分布式事务
事务介绍
事务是指对数据库中的数据对象进行的一系列增、删、改等操作。一次事务的所有操作全部纳入一个不可分割的执行单元,该执行单元里的所有操作要么都成功,要么都失败,只要其中任一操作执行失败,整个事务都将回滚。在分布式系统中,各个节点之间在物理上相互独立,通过网络进行沟通和协调。分布式事务是指分布式系统中的事务,一个分布式事务可能涉及到不同节点和分区的操作。同样,分布式事务要去对参与事务的所有节点的操作,要么全部成功,要么全部回滚,不能出现部分提交的情况。时序数据的某些场景,如物联网中的数据采集,丢失一部分数据并不会带来严重的后果。但作为一个分布式数据库,保证各节点上的数据一致性非常关键。DolphinDB 通过两阶段提交(Two-Phase Commit, 2PC)和多版本并发控制机制(MVCC, Multi-Version Concurrency Control)实现分布式事务,能够确保每个事务的原子性(Atomicity)、数据的一致性(Consistency)、读写操作之间的隔离性(Isolation)以及已写入数据的持久性(Durability)。
- 原子性
- 事务是一个原子操作单元,数据写入要么全都执行,要么全都不执行。比如,写入的数据涉及到多个分区,要么全部分区写入成功,要么全部分区写入失败。如果数据有多个副本,要么所有副本写入成功,要么所有副本写入失败。
- 一致性
- DolphinDB 的一个事务可以包含对不同分区的写入操作,事务成功或回滚,每个分区的各个副本的状态总是一致的。在集群模式中,DolphinDB 还能确保某一时刻任何节点上查询得到的数据都是一致的。
- 隔离性
- DolphinDB 通过多版本并发控制机制(MVCC, Multi-Version Concurrency Control)实现事务隔离。每进行一次写入或删除操作,数据库的版本号都会增加。如果事务成功(commit),原先的版本会被覆盖,反之则回滚(roll back)。当用户同时对数据库进行读写操作时,读和写的并发事务会相互隔离。多个事务可以同时对一个分区的不同表进行写入操作。
- 持久性
- 事务完成后,它对数据的操作是永久性的。
基本事务流程
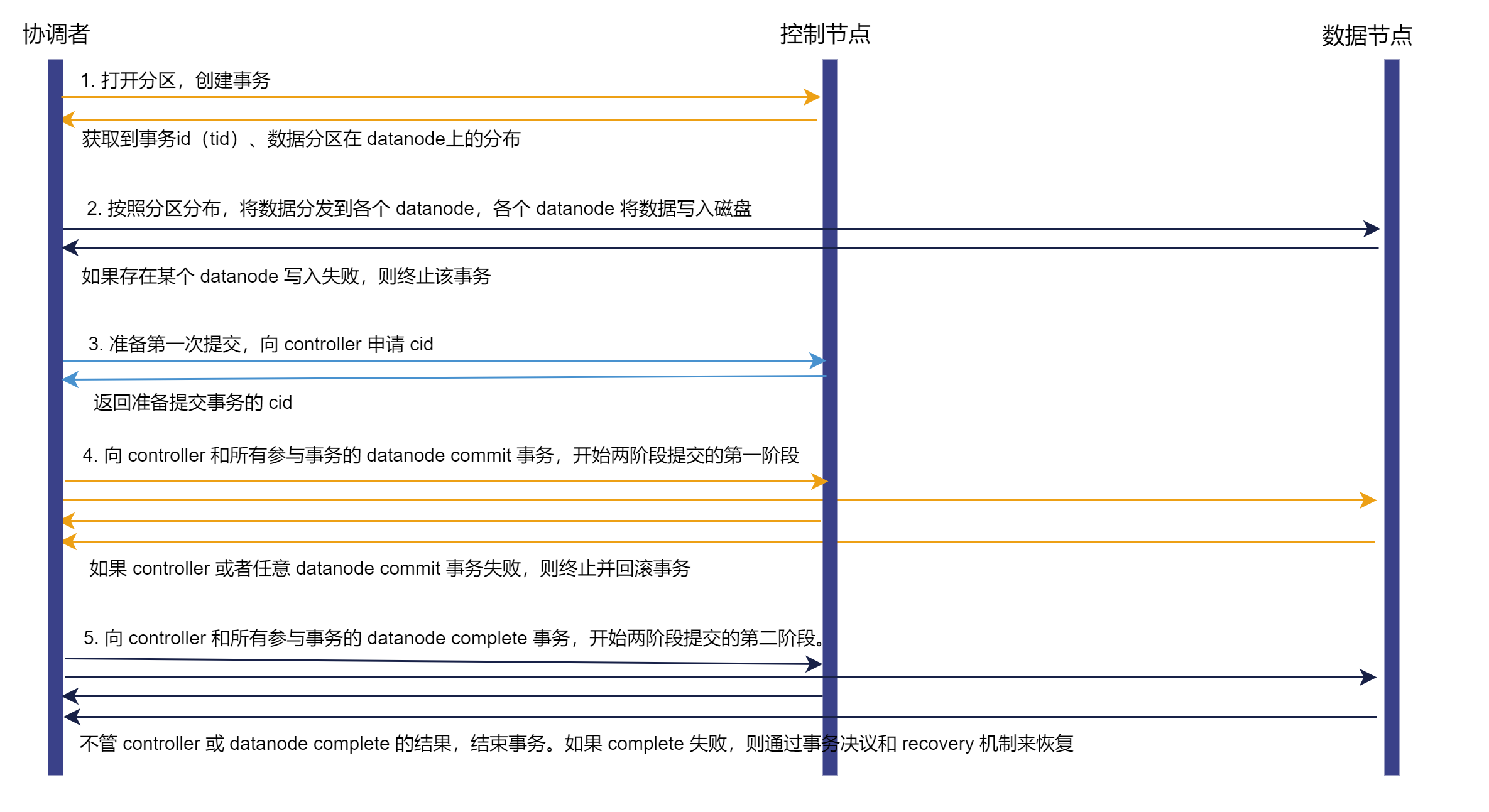
DolphinDB 采用两阶段事务提交机制,每次由事务的发起节点作为协调者(coordinator)推进整个事务的执行流程。
-
协调者提出请求(例如写入数据),创建一个事务,向控制节点申请事务 ID(tid),得到事务所涉及分区在数据节点上的分布情况。
-
协调者将数据分发到相应的数据节点,各个数据节点将数据写入磁盘。如果存在某个数据节点数据写入失败,则终止该事务。
-
协调者准备提交,向控制节点申请 commit id(cid)。
-
协调者向控制节点和所有参与事务的数据节点 commit 事务,开始两阶段提交的第一阶段。如果控制节点或任意数据节点 commit 失败,则终止并回滚事务。
-
协调者向控制节点和所有参与事务的数据节点 complete 事务,开始两阶段提交的第两阶段。不管控制节点或数据节点是否 complete 失败,该事务都结束。如果存在 complete 失败的情况,则通过事务决议和 recovery 机制恢复。
开启 Redo Log 与 Cache Engine 的事务流程
Redo Log 是确保事务持久性的关键机制,即使在系统崩溃时,也能保障数据一致性。缺乏 Redo Log,事务的持久性将会受到影响,因为数据库无法记录事务所做的修改,从而无法在故障或崩溃发生时进行恢复。DolphinDB 利用 Redo Log 和 Cache Engine 来确保事务的持久性并提升写入性能。
DolphinDB 重做日志(Redo Log)与 预写式日志(Write-Ahead Logging,WAL)的概念相似,其核心理念是:只有在描述事务更改的日志记录已经刷新到持久化存储介质之后,才对数据库的数据文件进行修改。这样做可以避免在每次提交事务时都需要将数据页刷新到磁盘上,同时可以保证数据库发生宕机时,可以通过日志来恢复数据,所有尚未应用的更改都可以通过日志记录回放并重做。
Cache Engine 是 DolphinDB 中的一种数据写入缓存机制。数据在写入 Redo Log 的同时写入 Cache Engine。在 Cache Engine 中的数据累积到一个阈值或者达到一定时间后,再由 Cache Engine 一次性异步写入数据文件。在一个事务涉及多个分区且数据量较小的情况下,如果每次事务结束都立即写入磁盘,写入效率将会受到影响。而利用 Cache Engine 先将这些事务缓存起来,待累积到一定数量后,以批量的方式一次性写入磁盘,则可以提供较高的压缩比此外,批量顺序写入也有助于提高IO吞吐量,从而有效提升整体系统性能。
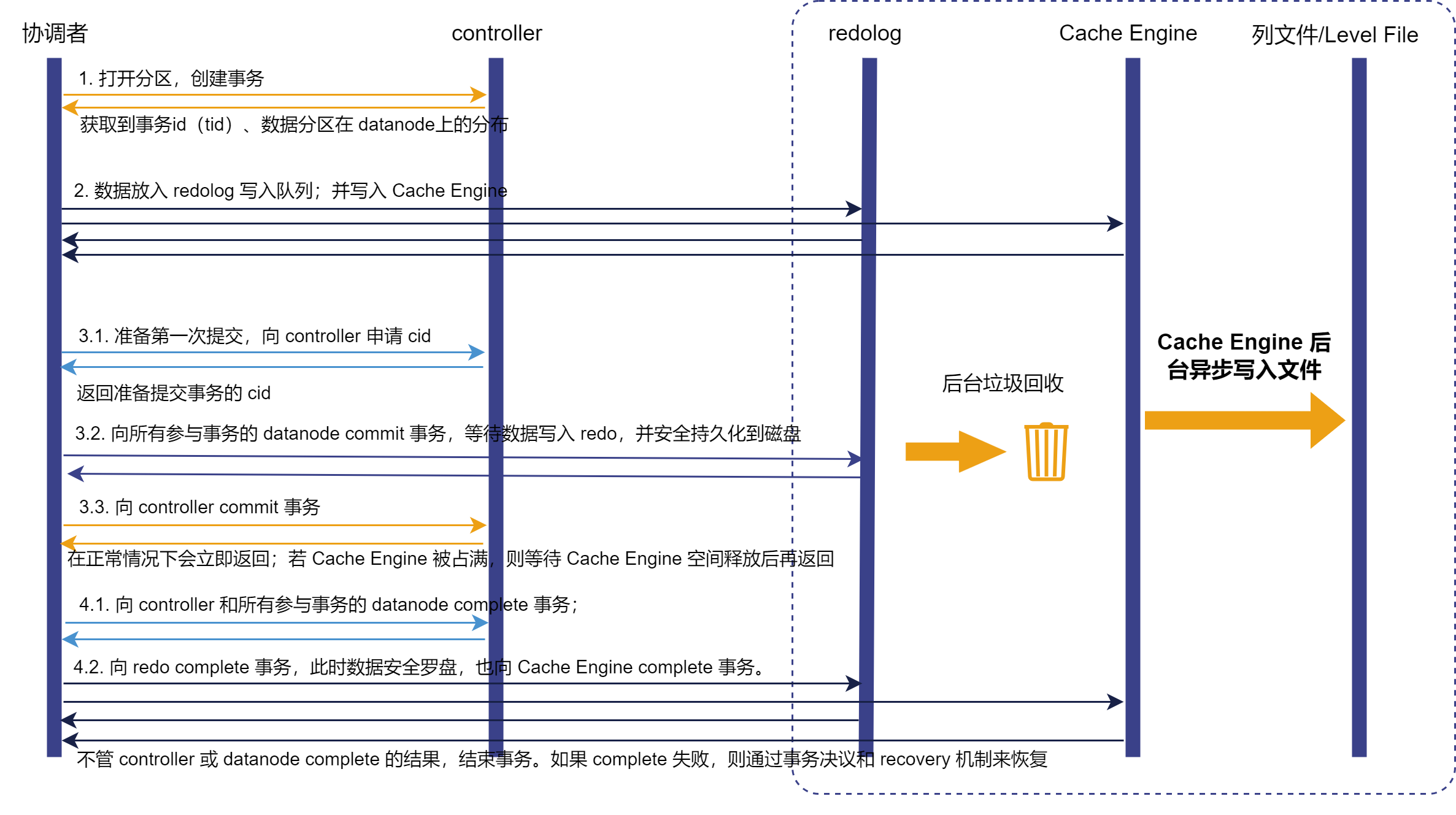
一旦数据写入磁盘,事务完成,系统首先回收该事务的 Cache Engine 缓存,再回收 Redo Log 中的事务。DolphinDB 提供三种 Cache Engine 中事务的回收机制:定期回收、待缓存数据量达到阈值、或通过函数手动清理。同时提供两种 Redo Log的回收机制:定期回收和文件大小达到阈值时回收。
读写隔离
DolphinDB 采用两阶段事务机制,结合多版本并发控制机制(MVCC, Multi-Version Concurrency Control),实现读写快照级别隔离。MVCC 通过保存数据多个事务的数据快照来进行控制,允许同一个数据记录拥有多个不同的版本,记录了一个版本链。每进行一次写入、更新或删除操作,数据的版本号都会增加,从而确保在用户同时对数据库进行读写操作时,读和写的并发事务能够相互隔离。为了有效管理版本,系统会定期回收版本链。
DolphinDB 的分布式事务提供基于 sid(snapshot id)的快照隔离。结合前文介绍的两阶段提交流程,接下来详细说明 DolphinDB 的读写隔离机制:
-
协调者创建事务,向控制节点申请事务 tid。
-
当事务第一次 commit 时,控制节点会生成一个全局递增的 cid,并将其记录在参与事务的所有数据节点上。此时,数据节点会生成一个新的 CHUNK 副本(以”物理表名_tid”命名),并在该副本上进行数据的操作;为了防止 CHUNK 目录无限增长,数据节点最多保留5个旧版本的 CHUNK 目录,并根据设置的保留时长进行定期回收。
-
在完成两阶段提交时,控制节点生成一个全局递增的 sid(snapshot id),并将其记录在版本链上。sid 的主要作用是协助控制节点获取已完成事务中的最大 cid 并将该 cid 返回给协调节点。如果我们不引入 sid,在查询时直接使用 cid,存在一个潜在问题,即可能某个事务已经完成,但仍然有另一个小于该事务 cid 的事务尚未完成。这种情况可能导致在查询时无法查到最新的已完成事务的数据。通过引入全局唯一的 sid,确保了所有已完成的事务都能被查询到。
-
当协调者向控制节点请求查询最新的元数据信息时,控制节点通过当前版本链上的最大 sid,查询到满足小于等于这个 sid 的最新的 cid,并返回给数据节点。对应这个 cid 的 CHUNK 版本即为当前可读的最新版本的 CHUNK 数据。
-
协调者根据获取的 cid 到相应的数据节点上读取此 cid 对应版本的数据。