Node Crashes
When working with DolphinDB, you may encounter situations where a node crashes unexpectedly. This can manifest as a "Connection refused" error message on the client side, or DolphinDB missing from the system's running processes. This article provides a step-by-step guide to diagnose the possible causes of such crashes and provides the tools and techniques you can use to tackle them.
Checking Node Logs for Diagnostic Information
DolphinDB logs all node activities into log files, providing insights into the system's behavior and identifying potential causes for the crashes.
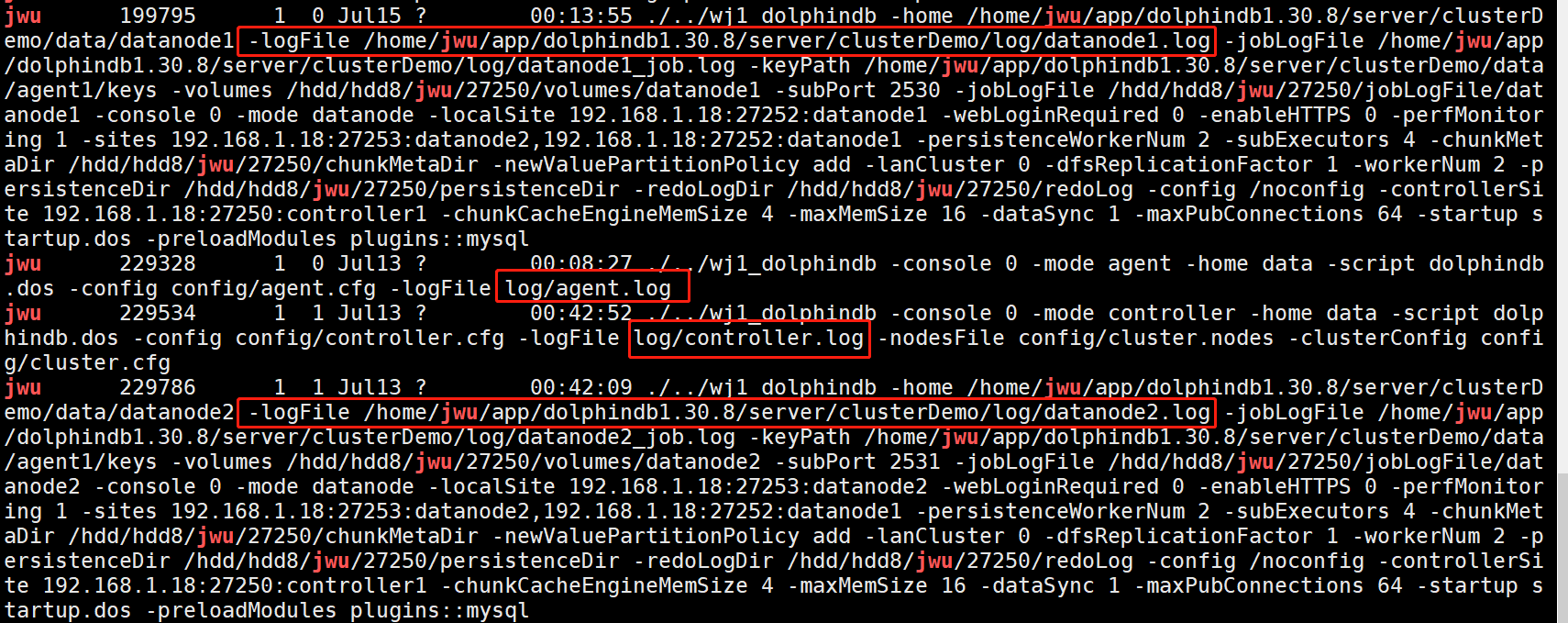
Locating Log Files
By default, the log of a data node is named as dolphindb.log in the server
diectory in standalone mode, or under the server/log directory in a
cluster mode. The storage path can be modified with the logFile
configuration parameter. If there are multiple nodes running in the cluster, use
the ps command to check the log path of each node.
Common Crash Causes
Several non-DolphinDB system issues can lead to node crashes:
- Manual shutdown through the Web interface or
stopDataNodefunction. - Process termination by the operating system's
killcommand. - License expiration
For example, you can use the following command to search the log of node datanode1:
less datanode1.log | grep "MainServer shutdown"If this message MainServer shutdown appears around the time of
the crash, the process could have been shut down.

Analyzing Log Files
(1) Manually Stopped via Web Interface or
stopDataNode
To check if the node was manually stopped via the web interface or using the
stopDataNode function, search the controller log for the
message has gone offline:
less controller.log | grep "has gone offline"
(2) Killed by Operating System
To check if the node process was killed by the operating system, search for the
Received signal message in the node log:
less datanode1.log | grep "Received signal"
(3) License Expiration
To determine if the node shutdown was caused by an expired license, search for the following message in the log:
The license has expired
To address this issue, you can update the license to avoid future disruptions.
Checking Operating System Logs for OOM Events
The Linux kernel employs the Out Of Memory (OOM) killer to prevent system crashes by terminating processes that consume excessive memory.
Inspecting System Logs
To check if the OOM Killer has terminated the DolphinDB process, use the following command to inspect the system logs:
dmesg -T | grep dolphindbAddressing OOM Terminations
If the message Out of memory: Kill process is shown, it
indicates that DolphinDB exceeded the available memory, causing the system to
kill the process.

To address this problem, set the maxMemSize parameter in the configuration files to limit the memory usage of the node. For example, if the machine has 16 GB of memory and is running one node, set maxMemSize to approximately 12 GB.
Identifying Segmentation Faults
If the dmesg command reveals a "segfault" message, it indicates
that a segmentation fault has occurred. This happens when the DolphinDB process
attempts to access memory that has not been allocated to it.

Common causes of segmentation faults include:
- Accessing system data areas (often by operating on a pointer at address 0x00).
- Memory access out of bounds (e.g., array index out of range, variable type inconsistency).
- Stack overflow (the default stack size in Linux is 8192 KB, verifiable with
the
ulimit -scommand).
Configuring Core Files
Core dump files are crucial for diagnosing and debugging program crashes. They contain a snapshot of the program's memory state and other vital information at the time of termination.
Enabling Core Dump
To check if core dumps are currently enabled, use the following command:
ulimit -cA result of 0 indicates that core dumps are disabled, while any other number or "unlimited" means they are enabled. To enable core dumps with unlimited size, run:
ulimit -c unlimitedNote: This setting only applies to the current session. For persistent configuration, use one of the following methods:
-
Add the following line to /etc/profile and then reload the server:
ulimit -S -c unlimited >/dev/null 2>&1Alternatively, use
source/etc/profileto make the configuration take effect immediately without restarting the server. To set it for specific user only, modify the ~/.bashrc or ~/.bash_profile file for the user. -
Add the following two lines to /etc/security/limits.conf to enable core dumps for all users.
* soft core unlimited * hard core unlimited
Note: After enabling the core function, you need to restart the agent first, followed by the data nodes.
Setting Core Dump File Path
A core dump file has a default file name in the format of core.pid, where pid denotes the process ID of the program that causes the segmentation faults. The default file path is the program directory.
/proc/sys/kernel/core_uses_pid specifies whether to add pid as
the filename suffix to the generated core file. Use the following command to
change the setting:
echo "1" > /proc/sys/kernel/core_uses_pid/proc/sys/kernel/core_pattern specifies the file path and file
name format.
This example saves core files to /corefile with the format "core-command name-pid-timestamp".
echo /corefile/core-%e-%p-%t > /proc/sys/kernel/core_pattern Parameter Reference:
- %p: process ID
- %u: current user ID
- %g: current group ID
- %s: signal that caused the core dump
- %t: time of core dump (UNIX timestamp)
- %h: hostname
- %e: executable filename
Debugging Core Files
To debug core files, use the GNU Debugger (GDB). Install GDB with:
yum install gdbDebug the core file:
gdb [exec file] [core file]Use the bt command to display the stack trace for further
analysis.
By following these steps, you can effectively configure and utilize core dumps to diagnose DolphinDB crashes and identify the root causes of issues.
Preventing Node Crashes
Implementing preventive measures can significantly reduce the occurrence of node crashes in DolphinDB. Here are some best practices:
Avoiding Infinite Recursion
When writing recursive functions, always include a termination condition to prevent stack overflow errors. For example, avoid dangerous recursive patterns such as:
def danger(x) {
return danger(x) + 1
}
danger(1)Monitoring and Optimizing Memory Usage
High memory usage can trigger OOM events. Monitor and optimize memory usage by appropriately configuring write caches for DFS databases and message queues for streaming.
Avoiding Concurrent Writes to In-Memory Tables
Avoid concurrent writes to in-memory tables. For example, the following script creates a partitioned in-memory table:
t=table(1:0,`id`val,[INT,INT])
db=database("",RANGE,1 101 201 301)
pt=db.createPartitionedTable(t,`pt,`id)Running two concurrent write jobs on the same partitioned table can cause a crash:
def writeData(mutable t,id,batchSize,n){
for(i in 1..n){
idv=take(id,batchSize)
valv=rand(100,batchSize)
tmp=table(idv,valv)
t.append!(tmp)
}
}
job1=submitJob("write1","",writeData,pt,1..300,1000,1000)
job2=submitJob("write2","",writeData,pt,1..300,1000,1000)This generates a core dump as follows:

Implementing Proper Exception Handling in Custom Plugins
Custom plugins that fail to handle exceptions properly might crash the server. Ensure proper error-handling mechanisms are in place to avoid this. Detailed instructions can be found at Plugin Development Tutorial.
Conclusion
Node crashes in DolphinDB can occur for various reasons, ranging from system resource constraints to coding practices. This guide outlines the steps to diagnose and resolve these issues:
- Examine DolphinDB logs to identify intentional shutdowns, license expirations, or process terminations.
- Check system logs for OOM events and segmentation faults.
- Configure and analyze core dumps for detailed debugging.
- Implement preventive measures, including proper script design, memory management, and exception handling.
For complex issues, please retain all relevent logs and core files, document the steps taken to reproduce the issue, and contact DolphinDB support for further assistance.