DolphinDB Web Interface: Database and Table Creation Guide
Time-series data is increasingly common across many industries, driving demand for time series databases that achieve fast writes and reads using time-based indexing methods and compression algorithms. However, designing an effective database can be challenging. Common difficulties include:
- Determining data requirements: While users with domain expertise understand the business requirements, they often lack experience in applying it to database planning, including determining data type, structure, relationship, granularity, and scope.
- Selecting storage solutions and optimizing performance: It is often difficult for users without database expertise to select suitable tech stacks, indexing methods, and partition strategies, considering volumes, access patterns and performance.
To address these challenges, DolphinDB Web Interface provides Financial Scenario Guide and IoT Scenario Guide, allowing users to quickly create databases and tables based on basic information.
Note: These optional features are disabled by default. Click Feature Settings in the bottom left corner and click Enable to enable the features.
1. Financial Scenario Guide
Data analytics is critical to business success in financial sector. Accurate tracking of daily increments and the underlying assets is essential for effective database and table design. Daily increment helps forecast future storage demands, guide table schema design and indexing strategies, and optimize query performance. Each asset has distinct data characteristics, requiring tailored table schema. Therefore, the Financial Scenario Guide guides data planning based on these two factors.
In this scenario, users can choose to create tables under an existing database or create new databases and tables. The process includes the following three steps: Create Database, Create Table, and Generate Script.

1.1 Create Database
Create tables under an existing database or add a new database to create tables. The steps are as follows:
- Using Existing Database:
- Select the existing database.
- Creating New Database:
- Enter the database name.
- Select the daily increment.
- Choose the storage engine.
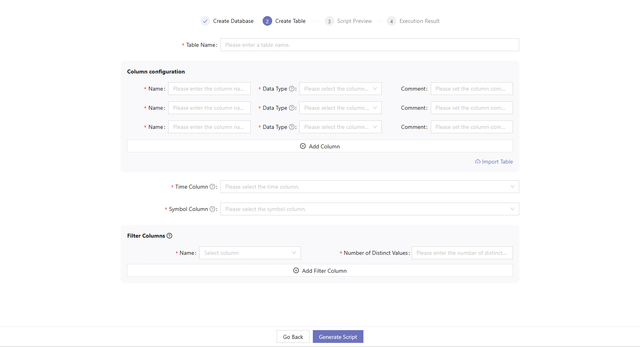
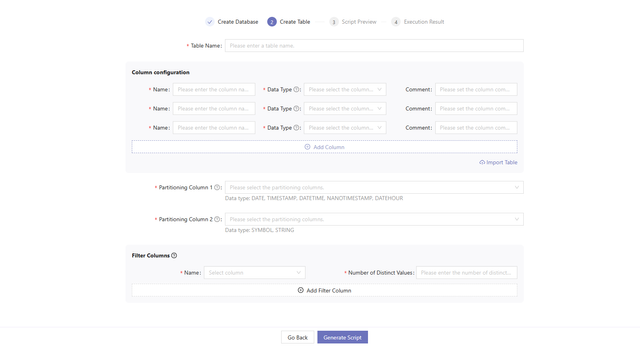
1.2 Create Table
- Enter a table name.
- Configure columns.
The table must have a time column of temporal types, including DATE, DATETIME, TIMESTAMP, and NANOTIMESTAMP.
Methods to configure columns:
- Manually enter the information, including column names, data types and optional comments.
- Extract the columns and data types by importing local csv or txt files or by entering the absolute path of the file on a remote server.
- Select a time column.
This option appears when creating a new database table and the total data volume exceeds 2 million rows. Users need to specify a partitioning column with time series data.
- Select a symbol column.
This option appears when the total data volume exceeds 2 million rows or the daily increment exceeds 1 million rows when creating a new database and table. Specify a partitioning column with enumerated values of SYMBOL or STRING type, such as security ID or futures contract.
- Select partitioning columns.
This option appears when creating a table under an existing databasewith partitions. Select the partitioning columns based on the current partitioning scheme.
- Select filter columns.
Filter columns are frequently used as filtering conditions during queries. It is recommended to arrange these columns by query frequency, with the most commonly used one at the beginning of the list. The number of distinct values determines whether to apply dimensionality reduction. The filter columns must be no more than 2 columns and the data type must be enumerable, such as CHAR, STRING, SYMBOL, etc.
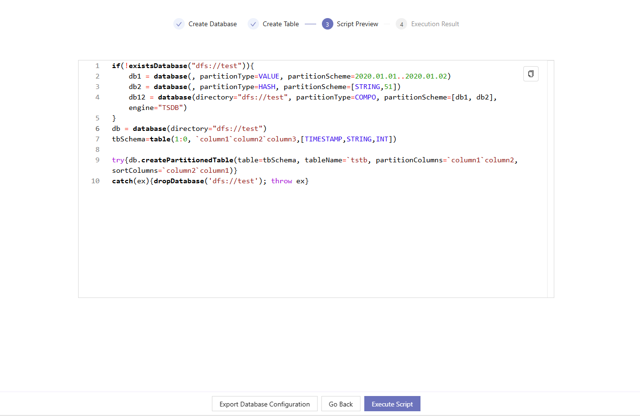
Click Generate Script after filling in the information. The system will jump to the Script Preview page. Users can browse the scripts on this page but cannot modify the script. If the script meets your requirements, click Execute Now to create the table. If you need to optimize the script before execution, copy it to the Editor in Shell for manual changes and execution.
2. IoT Scenario Guide
IoT devices are widely used across various industries. The sensors collect real-time data of the environment, equipment, and process, providing analytical insights for predictive maintenance and optimization. Data structures and primary key column names usually vary across different projects. Therefore, one table per project design is more suitable.
IoT data can be time-series or non-time-series. Time-series data is a sequence of data indexed strictly in time order, such as data collected from measurement points. Non-time-series data don’t have a strict time-based ordering. For example, a device monitoring table may store the device IDs, point IDs, upper/lower bounds for the threshold, and the irregular update time.
From the user’s perspective, the IoT Scenario Guide guides database planning based on familiar concepts, including the number of measurements, collection frequency, daily increment, etc. It offers two types of table creation pages for different users:
- A basic guide for users less familiar with databases, such as IoT experts;
- An advanced guide for users with database knowledge, like database maintainers.
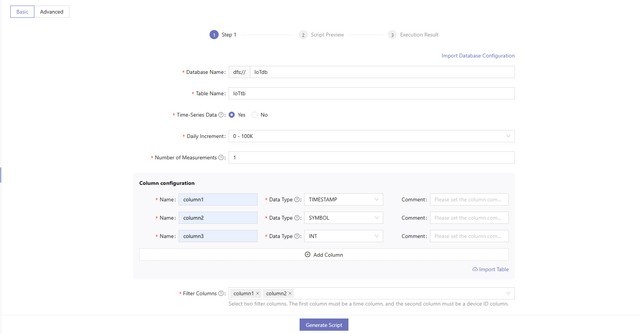
2.1 Basic Guide
On the basic guide page, the system provides default configuration information for storage, indexing, and other related details, making it easier for users to create databases and tables. Users only need to provide the necessary information to generate the script.

- Enter a database name.
- Enter a table name.
- Choose whether it is time-series data. Then,
- Select the daily increment for time-series data and enter the number of measurements.
- Choose or enter the total data volume for non-time-series data.
- Configure columns.
For time-series data and non-time-series data with more than 2 million rows, the system uses the TSDB engine by default. For non-time-series data with less than 2 million rows, it uses the OLAP engine. In IoT scenarios, measurement points are used to collect sensor data and device status. A column is required to store the information of the measurement points. Therefore,
- For time-series data and non-time-series data with more than 2 million rows, at least one time column and one enumeration column are required.
- For non-time-series data with less than 2 million rows, at least one enumeration column is required.
Methods to configure columns:
- Manually enter the information, including column names, data types and optional comments.
- Extract the columns and data types by importing local csv or txt files or by entering the absolute path of the file on a remote server.
- Select filter columns.
Filter columns are frequently used as filtering conditions during queries. It is recommended to arrange these columns by query frequency, with the most commonly used one at the beginning of the list. Number of distinct values determines whether to apply dimensionality reduction. Specify the filter columns according to the following criteria:
- For non-time-series data with less than 2 million rows, no need to select filter columns.
- For time-series data and non-time-series data with more than 2 million rows, the first filter column should be a time column, and the second should be the device ID column.
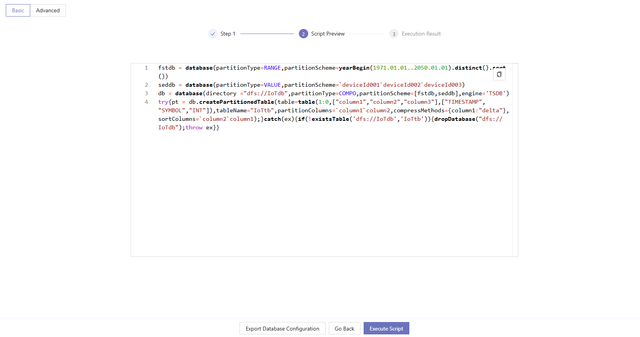
Click Generate Script after filling in the information. The system will jump to the Script Preview page. Users can browse the scripts on this page but cannot modify the script. If the script meets your requirements, click Execute Now to create the table. If you need to optimize the script before execution, copy it to the Editor in Shell for manual changes and execution.
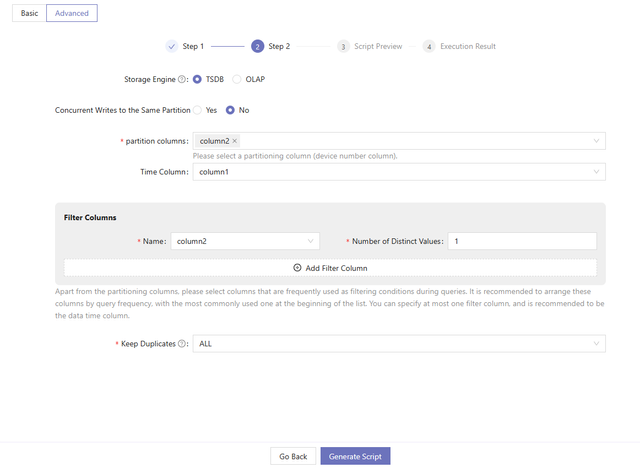
2.2 Advanced Guide
The advanced guide provides more options for users familiar with DolphinDB, including the storage engine, partitioning columns, and the deduplication option. In the advanced guide, database and table information are filled in two steps. Step 1 is the same as described in the basic guide.
The system will provide Step 2 for time-series data and non-time-series data with more than 2 million rows. It should be noted that non-time-series data in IoT scenarios may still have temporal columns. For instance, device monitoring tables store the update time for the threshold. However, the update intervals are irregular.
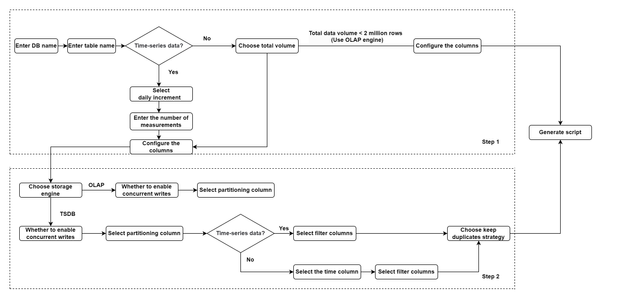
- Choose the storage engine: OLAP or TSDB.
- Choose whether to enable concurrent writes to the same partition.
- Enabled: If a transaction tries to write to multiple chunks
and a write-write conflict occurs as a chunk is locked by another
transaction, instead of aborting the writes, the transaction will
keep writing to the non-locked chunks and keep attempting to write
to the chunk in conflict. The behavior of writing depends on the
server version:
- Release 200 and lower versions: Upon receiving the data, the data node calculates the partitions involved and requests locks for all partitions from the controller. It writes data to the locked partitions. After completing, it releases the locks on the partitions where the operations were successful. For partitions where lock acquisition fails, the node sleeps for a period before retrying and retries until all partitions have completed the operations. In this scenario, earlier submitted requests may not acquire the lock and experience starvation. This occurs because, during the sleep intervals, locks may be acquired by later submitted requests, preventing the earlier requests from acquiring the locks. As a result, the completion time of these requests is not guaranteed.
-
Release 300 and higher versions: Upon receiving a write request, the data node submits the request to the controller. The controller manages and schedules these requests in a unified queue. If a partition is available for writing, the controller notifies the data node to write. In this process, a single write operation may be divided into multiple transactions. If a failure occurs, it may cause partial data writes.
- Disabled: If transaction A attempts to write to multiple chunks and one of the chunks is locked by transaction B, a write-write conflict occurs, and all writes of transaction A fail.
- Enabled: If a transaction tries to write to multiple chunks
and a write-write conflict occurs as a chunk is locked by another
transaction, instead of aborting the writes, the transaction will
keep writing to the non-locked chunks and keep attempting to write
to the chunk in conflict. The behavior of writing depends on the
server version:
- Select the partitioning column.
The system will recommend the number of partitioning columns and the data types for each partitioning column based on the daily increment, the total data volume, and the number of measurements.
For time-series data: Decide the partitioning level according to the daily increment:
- Single-Level Partitioning: Select a time column as the partitioning column.
- Two-Level Partitioning: Select two partitioning columns. The first is a time column, and the second is a device ID column.
For non-time-series data:Select a device ID column as the partitioning column.
- (Optional) Select the time column.
This option appears when the storage engine is set to TSDB and the data is non-time-series. For non-time-series data, only a device ID column needs to be selected as the partitioning column. If the data contains a temporal column, it can be selected as the time column, which will be used as a sortColumn for query optimization.
-
Select filter columns and the number of distinct values.
Filter columns are frequently used as filtering conditions during queries. It is recommended to arrange these columns by query frequency, with the most commonly used one at the beginning of the list. Number of distinct values determines whether to apply dimensionality reduction. Filter columns will also be used as sortColumns for query optimization.
-
This option appears when the storage engine is set to TSDB. OLAP engine doesn’t support index within a partition.
-
The system will recommend the number of partitioning columns based on the basic information. The data type of filter columns must be enumerable, such as STRING, SYMBOL, CHAR, etc.
-
-
Choose the deduplication strategy.
The keep duplicates option appears when setting storage engine to TSDB. DolphinDB provides three strategies to deal with records with duplicate filter columns and time column values:
-
ALL: keep all records
-
LAST: only keep the last record
-
FIRST: only keep the first record
-
The following steps are the same as described in the basic guide.