 方法进行调整。
使用 doubleResult["famaMacbethResult"] 获取 Fama-Macbeth 回归结果:
doubleResult["famaMacbethResult"]
/*
output:
Average_Obs: 1,591.1749460043197
R-Square: 0.017901474327154446
factor:
t统计量: 6.986433993363168
beta: 0.0019545565844644496
p值: 0.00000000000988853444
标准误: 0.0002797645531785171
bp:
t统计量: 3.6404282777536614
beta: 0.001105722959290441
p值: 0.00030294518028139983
标准误: 0.0003037343067702823
*/值得注意的是,famaMacbethReg 中的 regressionStep 参数为布尔向量, 表示是否使用两步回归方法,默认为 “false”,即将因子值视为因子暴露或直接传入因子暴露,只进行第二步回归。
最后输出的结果为一个字典,包括模型的平均 R2 ,平均观测数量,以及不同因子的 t 统计量、beta(风险溢价)、p 值、标准误。
分析上述结果可知:
- 拟合优度 R2 处于较低水平,表示模型解释力较弱,约 98% 的资产回报变异未能被 factor 和 bp 两个因子解释;
- factor 因子对资产回报有显著正影响,且风险溢价估计为 0.00195;
- bp 因子对资产回报有显著正影响,且风险溢价估计为 0.00110;
5.性能测试
在本章节中,我们将比较 DolphinDB 脚本语言与 Python 在相同因子回测框架中的性能差异,其中在相同运行任务中,所使用的数据源与运行结果均保持一致:
表5-1 DolphinDB 与 Python 运行时间对比
| 运行任务 | DolphinDB | Python |
|---|---|---|
| 数据预处理 | 1.141s | 3.867s |
| 单因子分析 | 1.117s | 8.306s |
| 双因子分析 | 1.673s | 11.970s |
表5-2 运行所使用数据规模
| 变量名称 | 含义 | 规模(行 * 列) |
|---|---|---|
| factorTB | 原始输入的 factor 因子表 | 796203 * 3 |
| factorNew | 预处理后的 factor 因子表 | 739908 * 3 |
| bpTB | 原始输入的 bp 因子表 | 964744 * 3 |
| bpNew | 预处理后的 bp 因子表 | 957733 * 3 |
| benchmarkTB | 市场基准收益率表 | 463 * 2 |
| bp_factorTB | bp , factor 双因子表 | 745059 * 4 |
| industryTB | 行业表 | 1069702 * 3 |
| mktmvTB | 市值表 | 974754 * 3 |
| retTB | 收益率表 | 793802 * 3 |
观察上述结果可知,在所有任务情境下,DolphinDB 相较于 Python 均表现出了更快的运行速度。
6.DolphinDB factorBacktest 函数列表
6.1 辅助类函数
表6-1 辅助类函数
| 函数 | 语法 | 解释 |
|---|---|---|
dropNullRow |
dropNullRow(table) | 去除表格中存在空值的行 |
getPreviousFactor |
getPreviousFactor(factor, dateName = `trade_date, startDate = 2020.01.01, endDate = 2021.01.01) | 获取上一期因子值 |
6.2 数据预处理类函数
表6-2 数据预处理类函数
| 函数 | 语法 | 解释 |
|---|---|---|
delOutlier |
delOutlier(mutable factorTB, factorName, dateName , securityName, method, n, modify, startDate , endDate) | 去极值 |
standardize |
standardize(mutable factorTB, factorName , dateName, securityName, method, modify, startDate , endDate) | 标准化 |
neutralize |
neutralize(mutable factorTB,factorName, mktmvTB, industryTB, dateName, securityName, mvName, indName ,modify, startDate, endDate) | 中性化 |
preprocess |
preprocess(mutable factor, factorName, mktmvTB = NULL, industryTB = NULL, dateName = "trade_date", securityName = "stock_code", mvName = "mktmv", indName = "industry", delOutlierIf = true, standardizeIf = true, neutralizeIf = true, delOutlierMethod = "mad", standardizeMethod = "zscore", n = 3, modify = false, startDate = 2020.01.01, endDate = 2021.01.01) | 预处理 |
6.3 主要评价指标函数
表6-3 主要评价指标函数
| 函数 | 语法 | 解释 |
|---|---|---|
maxDrawdownNew |
maxDrawdownNew(returns) | 计算最大回撤,回撤= 1 - 净值现值 \ 历史最大净值 , 单位为% |
annualizedReturn |
annualizedReturn(returns, period="DAILY") | 计算年化收益率 |
annualizedVolatility |
annualizedVolatility(returns, period="DAILY") | 计算年化波动率 |
annualizedSharpe |
annualizedSharpe(returns, rf=0, period="DAILY") | 计算年化夏普比率,年化夏普比率 = (年化收益率-无风险收益率) \ 年化波动率 |
erAnnualReturn |
erAnnualReturn(returns, benchmarkReturns, period="DAILY") | 计算年化超额收益率,年化超额收益率 = (1+年化策略收益率)\(1+年化基准收益率)-1 |
informationRatio |
informationRatio(returns, benchmarkReturns, period="DAILY") | 计算信息比率,信息比率 = 超额年化收益率\超额收益标准差 |
winRate |
winRate(returns, benchmarkReturns) | 计算相对基准胜率 |
6.4 因子分析类函数
表6-4 因子分析类函数
| 函数 | 语法 | 解释 |
|---|---|---|
getFactorIc |
getFactorIc(factor, ret, factorName , dateName = "trade_date", securityName = "stock_code", retName = "ret_value", startDate = 2020.01.01, endDate = 2021.01.01) | 计算因子IC序列 |
neweyWestCorrection |
neweyWestCorrection(x, y , maxLags) | Newey-West修正函数 |
neweyWestTest |
neweyWestTest(arr, factorName = "factor", maxLags = NULL) | 计算收益率均值并输出Newey-West调整后的t统计量与p值 |
analysisFactorIc |
analysisFactorIc(factor, ret, factorName , dateName = "trade_date" , securityName = "stock_code", retName = "ret_value", startDate = 2020.01.01, endDate = 2021.01.01) | 分析单因子IC |
riskAdjAlpha |
riskAdjAlpha(factorRet, riskFactorRet, factorName, maxLags=NULL, dateName = "trade_date") | 计算因子收益率经风险调整后的Alpha与t值 |
famaMacbethReg |
famaMacbethReg(ret, factor, rf, factorNameLst, regressionStep = false, dateName = "trade_date" , securityName = "stock_code", retName = "ret_value", startDate = 2020.01.01, endDate = 2021.01.01) | Fama-Macbeth回归 |
6.5 分组计算类函数
表6-5 分组计算类函数
| 函数 | 语法 | 解释 |
|---|---|---|
getStockGroup |
getStockGroup(factorDF, factorName, nGroups = 5, dateName = "trade_date", securityName = "stock_code") | 根据因子值大小进行排序分组 |
getGroupRet |
getGroupRet(factorDF, retDF, factorName, nGroups, mktmvDF=NULL, dateName = "trade_date", securityName = "stock_code", retName = "ret_value", mvName = "mktmv", startDate = 2020.01.01, endDate = 2021.01.01) | 计算分组收益率 |
getGroupRetBacktest |
getGroupRetBacktest(groupRet, rf=0.0, benchmark=NULL, period="DAILY", dateName = "trade_date", retName = "ret_value") | 计算各组收益率的回测指标 |
analysisGroupRet |
analysisGroupRet(factorTB , retTB , factorName , nGroups, mktmvDF = NULL, rf = 0.0 , benchmark = NULL, period = "DAILY", dateName = "trade_date", securityName = "stock_code", retName = "ret_value", mvName = "mktmv", startDate = 2020.01.01, endDate = 2021.01.01) | 单分组下的因子分析 |
getDoubleSortGroup |
getDoubleSortGroup(factor1TB, factor2TB, factor1Name, factor2Name, nGroups1, nGroups2 , dateName = "trade_date", securityName = "stock_code") | 计算序贯排序双分组 |
getDoubleSortGroupRet |
getDoubleSortGroupRet(factor1TB, factor2TB, retTB, factor1Name, factor2Name, nGroups1, nGroups2, mktmvTb=NULL, dateName = "trade_date", securityName = "stock_code", retName = "ret_value" , mvName = "mktmv", startDate = 2020.01.01, endDate = 2021.01.01) | 计算序贯排序双分组收益率 |
doubleSortMean |
doubleSortMean(groupRet, factor1Name, factor2Name, dateName = "trade_date", securityName = "stock_code", retName = "ret_value", maxLags = NULL) | 计算序贯排序双分组收益率均值 |
doubleSortBacktest |
doubleSortBacktest(groupRet, factor1Name, factor2Name, rf=0, benchmark=NULL, period="DAILY",dateName = "trade_date", retName = "ret_value") | 计算序贯排序双分组的回测指标 |
7. 总结和展望
本模块基于 DolphinDB 构建了一套更加通俗易懂的因子评价框架,涵盖了从因子数据处理、收益率分析、回测结果分析等多个核心功能,确保了分析结果的全面性,是量化因子研究流程中强有力的支撑工具。
当然,目前 factorBacktest 模块仍存在一定不足,例如未引入不同持仓周期的收益率计算等等。未来我们也将持续改进,不断扩充完善现有的因子评价框架。