异步复制
集群间的异步复制指通过异步方式,将主集群复制到从集群,使主从集群数据一致。集群间的异步复制是集群异地容灾的一个解决方案,通常主集群用于实时的业务查询,而从集群则是作为主集群的一个备份。
与传统集群间的异步复制解决方案相比,DolphinDB 具有以下优势:
-
容错性强。节点宕机不会造成数据丢失,主从集群数据最终会保持一致。
-
运维便捷。提供在线监控函数以及错误修复函数。
支持情况
-
仅支持分布式表,暂不支持内存表和本地磁盘表。
-
对 DDL(Data Definition Language)/DML(Data Manipulation Language) 操作的支持情况请参见下表。
-
不支持权限管理、分级存储以及存储引擎配置修改等非 DDL/DML 操作。
| 支持 | 对应操作类型(operationType) |
|---|---|
| append / tableInsert | APPEND、APPEND_CHUNK_GRANULARITY(APPEND Best Effort) |
| delete | SQL_DELETE |
| update | SQL_UPDATE |
| upsert! | UPSERT |
| dropTable | DROP_TABLE |
| dropPartition | DROP_PARTITION |
| dropDatabase | DROP_DB |
| addRangePartitions | ADD_RANGE_PARTITION |
| addValuePartitions | ADD_VALUE_PARTITION |
| database | CREATE_DOMAIN |
| create, createPartitionedTable, createTable | CREATE_TABLE, CREATE_PARTITIONED_TABLE |
| addColumn | ADD_COLUMN |
| dropColumns | DROP_COLUMN |
| renameTable | RENAME_TABLE |
| truncate | TRUNCATE_TABLE |
| replaceColumn | REPLACE_COLUMN |
| setColumnComment | SET_COLUMN_COMMENT |
| rename! | RENAME_COLUMN |
异步复制流程
(1)启用集群间的异步复制,在配置文件指定相关配置参数。
(2)配置完成后,启动服务器。在主集群数据节点调用 setDatabaseForClusterReplication("dfs://xxx", true) ,开启某个数据库集群间的异步复制(一次调用只启动一个数据库的异步复制)。
(3)主集群开启异步复制后,从集群自动到主集群拉取异步复制任务,然后逐一执行。
(4)若从集群某个数据库的异步复制任务多次失败导致整个异步复制中断,用户可以尝试以下方案解决:
-
在从集群控制节点调用 startClusterReplication 函数尝试重启异步复制。
-
在从集群控制节点调用 getSlaveReplicationStatus 函数,查看从集群异步复制任务的失败原因,解决后再调用 startClusterReplication 函数重启。
-
若无法解决失败任务,可以在从集群控制节点调用 skipClusterReplicationTask 函数跳过该任务,再调用 startClusterReplication 函数重启。
(5)若需要停止所有数据库的异步复制,可以在主集群和从集群的控制节点分别调用 stopClusterReplication 函数。调用后,正在执行的任务会继续进行,但主集群不再将异步复制任务放进发送队列,从集群不再从主集群拉取异步复制任务。
(6)若要停止某个数据库的异步复制,可以调用 setDatabaseForClusterReplication("dfs://xxx", false) 。调用后,正在执行的任务会继续进行,但该数据库不再产生异步复制任务。
异步复制机制
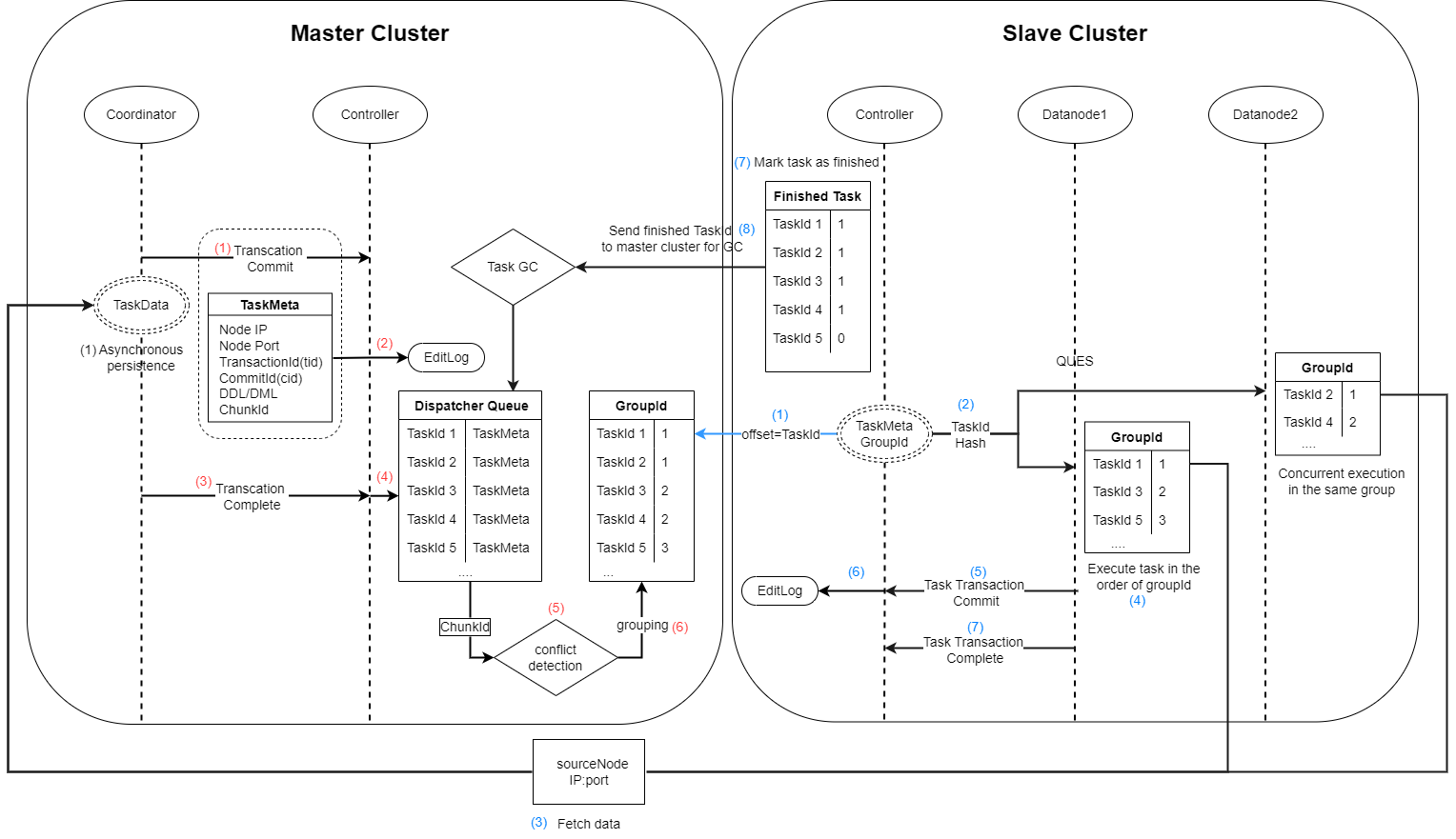
主集群:
(1)事务完成后,根据两阶段提交协议,协调节点发送 “commit” 信号给控制节点,同时将事务的元数据发送给控制节点。若为写事务,则协调节点将该事务的数据持久化到本地。
(2)控制节点收到元数据后,将其写入 DFSMetaLog 文件。
-
DFSMetaLog 文件路径由配置项 dfsMetaDir 决定。
(3)协调节点发送事务 “complete” 信号给控制节点。
(4)控制节点将已经完成的事务的元数据放入发送队列。并根据入列先后标记任务 id。
(5)对发送队列内的任务进行冲突检测。若两个任务写入或修改的 chunk 存在交集,则被认为是冲突的。
(6)根据事务的执行顺序和是否冲突,为其标记组号,系统保证同一组的任务是可以并行执行的。
从集群(记录一个偏移量标记从主集群拉取任务的id):
(1)控制节点根据偏移量从主集群发送队列获取任务。
(2)将元数据通过哈希算法映射到各个从集群的数据节点,映射信息将保存在从集群控制节点的内存中。然后,从最小的组号开始,将元数据发送到对应的数据节点。
(3)若数据节点检测到该任务为写操作,则根据元数据中主集群节点的 ip:port,将任务的数据从主集群拉取到本地。
(4)根据任务对应的查询语句,在当前节点发起事务。
-
多个数据节点间可以并发执行同一组的任务(即不冲突的任务可以并发执行)。若同一组任务中,有任务执行失败,则不再执行下一组任务。
(5)事务完成后,根据两阶段提交协议,数据节点发送 “commit” 信号给控制节点。
(6)控制节点将已经提交的任务 id 写入 EditLog。
(7)数据节点发送 “complete” 信号给控制节点。控制节点收到后,标记该任务为完成状态。并继续执行步骤(2)到(7)。
(8)控制节点将标记为完成状态的任务 id 发送给主集群,主集群发送队列根据该信息进行垃圾回收。
- 步骤(8)和步骤(1)同时进行。
- 若从集群增加了节点,步骤(2)的哈希算法仍基于原节点数进行映射,因此异步复制任务不会被分配到新增加的节点上。