Distributed Database Overview
1. Benefits of Distributed Databases
Partitioned databases can significantly reduce latency and improve throughput.
- Partitioning makes large tables more manageable by enabling users to access subsets of data quickly and efficiently, while maintaining the integrity of a data collection.
- Partitioning helps the system utilize all cluster resources. Data can be partitioned to multiple nodes and a task can be divided into multiple subtasks on these nodes. With distributed computing, these subtasks can be executed simultaneously to improve performance.
2. The Differences Between DolphinDB and MPP Databases Regarding Partitions
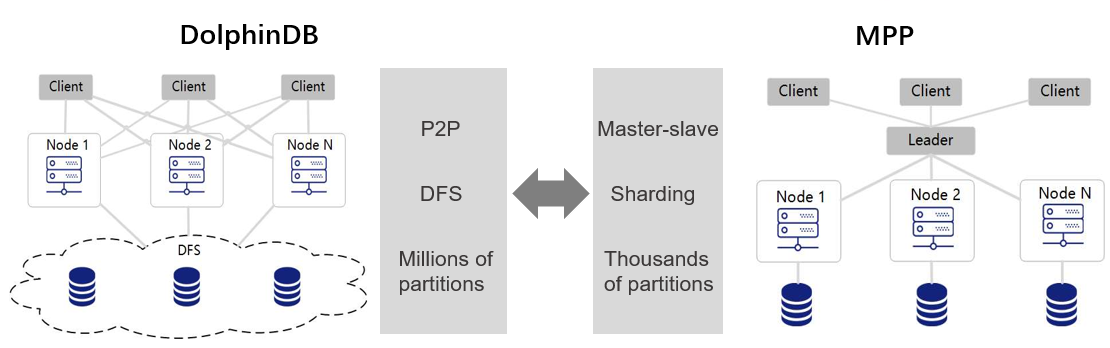
MPP (Massive Parallel Processing) databases are widely adopted in popular systems such as Greenplum, Amazon Reshift, etc. In MPP a leader node connects to all client applications. DolphinDB adolpts a peer-to-peer structure in database and doesn't have a leader node. Each client application can connect to any compute node. Therefore DolphinDB doesn't have performance bottlenecks at the leader node.
MPP databases usually split data across nodes with hashed sharding first (horizontal partitioning), then within each node conduct further partitioning (vertical partitioning). In DolphinDB, the partitioning logic and partition storage are independent of each other. The distributed file system (DFS) determines the storage locations of the partitions. Partitioning storage is optimized across the entire cluster. Compared with MPP databases, DolphinDB provides more fine-grained partitions. Data is more evenly distributed across partitions to better utilize cluster resources.
As the distributed file system provides excellent partition management, fault tolerance, replica management and transaction management, a single table in DolphinDB can support millions of partitions. DolphinDB supports data storage and fast queries on datasets up to PBs. With DFS, database storage is independent of data nodes, making it extremely convenient to scale out the clusters.
3. Partition Domains
DolphinDB supports range, hash, value, list and composite partitions.
- Range partitions use ranges to form partitions. Each range is defined by 2 adjacent elements of a partition scheme vector. It is the most commonly used partition type.
- Hash partitions use a hash function on a partitioning column. Hash partition is a convenient way to generate a given number of partitions.
- In a value domain, each element of the partition scheme vector corresponds to a partition.
- A list domain partitions data according to a list. It is more flexible than a range domain.
- The composite domain is suitable for situations where multiple columns are frequently used in SQL where or group by clauses on large tables. A composite domain can have 2 or 3 partitioning columns. Each column can be of range, hash, value or list domain. For example, we can use a value domain on trading days, and a range domain on stock symbols. The order of the partitioning columns is irrelevant.
When we create a new distributed database, we need to specify parameters "partitionType" and "partitionScheme". When we reopen an existing distributed database, we only need to specify "directory". We cannot overwrite an existing distributed database with a different "partitionType" or "partitionScheme".
When we use aggregate functions on a partitioned table, we can achieve optimal performance if group by columns are also the partitioning columns.
To call the function database, you must log in as an administrator, or a user with granted privilege DB_OWNER. For example, you can log in using the default admin account:
login(userId=`admin, password=`123456)The following examples are executed on local drives with an admin already logged in on Windows. To run in Linux servers or DFS clusters, just change the directory of the databases accordingly.
3.1. RANGE Domain
In a range domain (RANGE), partitions are determined by ranges whose boundaries are two adjacent elements of the partition scheme vector. The starting value is inclusive and the ending value is exclusive.
In the example below, database db has 2 partitions: [0,5) and [5,10). Table t is saved as a partitioned table pt with the partitioning column of ID in database db.
n=1000000
ID=rand(10, n)
x=rand(1.0, n)
t=table(ID, x)
db=database("dfs://rangedb", RANGE, 0 5 10)
pt = db.createPartitionedTable(t, `pt, `ID)
pt.append!(t);
pt=loadTable(db,`pt)
select count(x) from pt;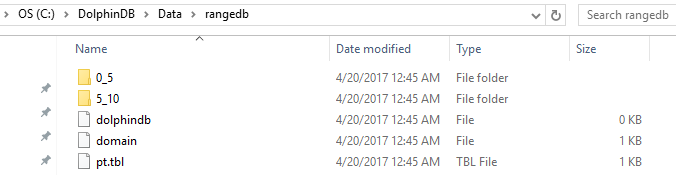
The partition scheme of a range domain can be appended after it is created. Please check function addRangePartitions in user manual for details.
3.2. HASH Domain
In a hash domain (HASH), partitions are determined by a hash function on the partitioning column. Hash partition is a convenient way to generate a given number of partitions. However, there might be significant differences between the partition sizes if the distribution of the partitioning column values is skewed. To locate observations on a continuous range in the partitioning column, it is more efficient to use range partitions or value partitions than hash partitions.
In the example below, database db has 2 partitions. Table t is saved as a partitioned table pt with the partitioning column of ID in database db.
n=1000000
ID=rand(10, n)
x=rand(1.0, n)
t=table(ID, x)
db=database("dfs://hashdb", HASH, [INT, 2])
pt = db.createPartitionedTable(t, `pt, `ID)
pt.append!(t)
pt=loadTable(db,`pt)
select count(x) from pt3.3. VALUE Domain
In a value domain (VALUE), each element of the partition scheme vector corresponds to a partition.
n=1000000
month=take(2000.01M..2016.12M, n)
x=rand(1.0, n)
t=table(month, x)
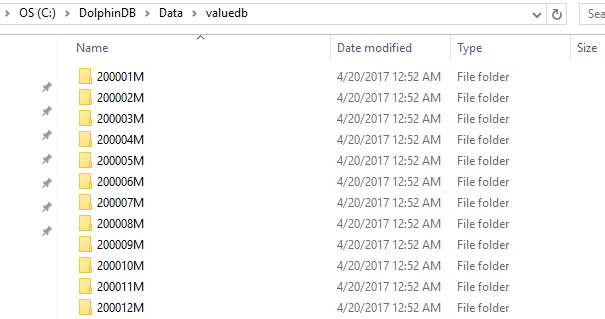
db=database("dfs://valuedb", VALUE, 2000.01M..2016.12M)
pt = db.createPartitionedTable(t, `pt, `month)
pt.append!(t)
pt=loadTable(db,`pt)
select count(x) from pt;The example above defines a database db with 204 partitions. Each of these partitions is a month between January 2000 and December 2016. In database db, table t is saved as a partitioned table pt with the partitioning column of month.
The partition scheme of a value domain can be appended with new values after it is created. Please check function addValuePartitions in user manual for details.
3.4. LIST Domain
In a list domain, each element of a vector represents a partition. The difference between a list domain and a value domain is that all the elements in a value domain partition scheme are scalars, whereas each element in a list domain partition scheme may be a vector.
n=1000000
ticker = rand(`MSFT`GOOG`FB`ORCL`IBM,n);
x=rand(1.0, n)
t=table(ticker, x)
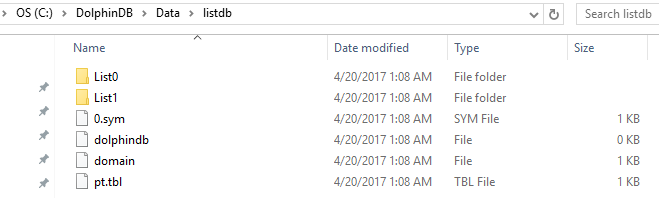
db=database("dfs://listdb", LIST, [`IBM`ORCL`MSFT, `GOOG`FB])
pt = db.createPartitionedTable(t, `pt, `ticker)
pt.append!(t)
pt=loadTable(db,`pt)
select count(x) from pt;The database above has 2 partitions. The first partition contains 3 tickers and the second contains 2 tickers.
3.5. COMPO Domain
A composite domain (COMPO) can have 2 or 3 partitioning columns. Each partitioning column can be of range, value, or list domain. The order of the partitioning columns is irrelevant.
n=1000000
ID=rand(100, n)
dates=2017.08.07..2017.08.11
date=rand(dates, n)
x=rand(10.0, n)
t=table(ID, date, x)
dbDate = database(, VALUE, 2017.08.07..2017.08.11)
dbID=database(, RANGE, 0 50 100)
db = database("dfs://compoDB", COMPO, [dbDate, dbID])
pt = db.createPartitionedTable(t, `pt, `date`ID)
pt.append!(t)
pt=loadTable(db,`pt)
select count(x) from pt;The value domain has 5 partitions:
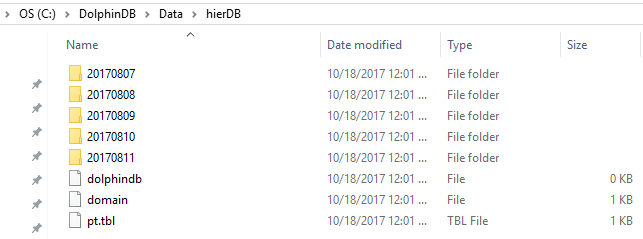
Click on a date partition, we can see the range domain has 2 partitions:

If one of the partitioning columns of a composite domain is of value domain, it can be appended with new values after it is created. Please check function addValuePartitions in user manual for details.
4. Partition Guidelines
A good partition scheme can reduce latency and improve query performance and throughput. In this section we discuss the issues to consider in determining the optimal partitioning scheme.
4.1. Select Appropriate Partitioning Columns
In DolphinDB, the data types that can be used for partitioning columns include integers (CHAR, SHORT, INT), temporal (DATE, MONTH, TIME, SECOND, MINUTE, DATETIME, DATEHOUR), STRING and SYMBOL. The HASH domain also supports LONG, UUID, IPADDR and INT128 types. Although a partitioning column can be of STRING type, for optimal performance, we recommend converting a STRING type column into SYMBOL type to be used as a partitioning column.
FLOAT and DOUBLE types cannot be used as a partitioning column.
db=database("dfs://rangedb1", RANGE, 0.0 5.0 10.0);
The data type DOUBLE can't be used for a partition column.Although DolphinDB supports TIME, SECOND and DATETIME for partitioning columns, please avoid using them for value partitions. Otherwise each partition may be too small. It is very time consuming to create and query millions of small partitions.
The partitioning columns should be relevant in most database transactions, especially database updates. For example, many tasks on financial databases involve stock symbols and dates. Therefore stock symbols and dates are natural candidates as partitioning columns. As will be discussed in section Transactions, DolphinDB doesn't allow multiple threads or processes to write to the same partition simultaneously when updating the database. Considering we may need to update data of a date or of a stock, if we use other partitioning columns such as trading hour, multiple writers may write to the same partition simultaneously and cause problems.
A partitioning column is equivalent to a physical index on a table. If a query uses a partition column in where conditions, the system can quickly load the target data instead of scanning the entire table. Therefore, partitioning columns should be the columns that are frequently used in where conditions for optimal performance.
4.2. Partition Size Should Not Be Too Large
The columns in a partition are stored as separate files on disk after compression. When a query reads the partition, the system loads the necessary columns into memory after decompression. Too large partitions may slow down the system, as they may cause insufficient memory with multiple threads running in parallel, or they may make the system swap data between disk and memory too frequently. As a rule of thumb, assume the available memory of a data node is S and the number of workers is W, then it is recommended that a partition is less than S/8W in memory after decompression,For example, with available memory of 32GB and 8 workers, a single partition should be smaller than 32GB/8/8=512MB.
The number of subtasks of a query is the same as the number of partitions involved. Therefore if partitions are too large, the system cannot fully take advantage of distributed computing on multiple partitions.
DolphinDB is designed as an OLAP database system. It supports appending data to tables, but does not support deleting or modifying individual rows. To modify certain rows, we need to overwrite entire partitions containing these rows. If the partitions are too large, it would be too slow to modify data. When we copy or move selected data between nodes, entire partitions with the selected data are copied or moved. If the partitions are too large, it would be too slow to copy or move data.
Considering all the factors mentioned above, we recommend the size of a partition does not exceed 1GB before compression. This restriction can be adjusted based on the specific situations. For example, when we work with a table with hundreds of columns and only a small subset of columns are actually used, we can relax the upper limit of the partition size range.
To reduce partitions sizes, we can (1) use composite partitions (COMPO); (2) increase the number of partitions; (3) use value partitions instead of range partitions.
4.3. Partition Size Should Not Be Too Small
If partition size is too small, a query or computing job may generate a large number of subtasks. This increases the time and resources in communicating between the controller node and data nodes, and between different controller nodes. Too small partitions also result in innefficient reading/writing of small files on disk and therefore. Lastly, the metadata of all partitions are stored in the memory of the controller node. Too many small partitions may make the controller node run out of memory. We recommend that the partition size is larger than 100 MB on average before compression.
Based on the analysis in the above section, we recommend the size of a partition be between 100MB and 1GB.
The distribution of trading activities of stocks is highly skewed. Some stocks are extremely active but a majority of stocks are much less active. For a composite partition with partitioning columns of trading days and stock tickers, if we use value partitions on both partitioning columns, we will have many extremely small partitions for illiquid stocks. In this case we recommend range partitions on stock tickers where many illiquid stocks can be grouped into one partition, resulting a more evenly distributed dataset for better performance.
4.4. How to Partition Data Evenly
Significant differences among partition sizes may cause load imbalance. Some nodes may have heavy workloads while other nodes idle. If a task is divided into multiple subtasks, it returns the final result only after the last subtask is finished. As each subtask works on a different partition, if data is not distributed evenly among partitions, it may increase the execution time.
A useful tool for partitioning data evenly is function cutPoints(X, N, [freq]), where X is a vector; N means the number of buckets the elements of X will be grouped into; the optional argument freq is a vector of the same length as X indicating the frequency of each element in X. It returns a vector with (N+1) elements such that the elements of X are evenly distributed within each of the N buckets indicated by the vector. It can be used to generate the partition scheme of a range domain in a distributed database.
In the following example, we construct a composite partition on date and symbols for high frequency stock quotes data. We use the data of 2007.08.01 to determine 128 stock symbol ranges with equal number of rows on 2007.08.01, and apply these ranges on the entire dataset.
t = ploadText(WORK_DIR+"/TAQ20070801.csv")
t = select count(*) as ct from t where date=2007.08.01 group by symbol
buckets = cutPoints(t.symbol, 128, t.ct)
dateDomain = database("", VALUE, 2017.07.01..2018.06.30)
symDomain = database("", RANGE, buckets)
stockDB = database("dfs://stockDBTest", COMPO, [dateDomain, symDomain]);4.5. Partitions on Temporal Variables
In the following example, we create a distributed database with a value partition on date. The partitioning scheme extends to the year 2030 to accommodate updates in future time periods.
dateDB = database("dfs://testDate", VALUE, 2000.01.01 .. 2030.01.01)To partition the database by year, you can use RANGE partitions. The following example partitions the databases by year from 2020 to 2029.
yearDB = database("dfs://testYear", RANGE, date(2020.01M + 12 * 0 .. 10)) When using temporal variables as a partition column, the data type of the partition scheme does not need to be the same as the data type of a partitioning column. For example, if we use month as the partition scheme in a value partition, the data type of the partitioning column can be month, date, datetime, timestamp, or nanotimestamp.
4.6. Partition Colocation
It may be time consuming to join multiple tables in a distributed database, as the partitions that need to be joined with may be located on different nodes and therefore data need to be copied and moved across nodes. DolphinDB ensures that the same partitions of all the tables in the same distributed database are stored at the same node. This makes it highly efficient to join these tables. DolphinDB does not support joining tables from different distributed databases.
dateDomain = database("", VALUE, 2018.05.01..2018.07.01)
symDomain = database("", RANGE, string('A'..'Z') join `ZZZZZ)
stockDB = database("dfs://stockDB", COMPO, [dateDomain, symDomain])
quoteSchema = table(10:0, `sym`date`time`bid`bidSize`ask`askSize, [SYMBOL,DATE,TIME,DOUBLE,INT,DOUBLE,INT])
stockDB.createPartitionedTable(quoteSchema, "quotes", `date`sym)
tradeSchema = table(10:0, `sym`date`time`price`vol, [SYMBOL,DATE,TIME,DOUBLE,INT])
stockDB.createPartitionedTable(tradeSchema, "trades", `date`sym)In the examples above, the distributed tables quotes and trades are located in the same distributed database.
5. Import Data into Distributed Databases
DolphinDB is an OLAP database system. It is designed for fast storage and query/computing of massive structured data and for high performance data processing with the in-memory database and streaming functionalities. It is not an OLTP system for frequent updates. When appending new data to a database on disk in DolphinDB, compressed data is inserted at the end of partitions or files in batches, similar to Hadoop HDFS. To update or delete existing rows, entire partitions that contain these rows need to be deleted first and then rewritten.
5.1. Replicas
We can make multiple replicas for each partition in DolphinDB. The number of replicas is 2 by default and can be changed by setting the configuration parameter "dfsReplicationFactor".
There are 2 purposes of replicas: (1) Fault tolerance: If a node is down, the system can use a replica for ongoing projects. (2) Load balance: With a large number of concurrent users, replicas can improve system throughput and decrease latency.
DolphinDB adopts two-phase commit protocol to ensure strong consistency of all replicas of the same partition on different nodes when writing data into the database.
The configuration parameter "dfsReplicaReliabilityLevel" in the controller configuration file (controller.cfg) determines whether multiple replicas are allowed to reside on nodes of the same physical server. In development stage, we can set it to 0 allowing multiple replicas on the same machine. In production stage, however, we should set it to 1 to ensure fault tolerance.
5.2. Transactions
The DFS table engine in DolphinDB supports transactions, i.e., it guarantees ACID (atomicity, consistency, isolation and durability). The DFS table engine uses MVCC for transactions and supports snapshot isolation. With snapshot isolation, reading and writing do not block each other, therefore read operations in a data warehouse is optimized.
To optimize the performance of queries and computing tasks in the data warehouse, DolphinDB has the following restrictions on transactions:
- A transaction cannot involve both read operations and write operations.
- A write transaction can write to multiple partitions, but a partition cannot be written to by multiple transactions simultaneously. If transaction A attempts to lock a partition while the partition is locked by another transaction, the system will immediately throw an exception and transaction A will be rolled back.
5.3. Parallel Data Writing
In DolphinDB, a single table can have millions of partitions. This facilitates fast parallel data loading. Parallel data loading is especially important when huge amount of data is imported into DolphinDB, or when real-time data is persisted to the data warehouse with low latency.
The following example loads stock quotes data to database stockDB in parallel. The data is stored in csv files, with each file representing a different day. The database stockDB uses a composite partition on date and stock symbol. For each file, create a jobID prefix with the file name, and use function submitJob to execute function loadTextEx to load data into database stockDB. Use command pnodeRun to execute the loading task at each data node of the cluster.
dateDomain = database("", VALUE, 2018.05.01..2018.07.01)
symDomain = database("", RANGE, string('A'..'Z') join `ZZZZZ)
stockDB = database("dfs://stockDB", COMPO, [dateDomain, symDomain])
quoteSchema = table(10:0, `sym`date`time`bid`bidSize`ask`askSize, [SYMBOL,DATE,TIME,DOUBLE,INT,DOUBLE,INT])
stockDB.createPartitionedTable(quoteSchema, "quotes", `date`sym)
def loadJob(){
fileDir='/stockData'
filenames = exec filename from files(fileDir)
db = database("dfs://stockDB")
for(fname in filenames){
jobId = fname.strReplace(".csv", "")
submitJob(jobId,, loadTextEx{db, "quotes", `date`sym, fileDir+'/'+fname})
}
}
pnodeRun(loadJob);When multiple writers load data in parallel, we must make sure they wouldn't write data to the same partition simultaneously. Otherwise, at leat one transaction will fail. In the aforementioned example, different data files represent different partitions. Therefore, none of the writing jobs write to the same partition as another job.
5.4. Import Data
We can also use function append! to import data into DolphinDB databases.
n = 1000000
syms = `IBM`MSFT`GM`C`FB`GOOG`V`F`XOM`AMZN`TSLA`PG`S
time = 09:30:00 + rand(21600000, n)
bid = rand(10.0, n)
bidSize = 1 + rand(100, n)
ask = rand(10.0, n)
askSize = 1 + rand(100, n)
quotes = table(rand(syms, n) as sym, 2018.05.04 as date, time, bid, bidSize, ask, askSize)
loadTable("dfs://stockDB", "quotes").append!(quotes);5.4.1. Import Data from Text Files
DolphinDB provides 3 function to load text files: loadText, ploadText, and loadTextEx.
workDir = "C:/DolphinDB/Data"
if(!exists(workDir)) mkdir(workDir)
quotes.saveText(workDir + "/quotes.csv")loadText and ploadText load text files smaller than available memory. ploadText loads data in parallel as a partitioned table in memory and is faster than loadText.
t=loadText(workDir + "/trades.csv")
ploadTable("dfs://stockDB", "quotes").append!(t)loadTextEx can load files much larger than available memory and can load data directly to databases. loadTextEx implicitly executes function append!.
db = database("dfs://stockDB")
loadTextEx(db, "quotes", `date`sym, workDir + "/quotes.csv")5.4.2. Subscibe to a Stream Table and Import Data in Batches
In the following example we subscribe to a stream table quotes_stream. The streaming data from quotes_stream will be inserted to table quotes if the incoming data reaches 10,000 rows or if 6 seconds have elapsed since the last time streaming data were inserted into table quotes, whichever occurs first.
dfsQuotes = loadTable("dfs://stockDB", "quotes")
saveQuotesToDFS=def(mutable t, msg): t.append!(select today() as date,* from msg)
subscribeTable(, "quotes_stream", "quotes", -1, saveQuotesToDFS{dfsQuotes}, true, 10000, 6)5.4.3. Import from Databases of Other Vendors via ODBC
The following example imports table TAQquotes from MySQL.
loadPlugin("/DOLPHINDB_DIR/server/plugins/odbc/odbc.cfg")
conn=odbc::connect("Driver=MySQL;Data Source = mysql-stock;server=127.0.0.1;uid=[xxx];pwd=[xxx];database=stockDB")
t=odbc::query(conn,"select * from quotes")
loadTable("dfs://stockDB", "quotes").append!(t)5.4.4. Import Data with Programming APIs
DolphinDB provides APIs for Python, Java, C++, C#, R and JavaScript. After getting data with these languages, we can call function append! to import data into distributed databases in DolphinDB. The following script is an example for Java API.
DBConnection conn = new DBConnection();Connect to a DolphinDB server:
conn.connect("localhost", 8848, "admin", "123456");Define function saveQuotes:
conn.run("def saveQuotes(t){ loadTable('dfs://stockDB','quotes').append!(t)}");Prepare a table:
BasicTable quotes = ...Call function saveQuotes:
List<Entity> args = new ArrayList<Entity>(1);
args.add(quotes);
conn.run("saveQuotes", args);6. Queries on Partitioned Tables
Most distributed queries do not involve all partitions of a distributed table. It could save a significant amount of time if the system can narrow down relevant partitions before loading and processing data.
DolphinDB conducts partition pruning based on relational operators (<, <=, =, ==, >, >=, in, between) and logical operators (or, and) with the partitioning column(s).
n=10000000
id=take(1..1000, n).sort()
date=1989.12.31+take(1..365, n)
announcementDate=date+rand(1..10, n)
x=rand(1.0, n)
y=rand(10, n)
t=table(id, date, announcementDate, x, y)
db=database("dfs://rangedb1", RANGE, [1990.01.01, 1990.03.01, 1990.05.01, 1990.07.01, 1990.09.01, 1990.11.01, 1991.01.01])
pt = db.createPartitionedTable(t, `pt, `date)
pt.append!(t);
pt=db.loadTable(`pt);The following queries can narrow down relevant partitions:
select * from pt where date>1990.04.01 and date<1990.06.01;The system determines that only 2 partitions ([1990.03.01, 1990.05.01) and [1990.05.01, 1990.07.01)) are relevant to this query.
select * from pt where date>1990.12.01-10;The system determines that only 1 partition [1990.11.01, 1991.01.01) is relevant to this query.
select count(*) from pt where date between 1990.08.01:1990.12.01 group by date;The system determines that only 3 partitions ([1990.07.01, 1990.09.01), [1990.09.01, 1990.11.01) and [1990.11.01, 1991.01.01)) are relevant to this query.
select * from pt where y<5 and date between 1990.08.01:1990.08.31;The system narrows down the relevant partitions to [1990.07.01, 1990.09.01). Please note that in this step, the system ignores the condition of y<5. After loading the relevant partition, the system will use the condition of y<5 to further filter the data.
The following queries cannot narrow down the relevant partitions. If used on a huge partitioned table, they will take a long time to finish. For this reason these queries should be avoided.
select * from pt where date+10>1990.08.01;
select * from pt where 1990.08.01<date<1990.09.01;
select * from pt where month(date)<=1990.03M;
select * from pt where y<5;
announcementDate=1990.08.08
select * from pt where date<announcementDate-3;
select * from pt where y<5 or date between 1990.08.01:1990.08.31;