Natural Language Database Interaction System Based on DolphinDB and Vanna
Vanna is an open-source AI agent framework designed for natural language interaction with databases. By combining retrieval-augmented generation (RAG) and interactive SQL execution, it enables users to ask questions in natural language, Then it can automatically generate queries and return human-readable results. Vanna is highly scalable, supporting user-defined vector databases for storing embeddings, and enabling connections to and queries from any database.
DolphinDB's document retrieval database system (TextDB) and vector retrieval database system (VectorDB) can be used to implement an RAG-bsed knowledge base. This tutorial shows how to integrate Vanna with DolphinDB: storing documents and embeddings in DolphinDB, then enabling Vanna to query DolphinDB and generate DolphinDB-compatible SQL or scripts. A DolphinDB-based RAG framework offers the following advantages:
- Efficient retrieval and response for massive text and vector data.
- Rich and convenient computing functions for data processing.
- One-stop solution for storage, retrieval, and computing.
1. Key Components
1.1 TextDB
DolphinDB version 3.00.2 introduced TextDB, a document retrieval database system based on the PKEY storage engine. TextDB is designed to further enhance information retrieval with efficient full-text search using inverted indexes, making it well-suited for handling unstructured text data. This tutorial applies TextDB to store chunked DolphinDB function documents.
1.2 VectorDB
Since version 3.00.1, DolphinDB introduces VectorDB, a vector retrieval database system built on the TSDB storage engine. It applies rapid approximate nearest neighbor search (ANNS) to array vector columns. This tutorial applies VectorDB to store the embedding vectors of the texts.
1.3 Vanna
Vanna, distributed as a Python package, leverages RAG to help users generate precise SQL queries for databases using large language models (LLMs). Its workflow is as follows:
- Trains an RAG model based on data such as database schema and historical queries.
- Generates SQL statements from natural language questions, with optional direct execution.
In this tutorial, Vanna is adapted to DolphinDB by creating a DolphinDBVanna class that inherits from VannaBase and overrides the relevant functions.
1.4 DolphinDB Python API
The DolphinDB API allows seamless data transfer and script execution between the DolphinDB server and Python client. Using the DolphinDB API, you can leverage DolphinDB's powerful computing and storage capabilities to manipulate, analyze and model data within a Python environment. In this tutorial, the Python API is used to connect to DolphinDB and execute queries.
2. System Workflow
To improve the RAG accuracy, it is crucial to provide the LLM with proper context. Since most LLMs are not proficient in writing DolphinDB scripts, we build a knowledge base from chunked DolphinDB documents. For each question, VectorDB and TextDB quickly retrieve relevant content, which is then supplied to the LLM to guide SQL/script generation. The overall process is shown below:
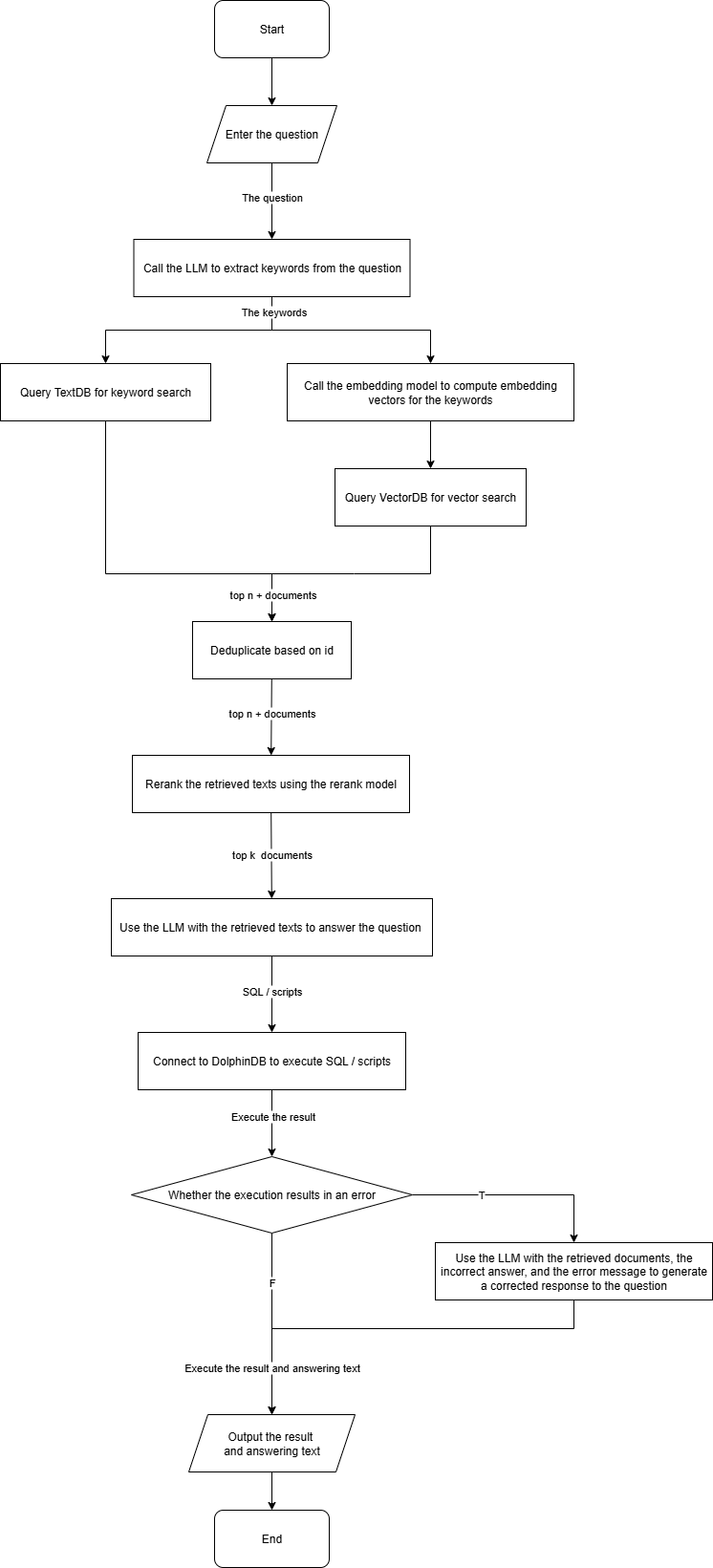
The overall process is largely consistent with the official Vanna framework. To improve accuracy, we introduce tokenization and reranking. The steps are as follows:
- Use the LLM to extract keywords from the entered question.
- Retrieve relevant documents via two approaches:
- Directly query the TextDB with keywords for text matching.
- Compute embeddings of the keywords using an embedding model, then query the VectorDB for vector search.
- Deduplicate retrieved documents by id and keep the top n+ relevant ones.
- Apply a rerank model to reorder the documents and select the top k relevant ones.
- Construct a prompt with these relevant documents and the entered question, then call the LLM to generate the answer and script.
- Execute the script in DolphinDB.
- If no error occurs, output the answer and execution result.
- If an error occurs and the user clicks the Correct button, generate a new prompt with the relevant documents, the query error, and the error message, then call the LLM again to refine the response.
- Output the corrected answer and script.
3. API References
3.1 Configuration
The DolphinDBVanna class is the backend core, supporting official Vanna parameters. The following table lists additional parameters that can be set via a config dictionary during initialization.
| Configuration Parameters | Data Type | Description |
|---|---|---|
| llm_api_key | STRING | LLM API authentication key |
| llm_api_url | STRING | LLM API request URL |
| llm_model | STRING | LLM model name |
| embedding_api_key | STRING | Embedding API authentication key |
| embedding_api_url | STRING | Embedding API request URL |
| embedding_model | STRING | Embedding model name |
| reranker_api_key | STRING | Reranker API authentication key |
| reranker_api_url | STRING | Reranker API request URL |
| reranker_model | STRING | Reranker model name |
| ddb_host | STRING | DolphinDB node host address |
| ddb_port | Positive Integer | DolphinDB node port number |
| ddb_userid | STRING | DolphinDB username |
| ddb_password | STRING | DolphinDB password |
3.2 Major Functions
This section introduces major functions, their logics, and considerations, including modifications to the Vanna APIs and their usage introduction.
3.2.1 train
The train function trains the RAG framework by computing embeddings for questions and answers and storing them in the VectorDB. It is essentially a wrapper function that calls different sub-functions based on the input parameters:
- add_ddl: Computes embeddings for DDL text and stores them in the VectorDB.
- add_document: Computes embeddings for documents and stores them in the VectorDB.
- add_question_sql: Computes embeddings for question-SQL pairs and stores them in the VectorDB.
We override these functions to call remote LLMs via Python's requests library and connect to a DolphinDB node through the DolphinDB Python API, writing both texts and vector data.
For example:
vn.train(ddl='''
create database "dfs://test"
partitioned by VALUE(1..10), HASH([SYMBOL, 40])
engine='TSDB'
''')3.2.2 ask
The ask function handles queries by converting a question into SQL or DolphinDB scripts and executing them, with optional parameters for charting and training. We override the extract_sql method invoked by ask to extract and execute the script enclosed in the ```DolphinDB``` tag from the answer.
For example:
vn.ask("Query the first 100 rows of data from the merge_tradeTB table in the merge_TB database")Note: To avoid potential performance or security issues caused by the automatic execution of SQL or scripts, it is recommended to configure a Vanna account with read-only access to distributed databases and tables, and to limit the memory size for a query result. For details, refer to User Access Control.
3.2.3 generate_sql
The ask function performs multiple operations such as
executing SQL, generating charts, and training, which may result in slower
response and pose performance and security risks. If you only need the LLM
to generate SQL or scripts based on relevant documents, use the
generate_sql function instead.
For example:
vn.generate_sql("How to perform a full join in DolphinDB?")4. Implementation of DolphinDB Script-Based QA System
4.1 Create Databases and Tables (The Knowledge Base)
Create a database and table in DolphinDB to store document texts and their embedding vectors. The table fields are as follows:
| Field Name | Data Type | Description | Notes |
|---|---|---|---|
| id | UUID | Document ID | |
| type | SYMBOL |
Document type:
|
|
| name | STRING |
Document name, formatted according to its type:
|
|
| question | STRING |
The question corresponding to content. Required when type = sql; otherwise empty. |
Text index |
| content | STRING | Document content | Text index |
| embedding | FLOAT[] | embedding vector | Vector index |
| createTime | TIMESTAMP | The create time |
The script for creating a database and a table:
db = database(dbpath, VALUE, 2025.01.01..2025.12.31, engine="PKEY")
schemaTb = table(1:0, `id`type`name`question`content`embedding`createTime, [UUID, SYMBOL, STRING, STRING, STRING, FLOAT[], TIMESTAMP])
pt = createPartitionedTable(
dbHandle=db,
table=schemaTb,
tableName=tbname,
partitionColumns=`createTime,
primaryKey=`createTime`id,
indexes={
"question":"textindex(parser=english,full=false,lowercase=true,stem=true)",
"content":"textindex(parser=english,full=false,lowercase=true,stem=true)",
"embedding":"vectorindex(type=flat, dim=1536)"
}
)Specifications:
- When creating a database, specify engine="PKEY", i.e., the Primary Key Storage Engine.
- When creating a table:
- configure id as the primary key to enable efficient read and write operations.
- configure a text index on the question and content columns to support fast keyword matching.
- configure a vector index on the embedding column to support efficient approximate vector search.
4.2 Training
Before using Vanna, preprocess existing documents by chunking, computing embeddings, and storing them. This way, Vanna can retrieve relevant references during Q&A. Documents are categorized into three types:
- sql: User-executed SQL statements
- doc: API documentation
- ddl: DDL statements
This section introduces how to import the three types of documents:
4.2.1 Import User-Defined Question-SQL Pairs
According to Vanna's official Training Advice, the most consequential training data is the known correct question to SQL pairs—for each question, the SQL statement that answers it. Such pairs helps the LLM better understand and respond to similar questions more accurately.
The training set should be based on actual data. For example, given a database dfs://level2 with a snapshot table storing level2 snapshot data, a question–SQL pair could be:
Question: Query the first 10 rows of level2 snapshot data for 2025.04.27
SQL: select top 10 * from loadTable('dfs://level2', 'snapshot') where TradeDay = 2025.04.27 limit 10
This indicates that the question can be answered with the given SQL statement.
We override the add_question_sql method of VannaBase for
adding new question–SQL pairs via Python. For example:
vn.add_question_sql(
"Query the first 10 rows of level2 snapshot data for 2025.04.27",
"select top 10 * from loadTable('dfs://level2', 'snapshot') where TradeDay = 2025.04.27"
)
# Or
vn.train(
question="Query the first 10 rows of level2 snapshot data for 2025.04.27",
sql="select top 10 * from loadTable('dfs://level2', 'snapshot') where TradeDay = 2025.04.27"
)4.2.2 Process and Import Documents
Preprocess DolphinDB's API documents by chunking, computing embeddings, and importing them into the knowledge base. This enables Vanna to recognize available functions during queries and generate more accurate SQL statements or scripts. We implemented a DolphinDB script to handle this process. The workflow is as follows:
- Recursively read all md files in the specified folder and write their content to a target CSV file.
- Load the CSV file and chunk long rows.
- Use the httpClient plugin to compute embeddings for the chunks via an external model.
- Write the document chunks and embeddings into the knowledge base.
See method importDoc in the appendix import.dos for full scripts.
We also override the add_documentation method of VannaBase
for adding a new document via Python. For example:
vn.add_documentation("Defined a function view xxx for querying xxx")
# Or
vn.train(documentation="Defined a function view xxx for querying xxx")4.2.3 Generate and Import DDL Statements
Extract the DDL statements of current DolphinDB databases and tables, compute their embeddings, and import them into the knowledge base. This helps Vanna understand database schema and generate more accurate SQL statements or scripts. We implemented a DolphinDB script for this process. The workflow is as follows:
- Use the ops module's
getDatabaseDDLandgetDBTableDDLmethods to extract all DDL statements. - Compute embeddings for the DDL statements via the httpClient plugin and an external model.
- Write the DDL statements and embeddings into the knowledge base.
See method importDDL in the appendix import.dos for full scripts.
We also override the add_ddl method of VannaBase for adding
new DDL entries via Python. For example:
vn.add_ddl('''
create database "dfs://test"
partitioned by VALUE(1..10), HASH([SYMBOL, 40])
engine='TSDB'
''')
# Or
vn.train(ddl='''
create database "dfs://test"
partitioned by VALUE(1..10), HASH([SYMBOL, 40])
engine='TSDB'
''')4.3 Document Keyword Matching
DolphinDB provides text
search functions to search columns with established text indexes. In
this tutorial, we use the matchAny function for keyword matching, which retrieves documents
containing any specified terms. For example, in the
get_related_ddl function, the SQL for querying DDL
statements matching keywords is as follows:
select id, question, content, embedding from loadTable("{self.db_name}", "{self.tb_name}")
where type == "ddl" and matchAny(content, keywords)Note: There are some considerations when using TextDB. To customize or modify functions, ensure that queries properly trigger text index acceleration.
4.4 Vector Similarity Search
DolphinDB provides the rowEuclidean function to query columns with established vector
indexes, which computes the Euclidean distance between an input vector and the
specified vector column. For example, in the get_related_ddl
function, the SQL for querying the DDL statements closest to the keyword
embedding is as follows:
select id, question, content, embedding from loadTable("{self.db_name}", "{self.tb_name}")
where type == "ddl"
order by rowEuclidean(embedding, embedding_) asc
limit {self.top_n}Note: There are some considerations when using VectorDB. To customize or modify functions, use the HINT_EXPLAIN keyword to ensure that queries properly trigger text index acceleration.
5. Dependencies
Install dependencies:
pip install dolphindb
pip install vannaRefer to Offline Installation of Python API for offline installation.
6. Examples
Note: LLM hallucination is inevitable, so please verify the answers.
Before the first use, connect to the DolphinDB data node, update and execute the relevant configuration in import.dos to create Vanna's backend tables and import the DolphinDB documentation and DDL definitions.
Vanna provides the built-in web app (Flask), which can be launched either within Jupyter notebook or independently. Fill in the configuration items in demo.py as described in the Configuration, and then start the web app with the following command:
python demo.pyThe command line outputs the default address of the Vanna web app as http://localhost:8084:
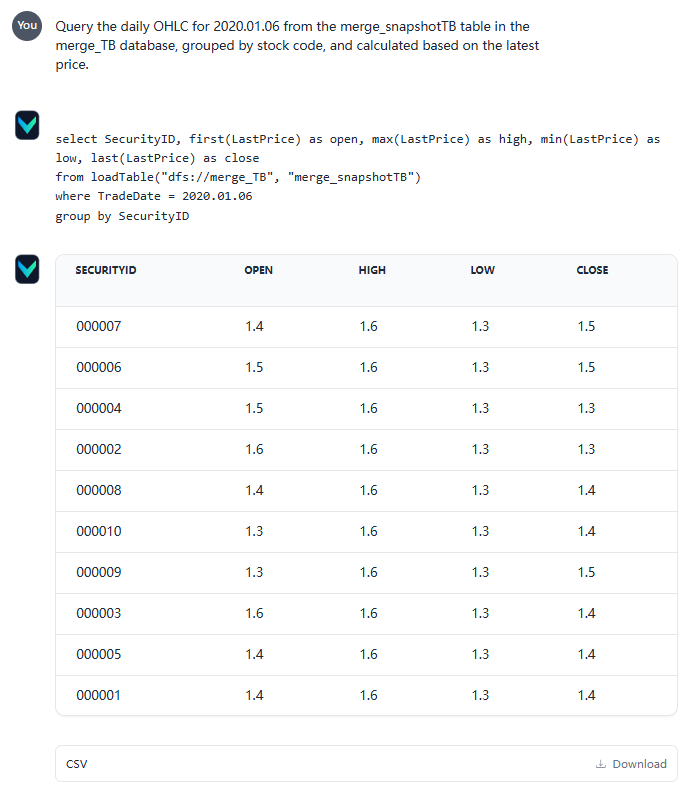
After entering the query, Vanna generates the corresponding SQL statements, executes the query and returns the results
Next, Vanna attempts to visualize the results and provides a text summary:
Then, Vanna asks you whether the answer is correct. Since everything except the chart is correct, you can click Yes, train as Question–SQL pair to save this answer as training data (the chart results are not included in the training):
Then, Vanna provides some followup questions, which you can click to ask:

The following image shows a query error, where a more complex question is asked:
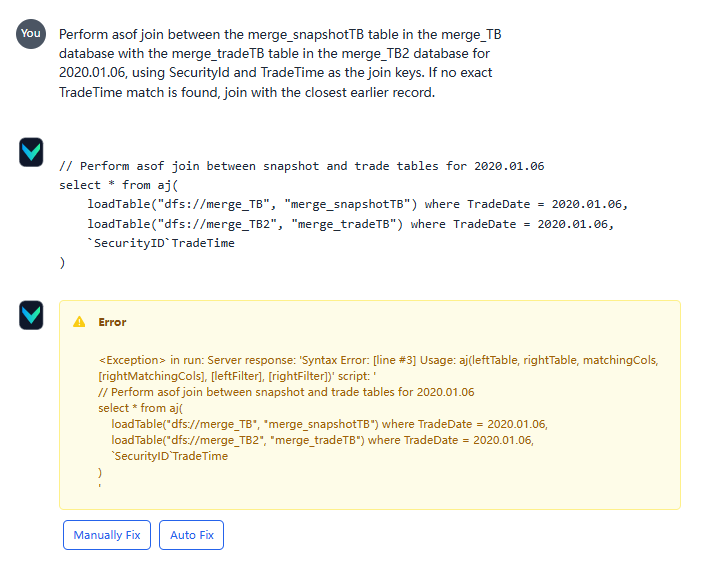
Click the Auto Fix button, and Vanna attempts to correct the error based on the error message, but it still responds with an error:
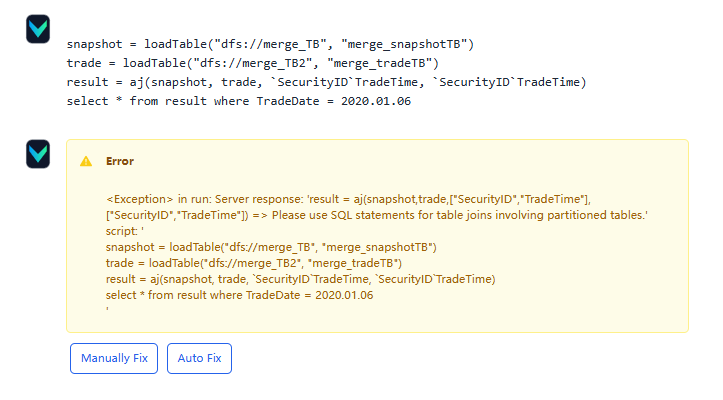
Due to the lack of correct question–SQL pair examples and the DolphinDB-specific syntax of asof join, Vanna struggles to produce the correct answer. Here you can click the Manually Fix button to provide the SQL by yourself:
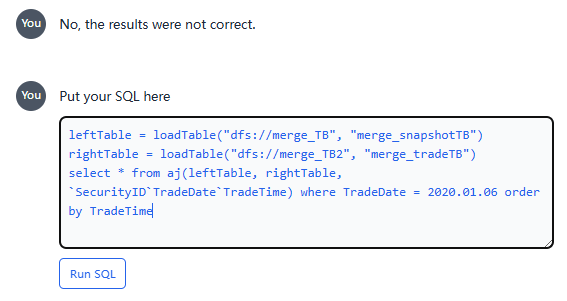
Then, Vanna can provide the correct result. Click Yes, train as Question–SQL pair to save it as training data, improving Vanna's accuracy in answering similar questions in the future.
Create a new chat and ask the same question. This time Vanna can provide the correct answer based on the previous response:
Additionally, you can check the terminal where the program was started to view the printed logs for debugging:
7. Summary
With its high-performance TextDB and VectorDB, DolphinDB provides an ideal foundation for Vanna, enabling it to efficiently process massive volumes of text and vector data, optimize prompt engineering with a rich set of computational functions, and deliver unified storage, retrieval, and analysis. This highlights DolphinDB's outstanding performance and scalability in AI-enhanced database scenarios.