窗口计算
在时序处理中经常需要使用窗口计算。DolphinDB 提供了强大的窗口计算函数,既可以处理数据表(使用 SQL 语句),又可处理矩阵,在流式计算中亦可使用。第2-4章分别对这三种情况进行详细解释。
DolphinDB 的窗口函数在使用上十分灵活,可嵌套多个内置或自定义函数。在此基础上,DolphinDB 还对窗口计算进行了精心优化,与其他系统相比拥有显著的性能优势。
本篇将系统的介绍 DolphinDB 的窗口计算,从概念划分、应用场景、指标计算等角度,帮助用户快速掌握和运用 DolphinDB 强大的窗口计算功能。
DolphinDB 1.30.15,2.00.3及以上版本支持本篇所有代码。此外,1.30.7,2.00.0以上版本支持绝大部分代码,细节部分会在小节内部详细说明。
1. 窗口的概念及分类
DolphinDB 内有五种窗口,分别是:滚动窗口、滑动窗口、累计窗口和会话窗口和 segment window。
在 DolphinDB 中,窗口的度量标准有两种:数据记录数和时间。
1.1. 滚动窗口
滚动窗口长度固定,且相邻两个窗口没有重复的元素。
滚动窗口根据度量标准的不同可以分为2种:
- 以记录数划分窗口
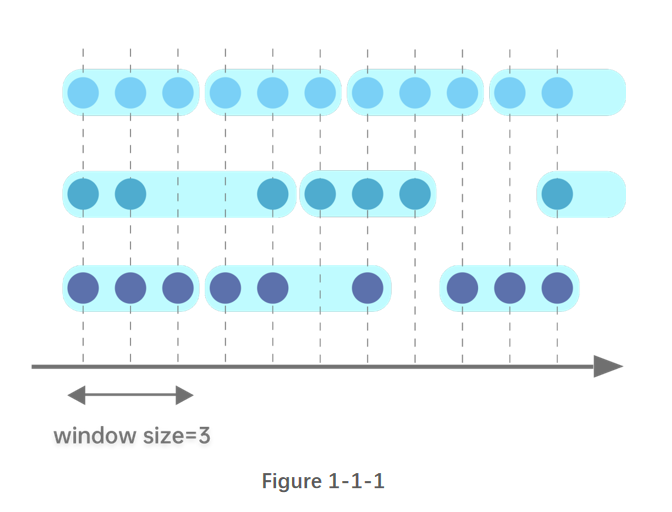
图1-1-1 指定窗口长度为3行记录,横坐标以时间为单位。从图上可以看出,按每三行记录划分为了一个窗口,窗口之间的元素没有重叠。
- 以时间划分窗口
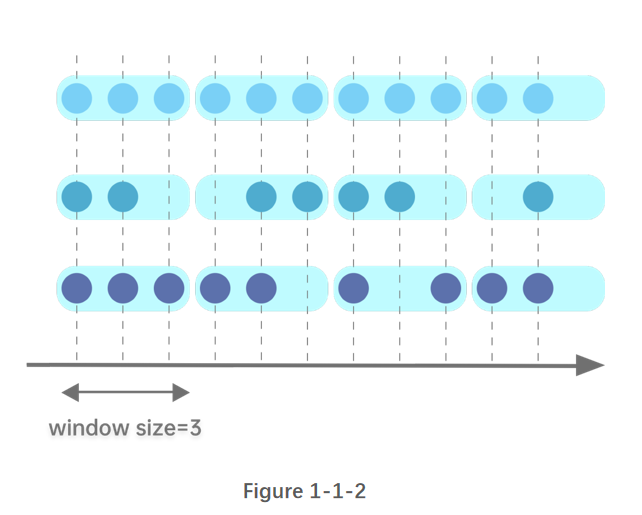
下图指定窗口大小为3个时间单位,横坐标以时间为单位。从图上可以看出,按每三个时间单位划分一个窗口,窗口之间的元素没有重叠 ,且窗口内的记录数是不固定的。
1.2. 滑动窗口
滑动窗口,即指定长度的窗口根据步长进行滑动。与滚动窗口不同,滑动窗口相邻两个窗口可能包括重复的元素。滑动窗口的窗口长度与步长既可为记录数,亦可为时间长度。
滑动窗口根据度量标准的不同可以分为2种:
- 以记录数划分窗口
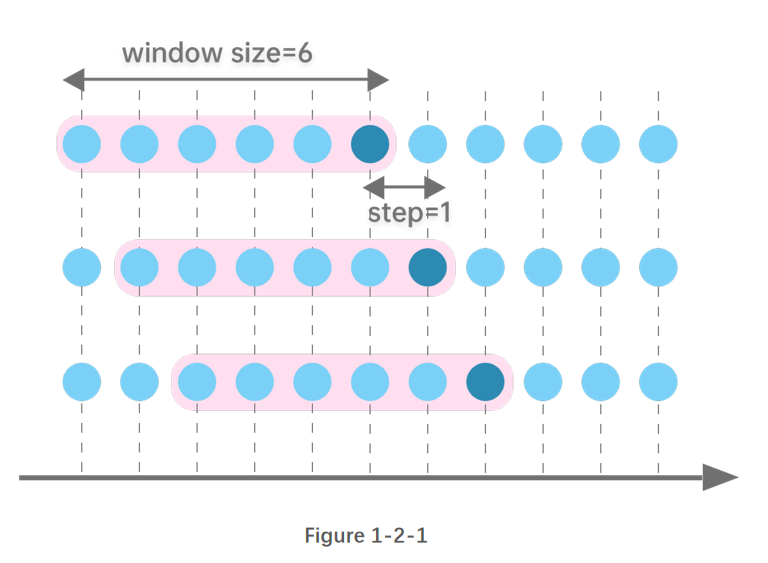
图1-2-1 指定窗口大小为6行记录,窗口每次向后滑动1行记录。
以时间划分窗口
- 步长为1行
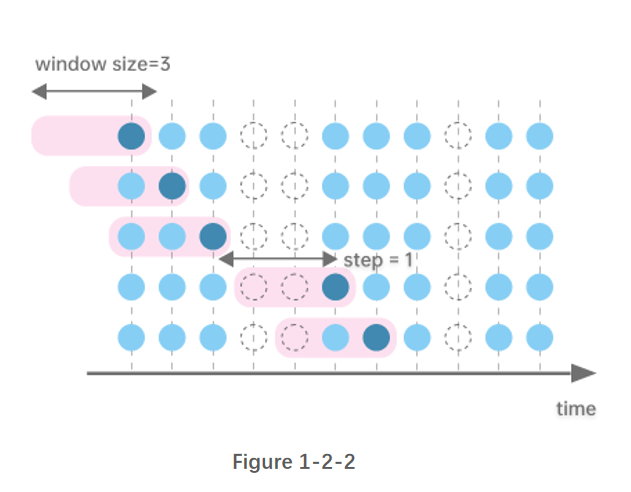
图1-2-2 指定窗口大小为3个时间单位,窗口以右边界为基准进行前向计算,窗口每次向后滑动1行记录。
- 步长为指定时间长度
图1-2-3 指定窗口大小为4个时间单位,每次向后滑动2个时间单位。
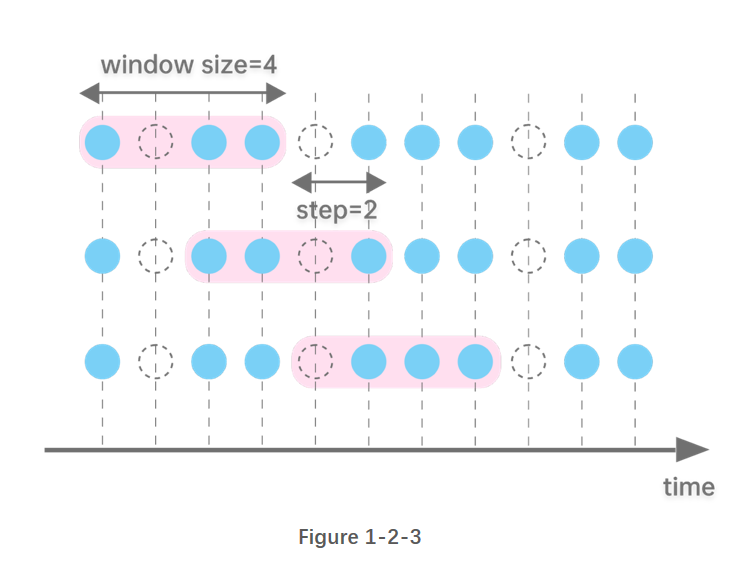
1.3. 累计窗口
累计窗口,即窗口的起始边界固定,结束边界不断右移,因此窗口长度不断增加。 累计窗口根据度量标准的不同可以分为2种:
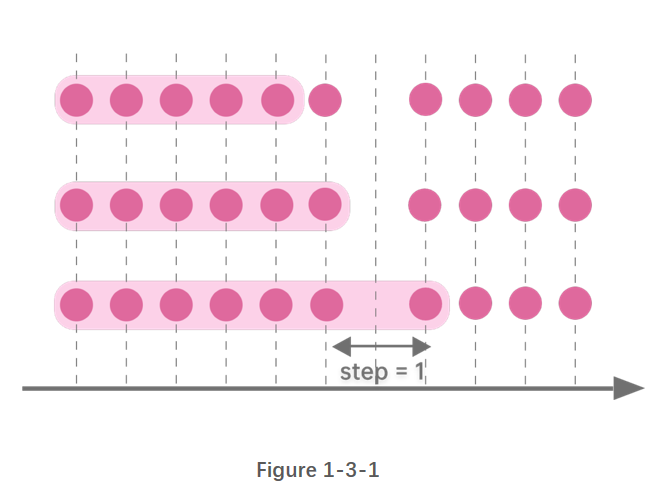
- 步长为1行
图1-3-1 窗口右边界每次右移1行,窗口大小累计增加。
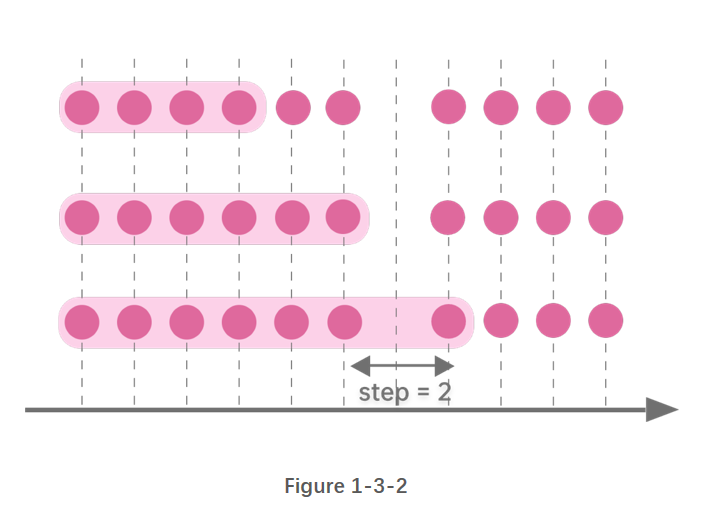
- 步长为指定时间长度
图1-3-2 窗口右边界每次右移2个时间单位,窗口大小累计增加。
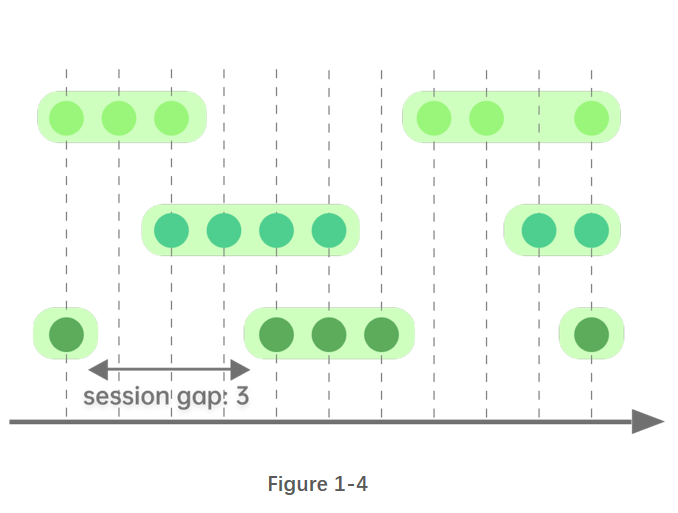
1.4. 会话窗口
会话窗口之间的切分,是依据某段时长的空白:若某条数据之后指定时间长度内无数据进入,则该条数据为一个窗口的终点,之后第一条新数据为下一个窗口的起点。会话窗口的窗口长度可变。
1.4.1. segment 窗口
segment 窗口根据连续的相同元素切分窗口。其窗口长度可变。
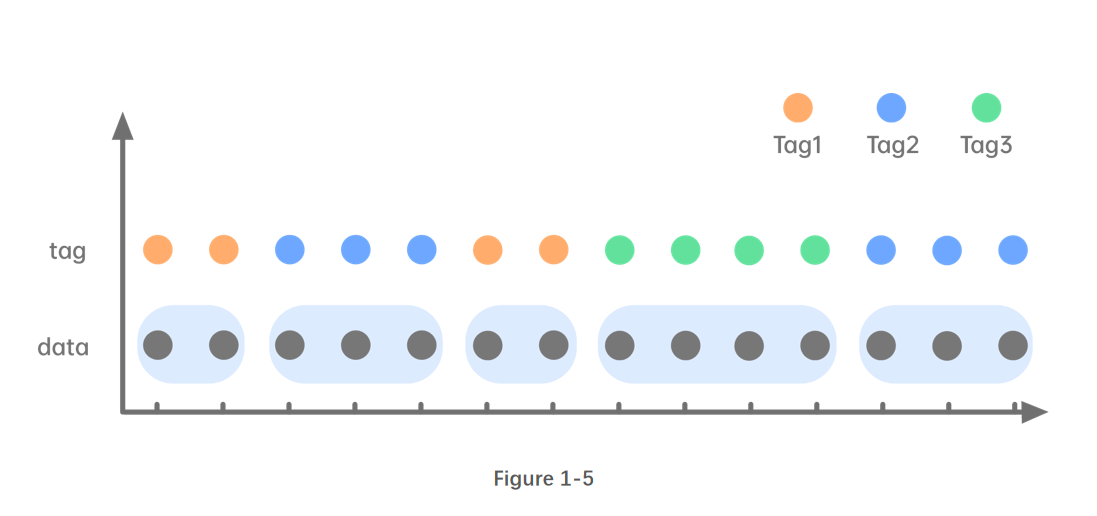
2. 对数据表使用窗口计算(使用 SQL 语句)
本章将介绍 DolphinDB 在 SQL 中的窗口计算:滚动窗口、滑动窗口、累计窗口,segment 窗口,以及窗口连接。
2.1. 滚动窗口
2.1.1. 时间维度的滚动窗口
在SQL中,可使用 interval, bar, dailyAlignedBar 等函数配合 group by 语句实现滚动窗口的聚合计算。
下面的例子根据10:00:00到10:05:59每秒更新的数据,使用 bar 函数每2分钟统计一次交易量之和:
t=table(2021.11.01T10:00:00..2021.11.01T10:05:59 as time, 1..360 as volume)
select sum(volume) from t group by bar(time, 2m)
# output
bar_time sum_volume
------------------- ----------
2021.11.01T10:00:00 7260
2021.11.01T10:02:00 21660
2021.11.01T10:04:00 36060
bar 函数的分组规则是将每条记录最近的能整除 interval 参数的时间作为开始时间。对于给定窗口起始时刻(且该时刻不能被 interval 整除)的场景,bar 函数不适用。
在金融场景中,在交易时段之外也存在一些数据输入,但是在做数据分析的时候并不会用到这些数据;在期货市场,通常涉及到两个交易时间段,有些时段会隔天。dailyAlignedBar 函数可以设置每天的起始时间和结束时间,很好地解决了这类场景的聚合计算问题。
以期货市场为例,数据模拟为国内期货市场的两个交易时段,分别为下午1:30-3:00和晚上9:00-凌晨2:30。使用 dailyAlignedBar 函数计算每个交易时段中的7分钟均价。
sessions = 13:30:00 21:00:00
ts = 2021.11.01T13:30:00..2021.11.01T15:00:00 join 2021.11.01T21:00:00..2021.11.02T02:30:00
ts = ts join (ts+60*60*24)
t = table(ts, rand(10.0, size(ts)) as price)
select avg(price) as price, count(*) as count from t group by dailyAlignedBar(ts, sessions, 7m) as k7
# output
k7 price count
------------------- ----------------- -----
2021.11.01T13:30:00 4.815287529108381 420
2021.11.01T13:37:00 5.265409774828835 420
2021.11.01T13:44:00 4.984934388122167 420
...
2021.11.01T14:47:00 5.031795592230213 420
2021.11.01T14:54:00 5.201864532018313 361
2021.11.01T21:00:00 4.945093814017518 420
//如果使用bar函数会不达预期
select avg(price) as price, count(*) as count from t group by bar(ts, 7m) as k7
# output
k7 price count
------------------- ----------------- -----
2021.11.01T13:26:00 5.220721067537347 180 //时间从13:26:00开始,不符合预期
2021.11.01T13:33:00 4.836406542137931 420
2021.11.01T13:40:00 5.100716347573325 420
2021.11.01T13:47:00 5.041169475132067 420
2021.11.01T13:54:00 4.853431270784876 420
2021.11.01T14:01:00 4.826169502311608 420 期货市场中有一些不活跃的期货,一段时间内可能都没有报价,但是在数据分析的时候需要每2秒输出该期货的数据,这个场景下就需要用到 interval 函数进行插值处理。
在以下示例中,缺失值使用前一个值进行填充。如果同一窗口内有重复值,则用最后一个作为输出值。
t=table(2021.01.01T01:00:00+(1..5 join 9..11) as time, take(`CLF1,8) as contract, 50..57 as price)
select last(contract) as contract, last(price) as price from t group by interval(time, 2s,"prev")
# output
interval_time contract price
------------------- -------- -----
2021.01.01T01:00:00 CLF1 50
2021.01.01T01:00:02 CLF1 52
2021.01.01T01:00:04 CLF1 54
2021.01.01T01:00:06 CLF1 54
2021.01.01T01:00:08 CLF1 55
2021.01.01T01:00:10 CLF1 57
//如果使用bar函数会不达预期
select last(contract) as contract, last(price) as price from t group by bar(time, 2s)
bar_time contract price
------------------- -------- -----
2021.01.01T01:00:00 CLF1 50
2021.01.01T01:00:02 CLF1 52
2021.01.01T01:00:04 CLF1 54
2021.01.01T01:00:08 CLF1 55
2021.01.01T01:00:10 CLF1 57 2.1.2. 记录数维度的滚动窗口
除了时间维度可以做滚动窗口计算之外,记录数维度也可以做滚动窗口计算。在股票市场临近收盘的时候,往往一分钟之内的交易量、笔数是非常大的,做策略时如果单从时间维度去触发可能会导致偏差。因此分析师有时会想要从每100笔交易而非每一分钟的角度去做策略,这个时候就可以用 rolling 函数实现。
下面是某天股票市场最后一分钟内对每100笔交易做成交量之和的例子:
t=table(2021.01.05T02:59:00.000+(1..2000)*30 as time, take(`CL,2000) as sym, 10* rand(50, 2000) as vol)
select rolling(last,time,100,100) as last_time,rolling(last,t.sym,100,100) as sym, rolling(sum,vol,100,100) as vol_100_sum from t
# output (每次结果会因为rand函数结果而不同)
last_time sym vol_100_sum
----------------------- --- -----------
2021.01.05T02:59:03.000 CL 24,900
2021.01.05T02:59:06.000 CL 24,390
2021.01.05T02:59:09.000 CL 24,340
2021.01.05T02:59:12.000 CL 24,110
2021.01.05T02:59:15.000 CL 23,550
2021.01.05T02:59:18.000 CL 25,530
2021.01.05T02:59:21.000 CL 26,700
2021.01.05T02:59:24.000 CL 26,790
2021.01.05T02:59:27.000 CL 27,090
2021.01.05T02:59:30.000 CL 25,610
2021.01.05T02:59:33.000 CL 23,710
2021.01.05T02:59:36.000 CL 23,920
2021.01.05T02:59:39.000 CL 23,000
2021.01.05T02:59:42.000 CL 24,490
2021.01.05T02:59:45.000 CL 23,810
2021.01.05T02:59:48.000 CL 22,230
2021.01.05T02:59:51.000 CL 25,380
2021.01.05T02:59:54.000 CL 25,830
2021.01.05T02:59:57.000 CL 24,020
2021.01.05T03:00:00.000 CL 25,1502.2. 滑动窗口
使用滑动窗口处理表数据有以下四种情况:
2.2.1. 步长为1行,窗口长度为 n 行
此类情况可使用 m 系列函数,moving 函数,或者 rolling 函数。
从1.30.16/2.00.4版本开始,亦可使用 window 函数。window 函数与 moving 函数类似,均为高阶函数,不同的是,window 函数更为灵活,不同于 moving 函数的窗口右边界是固定的, window 函数的左右边界均可自由设定。
下面以msum为例,滑动计算窗口长度为5行的vol值之和。
t=table(2021.11.01T10:00:00 + 0 1 2 5 6 9 10 17 18 30 as time, 1..10 as vol)
select time, vol, msum(vol,5,1) from t
# output
time vol msum_vol
------------------- --- --------
2021.11.01T10:00:00 1 1
2021.11.01T10:00:01 2 3
2021.11.01T10:00:02 3 6
2021.11.01T10:00:05 4 10
2021.11.01T10:00:06 5 15
...DolphinDB SQL可以通过 context by 对各个不同的 symbol 在组内进行窗口计算。context by 是DolphinDB 独有的功能,是对标准 SQL 语句的拓展,具体其他用法参照:context by
t=table(2021.11.01T10:00:00 + 0 1 2 5 6 9 10 17 18 30 join 0 1 2 5 6 9 10 17 18 30 as time, 1..20 as vol, take(`A,10) join take(`B,10) as sym)
select time, sym, vol, msum(vol,5,1) from t context by sym
# output
time sym vol msum_vol
------------------- --- --- --------
2021.11.01T10:00:00 A 1 1
2021.11.01T10:00:01 A 2 3
2021.11.01T10:00:02 A 3 6
...
2021.11.01T10:00:30 A 10 40
2021.11.01T10:00:00 B 11 11
2021.11.01T10:00:01 B 12 23
...
2021.11.01T10:00:30 B 20 90 m 系列函数是经过优化的窗口函数,如果想要使用自定义函数做窗口计算,DolphinDB 支持在 moving 函数、window 函数和 rolling 函数中使用自定义聚合函数。下面以 moving 嵌套自定义聚合函数为例:
以下的行情数据有四列(代码,日期,close 和 volume),按照代码分组,组内按日期排序。设定窗口大小为20,在窗口期内按照 volume 排序,取 volume 最大的五条数据的平均 close 的计算。
//t是模拟的四列数据
t = table(take(`IBM, 100) as code, 2020.01.01 + 1..100 as date, rand(100,100) + 20 as volume, rand(10,100) + 100.0 as close)
//1.30.15及以上版本可以用一行代码实现
//moving 支持用户使用自定义匿名聚合函数
select code, date, moving(defg(vol, close){return close[isort(vol, false).subarray(0:min(5,close.size()))].avg()}, (volume, close), 20) from t context by code
//其他版本可以用自定义命名聚合函数实现:
defg top_5_close(vol,close){
return close[isort(vol, false).subarray(0:min(5,close.size()))].avg()
}
select code, date, moving(top_5_close,(volume, close), 20) from t context by code 在做数据分析的时候,还会经常用到窗口嵌套窗口的操作。 举一个更复杂的例子:在做 101 Formulaic Alphas 中98号因子计算的时候,DolphinDB可以运用窗口嵌套窗口的方法,将原本在C#中需要几百行的代码,简化成几行代码,且计算性能也有接近三个数量级的提升。 trade 表有需要可以自行模拟数据,或用 sample 数据 CNTRADE。
// 输入表trade的schema如下,如需要可自行模拟数据。
name typeString typeInt
---------- ---------- -------
ts_code SYMBOL 17
trade_date DATE 6
open DOUBLE 16
vol DOUBLE 16
amount DOUBLE 16
// alpha 98 计算:
def normRank(x){
return rank(x)\x.size()
}
def alpha98SQL(t){
update t set adv5 = mavg(vol, 5), adv15 = mavg(vol, 15) context by ts_code
update t set rank_open = normRank(open), rank_adv15 = normRank(adv15) context by trade_date
update t set decay7 = mavg(mcorr(vwap, msum(adv5, 26), 5), 1..7), decay8 = mavg(mrank(9 - mimin(mcorr(rank_open, rank_adv15, 21), 9), true, 7), 1..8) context by ts_code
return select ts_code, trade_date, normRank(decay7)-normRank(decay8) as a98 from t context by trade_date
}
input = select trade_date,ts_code,amount*1000/(vol*100 + 1) as vwap,vol,open from trade
timer alpha98DDBSql = alpha98SQL(input)2.2.2. 步长为1行,窗口为指定时间长度
此类情况可使用 tm 系列或者 tmoving 系列函数。
从1.30.16/2.00.4版本开始,亦可使用 twindow 函数。twindow 函数与 tmoving 函数类似,均为高阶函数,不同的是,twindow 函数更为灵活,不同于 tmoving 函数的窗口右边界是固定的, twindow 函数的左右边界均可自由设定。
下面以tmsum为例,计算滑动窗口长度为5秒的 vol 值之和。
//1.30.14,2.00.2以上版本支持 tmsum 函数。
t=table(2021.11.01T10:00:00 + 0 1 2 5 6 9 10 17 18 30 as time, 1..10 as vol)
select time, vol, tmsum(time,vol,5s) from t
# output
time vol tmsum_time
------------------- --- ----------
2021.11.01T10:00:00 1 1
2021.11.01T10:00:01 2 3
2021.11.01T10:00:02 3 6
2021.11.01T10:00:05 4 9
2021.11.01T10:00:06 5 12
2021.11.01T10:00:09 6 15
2021.11.01T10:00:10 7 18
2021.11.01T10:00:17 8 8
2021.11.01T10:00:18 9 17
2021.11.01T10:00:30 10 10 实际场景中,计算历史分位的时候也会广泛运用到这类情况的窗口计算,具体在步长为1行窗口为n行这一小节介绍。
2.2.3. 步长为 n 行,窗口为 m 行
此类情况可使用高阶函数 rolling。
下面的例子计算步长为3行,窗口长度为6行的 vol 值之和。与 interval 函数不同的是,rolling 不会对缺失值进行插值,如果窗口内的元素个数不足窗口大小,该窗口不会被输出。 该例子中,数据一共是10条,在前两个窗口计算完之后,第三个窗口因为只有4条数据,所以不输出第三个窗口的结果。
t=table(2021.11.01T10:00:00+0 3 5 6 7 8 15 18 20 29 as time, 1..10 as vol)
select rolling(last,time,6,3) as last_time, rolling(sum,vol,6,3) as sum_vol from t
# output
last_time sum_vol
------------------- -------
2021.11.01T10:00:08 21
2021.11.01T10:00:20 392.2.4. 步长为指定时间长度,窗口为 n 个步长时间
此类情况可使用 interval 函数配合 group by 语句。下面的例子以5秒为窗口步长,10秒为窗口长度,计算 vol 值之和。
推荐使用1.30.14, 2.00.2及以上版本使用 interval 函数。
t=table(2021.11.01T10:00:00+0 3 5 6 7 8 15 18 20 29 as time, 1..10 as vol)
select sum(vol) from t group by interval(time, 10s, "null", 5s)
# output
interval_time sum_vol
------------------- -------
2021.11.01T10:00:00 21
2021.11.01T10:00:05 18
2021.11.01T10:00:10 15
2021.11.01T10:00:15 24
2021.11.01T10:00:20 19
2021.11.01T10:00:25 10 2.1.1.1中 interval 的场景可以看作是窗口长度与步长相等的特殊的滑动窗口,而本节则是窗口长度为 n 倍步长时间的滑动窗口。
2.3. 累计窗口
累计窗口有两种情况:一种是步长是1行,另一种是步长为指定时间长度。
2.3.1. 步长为1行
步长为1行的累计窗口计算在 SQL 中通常直接用 cum 系列函数。下面是累计求和 cumsum 的例子:
t=table(2021.11.01T10:00:00..2021.11.01T10:00:04 join 2021.11.01T10:00:06..2021.11.01T10:00:10 as time,1..10 as vol)
select *, cumsum(vol) from t
# output
time vol cum_vol
------------------- --- -------
2021.11.01T10:00:00 1 1
2021.11.01T10:00:01 2 3
2021.11.01T10:00:02 3 6
2021.11.01T10:00:03 4 10
2021.11.01T10:00:04 5 15
2021.11.01T10:00:06 6 21
2021.11.01T10:00:07 7 28
2021.11.01T10:00:08 8 36
2021.11.01T10:00:09 9 45
2021.11.01T10:00:10 10 55 在实际场景中经常会用 cum 系列函数与 context by 连用,做分组内累计计算。比如行情数据中,根据各个不同股票的代码,做各自的累计成交量。
t=table(2021.11.01T10:00:00 + 0 1 2 5 6 9 10 17 18 30 join 0 1 2 5 6 9 10 17 18 30 as time, 1..20 as vol, take(`A,10) join take(`B,10) as sym)
select*, cumsum(vol) as cumsum_vol from t context by sym
# output
time vol sym cumsum_vol
------------------- --- --- ----------
2021.11.01T10:00:00 1 A 1
2021.11.01T10:00:01 2 A 3
...
2021.11.01T10:00:18 9 A 45
2021.11.01T10:00:30 10 A 55
2021.11.01T10:00:00 11 B 11
2021.11.01T10:00:01 12 B 23
...
2021.11.01T10:00:18 19 B 135
2021.11.01T10:00:30 20 B 155 2.3.2. 步长为指定时间长度
要在SQL中实现步长为指定时间长度的累计窗口计算,可以使用 bar 函数搭配 cgroup by 来实现。
t=table(2021.11.01T10:00:00..2021.11.01T10:00:04 join 2021.11.01T10:00:06..2021.11.01T10:00:10 as time,1..10 as vol)
select sum(vol) from t cgroup by bar(time, 5s) as time order by time
# output
time sum_vol
------------------- -------
2021.11.01T10:00:00 15
2021.11.01T10:00:05 45
2021.11.01T10:00:10 55 2.4. segment 窗口
以上所有例子中,窗口大小均固定。在 DolphinDB 中亦可将连续的相同元素作为一个窗口,用 segment 来实现。实际场景中,segment 经常用于逐笔数据中。
下面的例子是根据 order_type 中的数据进行窗口分割,连续相同的 order_type 做累计成交额计算。
vol = 0.1 0.2 0.1 0.2 0.1 0.2 0.1 0.2 0.1 0.2 0.1 0.2
order_type = 0 0 1 1 1 2 2 1 1 3 3 2;
t = table(vol,order_type);
select *, cumsum(vol) as cumsum_vol from t context by segment(order_type);
# output
vol order_type cumsum_vol
--- ---------- ----------
0.1 0 0.1
0.2 0 0.3
0.1 1 0.1
0.2 1 0.3
0.1 1 0.4
0.2 2 0.2
0.1 2 0.3
0.2 1 0.2
0.1 1 0.3
0.2 3 0.2
0.1 3 0.3
0.2 2 0.2 2.5. 窗口连接计算
在 DolphinDB 中,除了常规的窗口计算之外,还支持窗口连接计算。即在表连接的同时,进行窗口计算。可以通过 wj 和 pwj 函数来实现 。
window join 基于左表每条记录的时间戳,确定一个时间窗口,并计算对应时间窗口内右表的数据。左表每滑动一条记录,都会与右表窗口计算的结果连接。因为窗口的左右边界均可以指定,也可以为负数,所以也可以看作非常灵活的滑动窗口。
详细用法参见用户手册 window join。
//data
t1 = table(1 1 2 as sym, 09:56:06 09:56:07 09:56:06 as time, 10.6 10.7 20.6 as price)
t2 = table(take(1,10) join take(2,10) as sym, take(09:56:00+1..10,20) as time, (10+(1..10)\10-0.05) join (20+(1..10)\10-0.05) as bid, (10+(1..10)\10+0.05) join (20+(1..10)\10+0.05) as offer, take(100 300 800 200 600, 20) as volume);
//window join
wj(t1, t2, -5s:0s, <avg(bid)>, `sym`time);
# output
sym time price avg_bid
--- -------- ----- -------
1 09:56:06 10.6 10.3
1 09:56:07 10.7 10.4
2 09:56:06 20.6 20.3 由于窗口可以灵活设置,所以不仅是多表连接的时候会用到,单表内部的窗口计算也可以用到 window join。下面的例子可以看作是 t2 表中每一条数据做一个 (time-6s) 到 (time+1s) 的计算。
t2 = table(take(1,10) join take(2,10) as sym, take(09:56:00+1..10,20) as time, (10+(1..10)\10-0.05) join (20+(1..10)\10-0.05) as bid, (10+(1..10)\10+0.05) join (20+(1..10)\10+0.05) as offer, take(100 300 800 200 600, 20) as volume);
wj(t2, t2, -6s:1s, <avg(bid)>, `sym`time);
# output
sym time bid offer volume avg_bid
--- -------- ---- ------ ------ --------
1 09:56:01 10.05 10.15 100 10.1
...
1 09:56:08 10.75 10.85 800 10.5
1 09:56:09 10.85 10.95 200 10.6
1 09:56:10 10.95 11.05 600 10.65
2 09:56:01 20.05 20.15 100 20.1
2 09:56:02 20.15 20.25 300 20.15
...
2 09:56:08 20.75 20.85 800 20.5
2 09:56:09 20.85 20.9 200 20.6
2 09:56:10 20.95 21.05 600 20.65从1.30.16/2.00.4版本开始,亦可使用 window 函数以及 twindow 函数实现单表内部的灵活窗口计算。
以上 wj 的代码也可以用 twindow 或 window 实现:
t2 = table(take(1,10) join take(2,10) as sym, take(09:56:00+1..10,20) as time, (10+(1..10)\10-0.05) join (20+(1..10)\10-0.05) as bid, (10+(1..10)\10+0.05) join (20+(1..10)\10+0.05) as offer, take(100 300 800 200 600, 20) as volume);
//twindow
select *, twindow(avg,t2.bid,t2.time,-6s:1s) from t2 context by sym
//window
select *, window(avg, t2.time.indexedSeries(t2.bid), -6s:1s) from t2 context by sym
# output
sym time bid offer volume avg_bid
--- -------- ---- ------ ------ --------
1 09:56:01 10.05 10.15 100 10.1
...
1 09:56:08 10.75 10.85 800 10.5
1 09:56:09 10.85 10.95 200 10.6
1 09:56:10 10.95 11.05 600 10.65
2 09:56:01 20.05 20.15 100 20.1
2 09:56:02 20.15 20.25 300 20.15
...
2 09:56:08 20.75 20.85 800 20.5
2 09:56:09 20.85 20.9 200 20.6
2 09:56:10 20.95 21.05 600 20.653. 对矩阵使用窗口计算
表的窗口计算在前一章节已经描述,所以在这一章节中着重讨论矩阵的计算。
3.1. 矩阵的滑动窗口计算
滑动窗口 m 系列函数以及 window 函数可以用于处理矩阵,在矩阵每列内进行计算,返回一个与输入矩阵维度相同的矩阵。如果滑动维度为时间,则要先使用 setIndexedMatrix! 函数将矩阵的行与列标签设为索引。这里需要注意的是,行与列标签均须严格递增。
首先我们新建一个矩阵,并将其设为 IndexedMatrix:
m=matrix(1..4 join 6, 11..13 join 8..9)
m.rename!(2020.01.01..2020.01.04 join 2020.01.06,`A`B)
m.setIndexedMatrix!();3.1.1. 步长为1行,窗口为n行
m 系列函数的参数可以是一个正整数(记录数维度)或一个 duration(时间维度)。通过设定不同的参数,可以指定理想的滑动窗口类型。
以 msum 滑动求和为例。以下例子是对一个矩阵内部,对每一列进行窗口长度为3行的滑动求和计算。
msum(m,3,1)
# output
A B
-- --
2020.01.01|1 11
2020.01.02|3 23
2020.01.03|6 36
2020.01.04|9 33
2020.01.06|13 30矩阵运算中,也可以做复杂的窗口嵌套。曾在2.2.1节中提到的98号因子也可以在矩阵中通过几行代码实现(trade 表有需要可以自行模拟数据,或用 sample 数据 CNTRADE):
// 输入表trade的schema如下,如需要可自行模拟数据:
name typeString typeInt
---------- ---------- -------
ts_code SYMBOL 17
trade_date DATE 6
open DOUBLE 16
vol DOUBLE 16
amount DOUBLE 16
// alpha 98 的矩阵计算
def prepareDataForDDBPanel(){
t = select trade_date,ts_code,amount*1000/(vol*100 + 1) as vwap,vol,open from trade
return dict(`vwap`open`vol, panel(t.trade_date, t.ts_code, [t.vwap, t.open, t.vol]))
}
def myrank(x) {
return rowRank(x)\x.columns()
}
def alpha98Panel(vwap, open, vol){
return myrank(mavg(mcorr(vwap, msum(mavg(vol, 5), 26), 5), 1..7)) - myrank(mavg(mrank(9 - mimin(mcorr(myrank(open), myrank(mavg(vol, 15)), 21), 9), true, 7), 1..8))
}
input = prepareDataForDDBPanel()
alpha98DDBPanel = alpha98Panel(input.vwap, input.open, input.vol)3.1.2. 步长为1行,窗口为指定时间
以msum滑动求和为例。以下例子是对一个矩阵内部,每一列根据左边的时间列进行窗口大小为3天的滑动求和计算。
msum(m,3d)
# output
A B
-- --
2020.01.01|1 11
2020.01.02|3 23
2020.01.03|6 36
2020.01.04|9 33
2020.01.06|10 17在实际运用中,这类矩阵窗口运算非常常见。比如在做历史分位的计算中,将数据转化为 IndexedMatrix 之后,直接用一行代码就可以得到结果了。
下面例子对 m 矩阵做10年的历史分位计算:
//推荐使用1.30.14, 2.00.2及以上版本来使用 mrank 函数。
mrank(m, true, 10y, percent=true)
# output
A B
- ----
2020.01.01|1 1
2020.01.02|1 1
2020.01.03|1 1
2020.01.04|1 0.25
2020.01.06|1 0.43.2. 矩阵的累计窗口计算
在矩阵中,累计函数 cum 系列也可以直接使用。以 cumsum 为例:
cumsum(m)
# output
A B
-- --
2020.01.01|1 11
2020.01.02|3 23
2020.01.03|6 36
2020.01.04|10 44
2020.01.06|16 53结果为在矩阵的每一列,计算累计和。
4. 流式数据的窗口计算
在 DolphindDB 中,设计了许多内置的流计算引擎。有些支持聚合计算,有些则支持滑动窗口或者累计窗口计算,也有针对于流数据的会话窗口引擎,可以满足不同的场景需求。下面根据不同窗口以及引擎分别介绍。
4.1. 滚动窗口在流计算中的应用
实际场景中,滚动窗口计算在流数据中的应用最为广泛,比如5分钟 k 线,1分钟累计交易量等。滚动窗口在流计算中的应用通过各种时间序列引擎实现。
createTimeSeriesEngine 时间序列引擎应用广泛,类似的引擎还有 createDailyTimeSeriesEngine 与 createSessionWindowEngine。createDailyTimeSeriesEngine 与 dailyAlignedBar类似,可以指定时间段进行窗口计算,而非按照流入数据的时间窗口聚合计算。createSessionWindowEngine 会在4.3中详细介绍。
本节以 createTimeSeriesEngine 为例。
下例中,时间序列引擎 timeSeries1 订阅流数据表 trades,实时计算表 trades 中过去1分钟内每只股票交易量之和。
share streamTable(1000:0, `time`sym`volume, [TIMESTAMP, SYMBOL, INT]) as trades
output1 = table(10000:0, `time`sym`sumVolume, [TIMESTAMP, SYMBOL, INT])
timeSeries1 = createTimeSeriesEngine(name="timeSeries1", windowSize=60000, step=60000, metrics=<[sum(volume)]>, dummyTable=trades, outputTable=output1, timeColumn=`time, useSystemTime=false, keyColumn=`sym, garbageSize=50, useWindowStartTime=false)
subscribeTable(tableName="trades", actionName="timeSeries1", offset=0, handler=append!{timeSeries1}, msgAsTable=true);
insert into trades values(2018.10.08T01:01:01.785,`A,10)
insert into trades values(2018.10.08T01:01:02.125,`B,26)
insert into trades values(2018.10.08T01:01:10.263,`B,14)
insert into trades values(2018.10.08T01:01:12.457,`A,28)
insert into trades values(2018.10.08T01:02:10.789,`A,15)
insert into trades values(2018.10.08T01:02:12.005,`B,9)
insert into trades values(2018.10.08T01:02:30.021,`A,10)
insert into trades values(2018.10.08T01:04:02.236,`A,29)
insert into trades values(2018.10.08T01:04:04.412,`B,32)
insert into trades values(2018.10.08T01:04:05.152,`B,23)
sleep(10)
select * from output1;
# output
time sym sumVolume
----------------------- --- ---------
2018.10.08T01:02:00.000 A 38
2018.10.08T01:02:00.000 B 40
2018.10.08T01:03:00.000 A 25
2018.10.08T01:03:00.000 B 9
//to drop the time series engine
dropStreamEngine(`timeSeries1)
unsubscribeTable(tableName="trades", actionName="timeSeries1")
undef("trades",SHARED)4.2. 滑动、累计窗口在流计算中的应用
另一个常用的引擎是响应式状态引擎 createReactiveStateEngine。在这个引擎中,我们可以使用经过优化的状态函数,其中包括累计窗口函数(cum 系列函数)和滑动窗口函数(m 系列函数以及 tm 系列函数)。
createReactiveStateEngine 响应式状态引擎的功能非常强大,可以让流数据像 SQL 一样处理,实现批流一体。下面的例子同时展示了 cum 系列函数,m 系列函数和 tm 系列函数在createReactiveStateEngine 响应式状态引擎中的作用。
//1.30.14,2.00.2以上版本支持tmsum函数。
share streamTable(1000:0, `time`sym`volume, [TIMESTAMP, SYMBOL, INT]) as trades
output2 = table(10000:0, `sym`time`Volume`msumVolume`cumsumVolume`tmsumVolume, [ SYMBOL,TIMESTAMP,INT, INT,INT,INT])
reactiveState1= createReactiveStateEngine(name="reactiveState1", metrics=[<time>,<Volume>,<msum(volume,2,1)>,<cumsum(volume)>,<tmsum(time,volume,2m)>], dummyTable=trades, outputTable=output2, keyColumn="sym")
subscribeTable(tableName="trades", actionName="reactiveState1", offset=0, handler=append!{reactiveState1}, msgAsTable=true);
insert into trades values(2018.10.08T01:01:01.785,`A,10)
insert into trades values(2018.10.08T01:01:02.125,`B,26)
insert into trades values(2018.10.08T01:01:10.263,`B,14)
insert into trades values(2018.10.08T01:01:12.457,`A,28)
insert into trades values(2018.10.08T01:02:10.789,`A,15)
insert into trades values(2018.10.08T01:02:12.005,`B,9)
insert into trades values(2018.10.08T01:02:30.021,`A,10)
insert into trades values(2018.10.08T01:04:02.236,`A,29)
insert into trades values(2018.10.08T01:04:04.412,`B,32)
insert into trades values(2018.10.08T01:04:05.152,`B,23)
sleep(10)
select * from output2
# output
sym time Volume msumVolume cumsumVolume tmsumVolume
--- ----------------------- ------ ---------- ------------ -----------
A 2018.10.08T01:01:01.785 10 10 10 10
B 2018.10.08T01:01:02.125 26 26 26 26
A 2018.10.08T01:01:12.457 28 38 38 38
B 2018.10.08T01:01:10.263 14 40 40 40
A 2018.10.08T01:02:10.789 15 43 53 53
B 2018.10.08T01:02:12.005 9 23 49 49
A 2018.10.08T01:02:30.021 10 25 63 63
A 2018.10.08T01:04:02.236 29 39 92 54
B 2018.10.08T01:04:04.412 32 41 81 41
B 2018.10.08T01:04:05.152 23 55 104 64
//to drop the reactive state engine
dropAggregator(`reactiveState1)
unsubscribeTable(tableName="trades", actionName="reactiveState1")
undef("trades",SHARED)4.3. 会话窗口引擎
createSessionWindowEngine 可以根据间隔时间(session gap)切分不同的窗口,即当一个窗口在session gap 时间内没有接收到新数据时,窗口会关闭。所以这个引擎中的window size会根据流入数据的情况发生变化。
具体可以看以下例子:
share streamTable(1000:0, `time`volume, [TIMESTAMP, INT]) as trades
output1 = keyedTable(`time,10000:0, `time`sumVolume, [TIMESTAMP, INT])
engine_sw = createSessionWindowEngine(name = "engine_sw", sessionGap = 5, metrics = <sum(volume)>, dummyTable = trades, outputTable = output1, timeColumn = `time)
subscribeTable(tableName="trades", actionName="append_engine_sw", offset=0, handler=append!{engine_sw}, msgAsTable=true)
n = 5
timev = 2018.10.12T10:01:00.000 + (1..n)
volumev = (1..n)%1000
insert into trades values(timev, volumev)
n = 5
timev = 2018.10.12T10:01:00.010 + (1..n)
volumev = (1..n)%1000
insert into trades values(timev, volumev)
n = 3
timev = 2018.10.12T10:01:00.020 + (1..n)
volumev = (1..n)%1000
timev.append!(2018.10.12T10:01:00.027 + (1..n))
volumev.append!((1..n)%1000)
insert into trades values(timev, volumev)
select * from trades;
//传入数据如下:
time volume
----------------------- ------
2018.10.12T10:01:00.001 1
2018.10.12T10:01:00.002 2
2018.10.12T10:01:00.003 3
2018.10.12T10:01:00.004 4
2018.10.12T10:01:00.005 5
2018.10.12T10:01:00.011 1
2018.10.12T10:01:00.012 2
2018.10.12T10:01:00.013 3
2018.10.12T10:01:00.014 4
2018.10.12T10:01:00.015 5
2018.10.12T10:01:00.021 1
2018.10.12T10:01:00.022 2
2018.10.12T10:01:00.023 3
2018.10.12T10:01:00.028 1
2018.10.12T10:01:00.029 2
2018.10.12T10:01:00.030 3
//经过createSessionWindowEngine会话窗口引擎后,根据session gap=5(ms)聚合形成的窗口计算结果为:
select * from output1
time sumVolume
----------------------- ---------
2018.10.12T10:01:00.001 15
2018.10.12T10:01:00.011 15
2018.10.12T10:01:00.021 6
// to drop SessionWindowEngine
unsubscribeTable(tableName="trades", actionName="append_engine_sw")
dropAggregator(`engine_sw)
undef("trades",SHARED)5. 窗口计算的空值处理规则
在 DolphinDB 中,各个窗口函数的空值处理略有不同,本节将阐述各个系列函数空值处理的规则:
5.1. moving,m 系列函数,tm 系列函数以及 cum 系列函数的空值处理
在 mrank,tmrank 以及 cumrank 函数中,可以指定 NULL 值是否参与计算。其他窗口函数与聚合函数保持一致,计算时忽略 NULL 值。
moving 以及大部分 m 系列函数参数里都有一个可选参数 minPeriods。若没有指定 minPeriods,结果的前 (window - 1) 个元素为NULL;若指定了 minPeriods,结果的前 ( minPeriods - 1) 个元素为 NULL。如果窗口中的值全为 NULL,该窗口的计算结果为 NULL。minPeriods 的默认值为 window 之值。
一个简单的例子:
m=matrix(1..5, 6 7 8 NULL 10)
//不指定 minPeriods 时,由于 minPeriods 默认值与 window 相等,所以结果的前二行均为 NULL。
msum(m,3)
#0 #1
-- --
6 21
9 15
12 18
//若指定 minPeriods=1,结果的前二行不是 NULL 值。
msum(m,3,1)
#0 #1
-- --
1 6
3 13
6 21
9 15
12 185.2. rolling 的空值处理
与 moving函数不同的是,rolling 函数不输出前 (window - 1) 个元素的 NULL 值结果。可以通过下面的例子来感受:
t 是一个包含 NULL 值的表,我们分别用 rolling 和 moving 对 vol 这一列做窗口为3行的求和计算。
vol=1 2 3 4 NULL NULL NULL 6 7 8
t= table(vol)
//rolling做窗口为3行的滑动求和计算
rolling(sum,t.vol,3)
# output
[6,9,7,4,,6,13,21]
//moving做窗口为3行的滑动求和计算
moving(sum,t.vol,3)
# output
[,,6,9,7,4,,6,13,21]
//rolling做窗口为3行,步长为2行的窗口计算
rolling(sum,t.vol,3,2)
# output
[6,7,,13] ///最后的窗口没有足够的元素时,不会输出6. 常用指标的计算复杂度
假设共有 n 个元素,窗口大小为 m,那么常用的 m 系列,tm 系列函数都经过了优化,其时间复杂度为 O(n),即每一次计算结果只会把位置0去掉,加入新的观察值。 而 mrank 与其他函数稍许不同,计算速度会比其他的慢,原因是其时间复杂度为O(mn),与其窗口长度有关,窗口越大,复杂度越高。即每一次都会将结果重置。
moving,tmoving,rolling, window, twindow 这些高阶函数的复杂度与其参数内的 func 有关,是没有做过优化的。所以每一次滑动都是整个窗口对于 func 函数进行计算,而非 m 系列,tm 系列函数的增量计算。
故相比于 moving,tmoving,rolling, window, 和 twindow 这些高阶函数, m 系列和 tm 系列函数对于相同的计算功能会有更好的性能。
一个简单的例子:
n=1000000
x=norm(0,1, n);
//moving
timer moving(avg, x, 10);
Time elapsed: 243.331 ms
//rolling
timer rolling(avg, x, 10);
Time elapsed: 599.389ms
//mavg
timer mavg(x, 10);
Time elapsed: 3.501ms7. 涉及到窗口计算的函数
| 聚合函数 | m系列 | ReactiveStateEngine 是否支持 | tm系列 | ReactiveStateEngine 是否支持 | cum系列 | ReactiveStateEngine 是否支持 |
|---|---|---|---|---|---|---|
| moving(高阶函数) | √ | tmoving(高阶函数) | √ | |||
| window(高阶函数) | 可用WndowJoinEngine | twindow(高阶函数) | 可用WndowJoinEngine | |||
| avg | mavg | √ | tmavg | √ | cumavg | √ |
| sum | msum | √ | tmsum | √ | cumsum | √ |
| beta | mbeta | √ | tmbeta | √ | cumbeta | √ |
| corr | mcorr | √ | tmcorr | √ | cumcorr | √ |
| count | mcount | √ | tmcount | √ | cumcount | √ |
| covar | mcovar | √ | tmcovar | √ | cumcovar | √ |
| imax | mimax | √ | ||||
| imin | mimin | √ | ||||
| max | mmax | √ | tmmax | √ | cummax | √ |
| min | mmin | √ | tmmin | √ | cummin | √ |
| first | mfirst | √ | tmfirst | √ | ||
| last | mlast | √ | tmlast | √ | ||
| med | mmed | √ | tmmed | √ | cummed | |
| prod | mprod | √ | tmprod | √ | cumprod | √ |
| var | mvar | √ | tmvar | √ | cumvar | √ |
| varp | mvarp | √ | tmvarp | √ | cumvarp | √ |
| std | mstd | √ | tmstd | √ | cumstd | √ |
| stdp | mstdp | √ | tmstdp | √ | cumstdp | √ |
| skew | mskew | √ | tmskew | √ | ||
| kurtosis | mkurtosis | √ | tmkurtosis | √ | ||
| percentile | mpercentile | √ | tmpercentile | √ | cumpercentile | |
| rank | mrank | √ | tmrank | √ | cumrank | |
| wsum | mwsum | √ | tmwsum | √ | cumwsum | √ |
| wavg | mwavg | √ | tmwavg | √ | cumwavg | √ |
| ifirstNot | mifirstNot | |||||
| ilastNot | milastNot | |||||
| firstNot | cumfirstNot | √ | ||||
| lastNot | cumlastNot | √ | ||||
| mad | mmad | √ | ||||
| move | √ | tmove | √ | |||
| mslr | √ | |||||
| ema | √ | |||||
| kama | √ | |||||
| sma | √ | |||||
| wma | √ | |||||
| dema | √ | |||||
| tema | √ | |||||
| trima | √ | |||||
| t3 | √ | |||||
| ma | √ | |||||
| wilder | √ | |||||
| gema | √ | |||||
| linearTimeTrend | √ | |||||
| mse | mmse | |||||
| cumPositiveStreak |
其他涉及窗口的函数:
deltas, ratios, interval, bar, dailyAlignedBar, coevent, createReactiveStateEngine, createDailyTimeSeriesEngine, createReactiveStateEngine, createSessionWindowEngine
8. 总结
DolphinDB 中的窗口函数功能非常齐全。合理运用窗口,能够简便地实现各种复杂逻辑,使数据分析步骤更简洁,效率更高。