分布式架构
分布式数据库构建在分布式架构的基础上,因此分布式架构是分布式数据库实现的核心设计。DolphinDB 自主研发了基于 shared-nothing 的分布式架构,并进行了全局的优化,实现了数据的分布式存储。DolphinDB 分布式架构涵盖了高可用、在线恢复、分布式事务、异步复制等功能。
DolphinDB 集群底层采用 shared-nothing 架构,同时在物理架构之上引入了一层抽象的逻辑上的文件系统,构建了自研的分布式架构,实现了数据分布式存储。在这一架构中,集群中的各个节点相互独立,拥有自己独立的计算资源和存储资源,不共享中心资源。元数据文件存储在控制节点上,而分区数据按指定逻辑进行划分,存储在不同的数据节点上。这个逻辑上的文件系统有效地组织了各节点的文件和目录服务,形成了一个全局的目录结构,从而屏蔽了各节点具体物理路径的细节。由于逻辑文件系统的存在,用户无需关心数据具体存储在哪个物理节点上。不论用户无论从哪个物理节点进行数据访问,路径都是相同的。
集群模式包含四种角色:控制节点、代理节点、数据节点和计算节点。
-
控制节点:DolphinDB 集群的核心部分,负责收集代理节点和数据节点的心跳,监控每个节点的工作状态,管理分布式文件系统的元数据、分配分区位置,并提供对事务的支持。
-
代理节点:负责执行控制节点发出的启动和关闭数据节点或计算节点的命令。在一个集群中,每台物理服务器有且仅有一个代理节点。
-
数据节点:既可以存储数据,也可以用于数据的查询和计算。每台物理服务器可以配置多个数据节点。
-
计算节点:不存储表数据和元数据,只承担计算相关的职能,负责响应客户端请求并返回结果。适用于数据密集型查询计算任务(如流计算、分布式关联和机器学习等)。每台物理服务器可以配置多个计算节点。
DolphinDB 集群架构如下图所示:
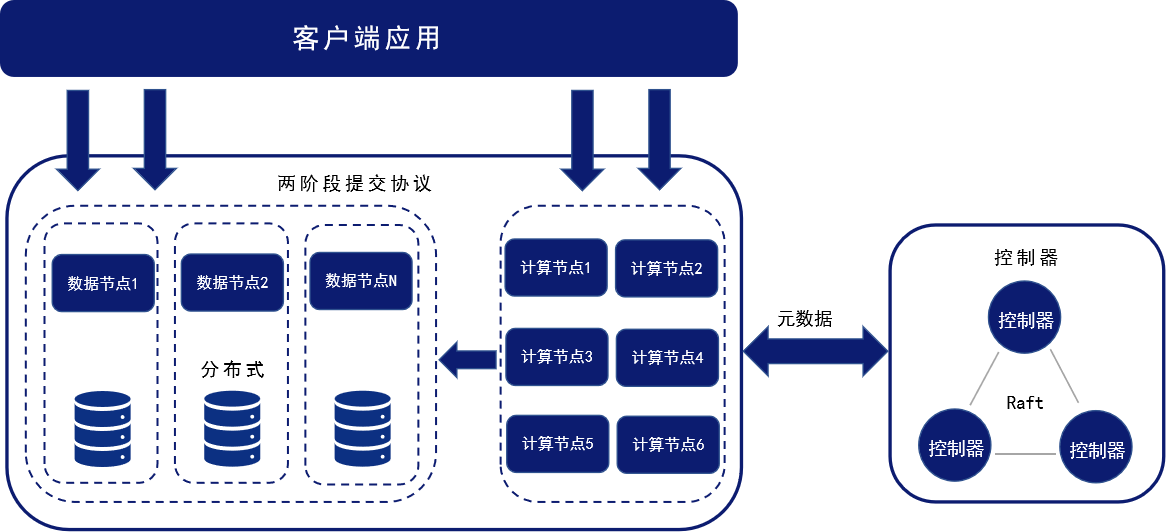
主流的分布式数据库大多采用主从架构,主节点不仅要负责管理元数据和状态同步,还要双机热备来保证高可用,容易成为系统瓶颈,增加系统横向扩展的难度。而 DolphinDB 的分布式架构,依靠全局可见的元数据服务,任何数据节点都可以成为查询请求和数据写入的入口,不存在系统瓶颈点,更容易做到资源的负载均衡。
- 节点对等: 每个节点都是独立的,没有中心化的共享资源。每个节点都有自己的 CPU、内存、硬盘等资源。
- 数据分区和分片:数据以分区方式进行分片,并分布在多台机器上。
-
资源得到充分利用:对数据分割进行了全局优化,实现了数据在各个节点上均匀分布,从而更充分地利用整个集群资源。
-
弹性扩展:控制节点统一管理元数据,提高了容错性和可扩展性。存储逻辑与存储位置分离,可以实现计算和存储的弹性扩展。且扩展节点时,不需要对现有数据进行 resharding 操作,也不需要重启集群,新增的数据会直接保存到新的数据节点中。
-
支持高可用:在节点发生故障时,系统也可以根据存储逻辑,自动找到其他节点上的数据副本,保证服务不断线。
- 支持 TCP 协议: 节点之间、应用驱动与各节点之间的通信基于 TCP 协议,确保了节点之间的连接。且在通信时自动进行数字签名/认证、自动处理数据的序列化/反序列化、等操作。