interval
Syntax
interval(X, duration, fill, [step], [explicitOffset=false], [closed],
[label], [origin])
Details
In SQL queries, group data into continuous intervals with the length of duration. For intervals without any data, fill the results using the interpolation method specified by fill. This function must be used in a SQL group by clause.
Note: Temporal data types in "where" conditions are automatically converted.
Parameters
X is a vector of integral or temporal type.
duration is of integral or duration type. The following time units are supported (case-sensitive): w, d, H, m, s, ms, us, ns, and trading calendar identifier consisting of four capital letters (the trading calendar file must be stored in marketHolidayDir). As time unit y is not supported, to group X by year, convert the data format of X with function year.
fill indicates how to fill the missing values of the result. It can take the value of "prev", "post", "linear", "null", a specific numeric value and "none".
- "prev": the previous value
- "post": the next value
- "linear": linear interpolation. For non-numerical data, linear interpolation cannot be used and the "prev" method will be used instead.
- "null": null value
- a specific numeric value.
- "none": do not interpolate
step (optional) is of integral or duration type. It's an optional parameter indicating the step size of the sliding window. It must be a number which can divide the duration. This parameter allows us to specify a sliding interval that is smaller than duration. The default value is the same as duration, which means the calculation window slides by the length of duration.
Note:
- If stepis specified, the following aggregation calculations are not
supported:
atImax,atImin,difference,imax,imin,lastNot,mode,percentile. - If the value of step differs from duration, user-defined aggregation functions are not supported for distributed queries.
explicitOffset (optional) is an optional BOOLEAN. When explicitOffset = true, the first interpolation window starts at the starting point specified by the SQL where clause. When explicitOffset = false (default), the first interpolation window starts at the nearest point that is divisible by step before the starting point specified by the SQL where clause.
closed (optional) is a string indicating which boundary of the interval is closed. It can be specified as 'left' (default) or 'right'.
label (optional) is a string indicating which boundary is used to label the interval with. It can be specified as 'left' (default) or 'right'.
origin (optional) is a string or a scalar of the same temporal type as X, indicating the timestamp when the intervals start. When origin is a string, it can be specified as:
- 'epoch': 1970-01-01;
- 'start': the first value of the timeseries;
- 'start_day' (default): 00:00 of the first day of the timeseries;
- 'end': the last value of the timeseries;
- 'end_day': 24:00 of the last day of the timeseries.
Note that origin is specified only when explicitOffset = false.
Note: As of version 2.00.2, the range parameter has been removed.
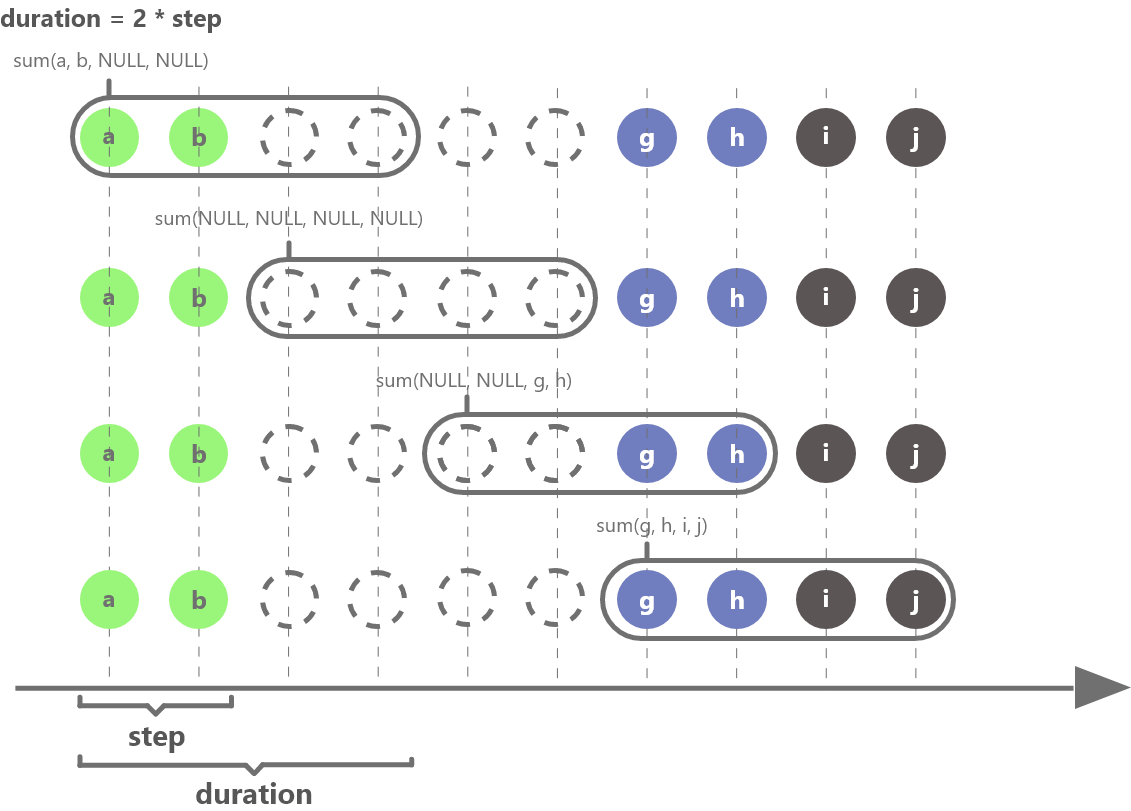
The following figure uses duration = 2 * step as an example to further explain how the interpolation window slides and applies calculations. The windows whose results are null are filled using the method specified by fill.
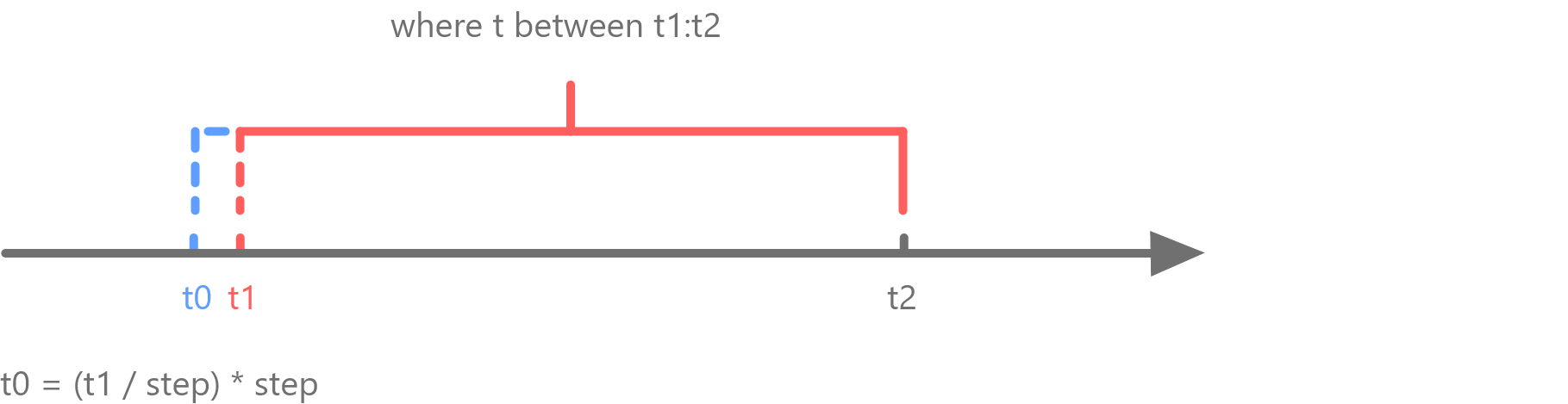
The figure below explains how the starting interpolation window is determined based on explicitOffset. In this example, t1 is the starting point specified by the where condition, t0 is the nearest point before t1 that is divisible by step. When explicitOffset = true, the first interpolation window starts at t1. When explicitOffset = false, the first interpolation window starts at t0.
Examples
Fill with the previous value:
timestampv = temporalAdd(2012.01.01T00:00:00.000, 0..11 join 15..20 , "s")
a1v = [3,2.5,1.7,1.1,1.8,2.1,1.1,1.4,1.9,2.4,2.9,2.6,1.1,2.7,1.1,2.9,1.9,1.7]
t = table(timestampv as timestamp, a1v as a1)
select max(a1) from t group by interval(timestamp, 3s, "prev")| interval_timestamp | max_a1 |
|---|---|
| 2012.01.01T00:00:00.000 | 3 |
| 2012.01.01T00:00:03.000 | 2.1 |
| 2012.01.01T00:00:06.000 | 1.9 |
| 2012.01.01T00:00:09.000 | 2.9 |
| 2012.01.01T00:00:12.000 | 2.9 |
| 2012.01.01T00:00:15.000 | 2.7 |
| 2012.01.01T00:00:18.000 | 2.9 |
fill with a specific number:
select max(a1) from t group by interval(timestamp, 3s, 100)| interval_timestamp | max_a1 |
|---|---|
| 2012.01.01T00:00:00.000 | 3 |
| 2012.01.01T00:00:03.000 | 2.1 |
| 2012.01.01T00:00:06.000 | 1.9 |
| 2012.01.01T00:00:09.000 | 2.9 |
| 2012.01.01T00:00:12.000 | 100 |
| 2012.01.01T00:00:15.000 | 2.7 |
| 2012.01.01T00:00:18.000 | 2.9 |
In the following example, to group data by every 2 years, convert X with the
year function, and specify duration as an integer in
interval.
t=table([2016.10.12T00:00:00.500,2017.10.12T00:00:03.000,2018.10.12T00:00:03.000,2019.10.12T00:00:08.000,2020.10.12T00:00:08.000,2021.10.12T00:00:08.000] as time, [7,9,NULL,NULL,8,6] as price)
select max(price) from t group by interval(X=year(time), duration=2, fill="prev")| interval | max_price |
|---|---|
| 2016 | 9 |
| 2018 | 9 |
| 2020 | 8 |
The following example demonstrates how the starting point of the first window is determined based on the value of explicitOffset.
symbol = `A`A`A`A`A`A`A`A`B`B`B`B
price= [29.55,29.74,29.51,29.54,29.79,29.81,29.50,29.56,29.41,29.49,29.83,29.76]
volume = [2200,1900,2100,3200,8800,5800,4300,9300,7900,9100,7300,6500]
tradeTime = [09:33:56,09:33:59,09:34:08,09:34:16,09:34:51,09:34:59,09:35:47,09:35:26,09:35:36,09:36:26,09:37:12,10:00:00]
t = table(tradeTime, symbol, volume, price)
//When explicitOffset is set to true, the first interpolation window starts at 09:33:50 specified by where clause.
select max(price) as max_price, min(price) as min_price from t where tradeTime between 09:33:50:09:35:00 group by symbol, interval(X=tradeTime, duration=30, fill="post", explicitOffset=true) as tradeTime| symbol | tradeTime | max_price | min_price |
|---|---|---|---|
| A | 09:33:50 | 29.74 | 29.51 |
| A | 09:34:20 | 29.81 | 29.79 |
| A | 09:34:50 | 29.81 | 29.79 |
When explicitOffset is set to false, the starting point of the first window should be the first value before 09:33:50 (the starting point of the time range specified by the where condition) that is divisible by step. Therefore, the starting point of the first window should be second(09:33:50/30*30), which is 09:33:30.
select max(price) as max_price, min(price) as min_price from t where tradeTime between 09:33:50:09:35:00 group by symbol, interval(X=tradeTime, duration=30,fill="prev",explicitOffset=false) as tradeTime| symbol | tradeTime | max_price | min_price |
|---|---|---|---|
| A | 09:33:30 | 29.74 | 29.55 |
| A | 09:34:00 | 29.54 | 29.51 |
| A | 09:34:30 | 29.81 | 29.79 |
| A | 09:35:00 | 29.81 | 29.79 |
The following example sets step to 20s and duration to 60s. The calculation is performed by sliding forward every 20s.
select max(price) as max_price, min(price) as min_price from t where tradeTime between 09:33:50:09:35:00 group by symbol, interval(X=tradeTime, duration=60, fill=0, step=20, explicitOffset=false) as tradeTime| symbol | tradeTime | max_price | min_price |
|---|---|---|---|
| A | 09:33:40 | 29.74 | 29.51 |
| A | 09:34:00 | 29.81 | 29.51 |
| A | 09:34:20 | 29.81 | 29.79 |
| A | 09:34:40 | 29.81 | 29.79 |
| A | 09:35:00 | 0.00 | 0.00 |
The following example groups data by every 2 trading days.
// create a trading calendar named "ADDA" with holidays 2024.01.02 and 2024.01.03.
holiday = [2024.01.02, 2024.01.03]
addMarketHoliday("ADDA", holiday)
// create a table
n = 6
dates=[2023.12.30, 2024.01.02, 2024.01.03, 2024.01.05, 2024.01.07, 2024.01.09]
name = take(`A`B`S`C`F, n)
a1 = take(double(1..3),n)
t=table(dates as date, name as name, a1 as a1)
//calculate the maximum value of "a1" every two trading days of ADDA.
select max(a1) from t group by interval(X=date, duration=2ADDA, fill="null", label="right", origin="start")Set the window limit to retrieve the top N records of each group. For example, to get the top 2 records of each group:
n = 20
id = take(`A`B,n)
ts = (2026.04.01T00:00:00.000+1..10*60000).join(2026.04.02T00:00:00.000+1..10*60000)
val = 1..n
t = table(id, ts, val)
select max(val) from t
where date(ts) = 2026.04.01
group by id, interval(ts, 3m, "prev")
window limit 2|
id |
interval_ts |
max_val |
|---|---|---|
| A | 2026.04.01 00:00:00.000 | 1 |
| A | 2026.04.01 00:03:00.000 | 5 |
| B | 2026.04.01 00:00:00.000 | 2 |
| B | 2026.04.01 00:03:00.000 | 4 |
Set an offset to skip the first n rows of each group. For example, to skip the first 1 record of each group and get the next 2 records:
select max(val) from t
where date(ts) = 2026.04.01
group by id, interval(ts, 3m, "prev")
window limit 1,2|
id |
interval_ts |
max_val |
|---|---|---|
| A | 2026.04.01 00:03:00.000 | 5 |
| A | 2026.04.01 00:06:00.000 | 7 |
| B | 2026.04.01 00:03:00.000 | 4 |
| B | 2026.04.01 00:06:00.000 | 8 |