Monitoring with Prometheus
DolphinDB provides the following 3 ways of performance monitoring:
- With built-in functions:
- getPerf: return performance monitoring measures for the local node. It can be run on each node in a cluster.
- getClusterPerf: return performance monitoring measures for all the nodes in the cluster. It can only be executed on the controller.
- getJobStat: monitor the number of jobs and tasks that are running or in the job queue.
- On the web-based user interface;
- With third-party services, such as Prometheus and Grafana.
This tutorial illustrates how to install and configure Prometheus and its Alertmanager component to monitor the average load of DolphinDB and automatically send alert emails when the specified alerting conditions are met.
Prometheus Metrics
You can monitor DolphinDB database with Prometheus using the following metrics.
| DolphinDB Metric | Description | Units |
|---|---|---|
| cpuUsage | CPU usage | - |
| memoryUsed | memory used by the node | Bytes |
| memoryAlloc | memory allocated to the node | Bytes |
| diskCapacity | disk capacity | Bytes |
| diskFreeSpace | available disk space | Bytes |
| lastMinuteWriteVolume | data written to disk in the last minute | Bytes |
| lastMinuteReadVolume | data read from disk in the last minute | Bytes |
| lastMinuteNetworkRecv | data received in the last minute | Bytes |
| lastMinuteNetworkSend | data sent in the last minute | Bytes |
| diskReadRate | the rate at which data are read from disk | Bytes/Sec |
| diskWriteRate | the rate at which data are written to disk | Bytes/Sec |
| networkSendRate | the rate at which data are sent | Bytes/Sec |
| networkRecvRate | the rate at which data are received | Bytes/Sec |
| cumMsgLatency | cumulative latency of messages | Nanoseconds |
| lastMsgLatency | latency of the last received message | Nanoseconds |
| maxLast10QueryTime | the maximum execution time of the previous 10 finished queries | Nanoseconds |
| medLast10QueryTime | the median execution time of the previous 10 finished queries | Nanoseconds |
| medLast100QueryTime | the median execution time of the previous 100 finished queries | Nanoseconds |
| maxLast100QueryTime | the maximum execution time of the previous 100 finished queries | Nanoseconds |
| maxRunningQueryTime | the maximum elapsed time of the queries that are currently running | Nanoseconds |
| avgLoad | average CPU load | - |
| jobLoad | CPU load of a job | - |
| runningJobs | number of running jobs | - |
| queuedJobs | number of jobs in the queue | - |
| connectionNum | number of connections | - |
You can view the metrics in the following 2 ways:
- With Prometheus Server
- Enter "http://ip:port/metrics" in your browser where "ip:port" is the IP address and port number of the selected node. For example, DolphinDB is deployed on port 8848, you can view the metrics at http://127.0.0.1:8848/metrics .
Download Prometheus
This example uses Ubuntu 16.04 LTS desktop, Prometheus 2.26.0 and Alertmanager 0.21.0.
Download Prometheus and Alertmanager at Download Prometheus and deploy them on the server. You can also refer to the official doc.
There are 3 ways of DolphinDB deployment and you can refer to DolphinDB tutorials for the detailed instructions:
- Deploy directly
- Deploy with Docker-compose
- Deploy with k8s
Install and Configure
Install and Configure Prometheus
Unzip package
The unzipped files are as follows:
demo@zhiyu:~/prometheus-2.26.0.linux-amd64$ ls console_libraries consoles data LICENSE NOTICE prometheus prometheus.yml promtoolConfigure prometheus.yml
Modify the configuration file prometheus.yml:
global: scrape_interval: 15s evaluation_interval: 15s alerting: alertmanagers: - static_configs: - targets: - 127.0.0.1:9093 rule_files: - "./avgLoadMonitor.yml" scrape_configs: - job_name: 'DolphinDB' static_configs: - targets: ['115.239.209.122:8080','115.239.209.122:25667']The
targetsin thealertingsection specifies the port of Alertmanager.The
rule_filesblock specifies the alerting rules. The following section introduces the creation of fileavgLoadMonitor.yml.The last block
scrape_configscontrols what resources Prometheus monitors and thetargetsspecifies theip:portof DolphinDB nodes. This example monitors 2 nodes with IP address115.239.209.122and port numbers 8080 and 25667. You can also add a node in the format of "IP:PORT".Create avgLoadMonitor.yml
The content of file avgLoadMonitor.yml is as follows:
groups: - name: avgLoadMonitor rules: - alert: avgLoadMonitor expr: avgLoad > 0.1 for: 15s labels: severity: 1 team: node annotations: summary: "{{ $labels.instance }} avgLoad larger than 0.1!"In this example, we use metrics
avgLoadand set the alerting rule asavgLoad>0.1.
Install and Configure Alertmanager
Unzip package
The unzipped files are as follows:
demo@zhiyu:~/alertmanager-0.21.0.linux-amd64$ ls alertmanager alertmanager.yml amtool LICENSE NOTICEUsers can specify the alert receivers (such as email, PagerDuty, or OpsGenie) in the configuration file alertmanager.yml. Alerting rules in Prometheus servers send alerts to an Alertmanager specified in the file prometheus.yml. The Alertmanager then manages those alerts and sent out emails to the receivers.
Configure alertmanager.yml
You can refer to Configuration for the Alertmanager configuration and see the example file using email.
Start Prometheus and Alertmanager
Start Prometheus with the following command:
demo@zhiyu:~/prometheus-2.26.0.linux-amd64$ nohup ./prometheus --config.file=prometheus.yml &By default, you can browse to a status page about Prometheus at http://localhost:9090.
Start Alertmanager with the following command:
demo@zhiyu:~/alertmanager-0.21.0.linux-amd64$ nohup ./alertmanager --config.file=alertmanager.yml &Alertmanager will now be reachable at http://localhost:9093. If the alerting rule is triggered in Prometheus, you can view the notifications in the above address. Then the Alertmanager will send alerts to the receivers. In this example, when the average load exceeds 0.1, alerting emails will be sent.
Visualization
With a built-in web interface of Prometheus, users can view alerts, configuration and status conveniently.
For example:
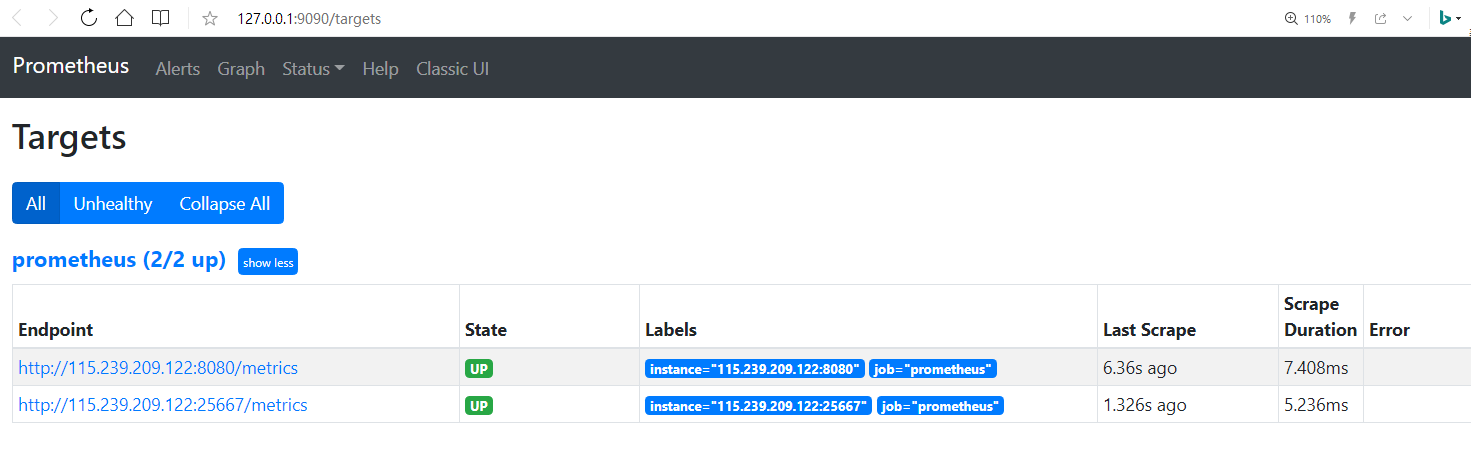
View the target nodes at http://127.0.0.1:9090/targets:
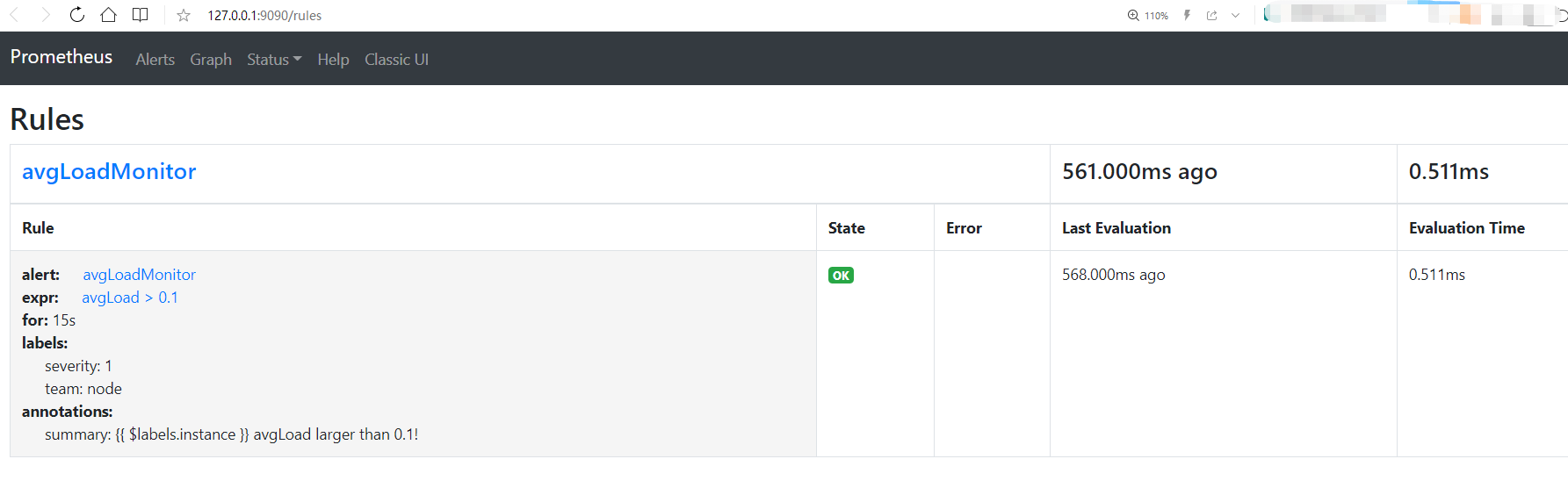
View the alerting rules at http://127.0.0.1:9090/rules:
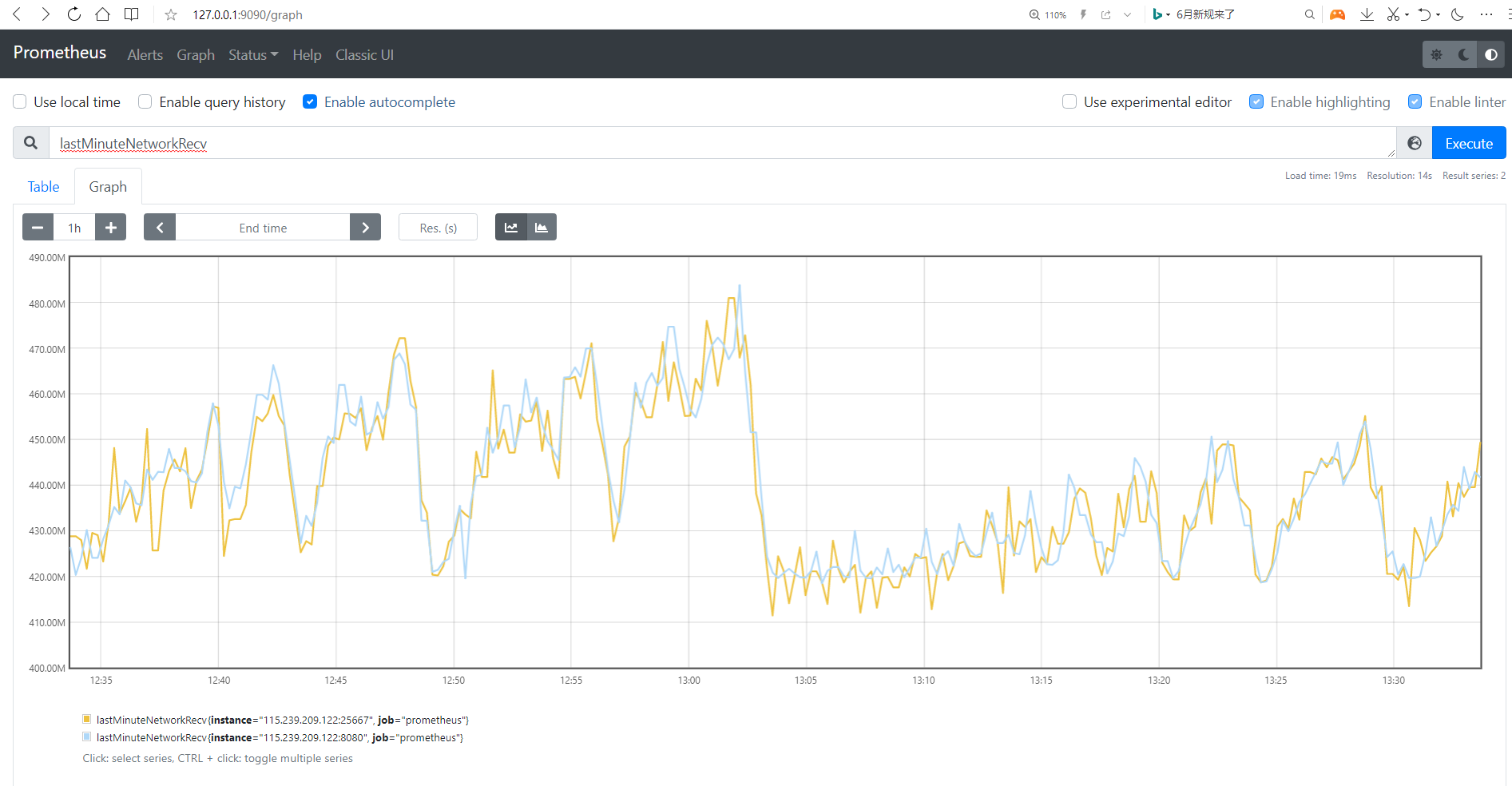
Go to http://127.0.0.1:9090/graph and enter a metric such as lastMinuteNetworkRecv to view the graphical status:
In production environment, users often use Prometheus as the data source for Grafana to view metrics or create dashboards. DolphinDB has implemented dolphindb-datasource plugin and the HTTP data interface to Grafana. See DolphinDB Grafana DataSource Plugin for more information.