Best Practices for Market Data Replay
This tutorial introduces the practical implementation of the DolphinDB’s replay feature. Based on the DolphinDB’s streaming replay, distributed database architecture and APIs, you can create a powerful tool for historical insight and model back-testing, which allows you to review situations of interest and improve future performance. By following instructions in this tutorial, you will learn
- the workflow of constructing a market replay solution;
- the optimal data storage plan for data sources;
- the methods to process and analyze replayed data via APIs;
- the performance of the replay functionality.
Note: For detailed instructions on how to replay market data, refer to Tutorial: Market Data Replay.
1. Construct a Market Data Replay Solution
This chapter guides you through the process of building a comprehensive market data replay solution. Our implementation focuses on three types of market data: quote tick data, trade tick data and snapshots of Level-2 data. The service offers the following capabilities:
- Multi-client support: Allows submission of replay requests via various clients (including C++ and Python API).
- Concurrent user requests: Supports simultaneous replay requests from multiple users.
- Multi-source synchronization: Enables orderly replay of multiple data sources concurrently.
- Advanced ordering options: Provides time-based ordering and further sequential ordering based on timestamps (e.g., based on record numbers of tick data).
- Completion signal: Signals the end of replay.
- Flexible data consumption: Offers subscription-based access to process replayed results.
1.1 Architecture
The solution we build has the following architecture:
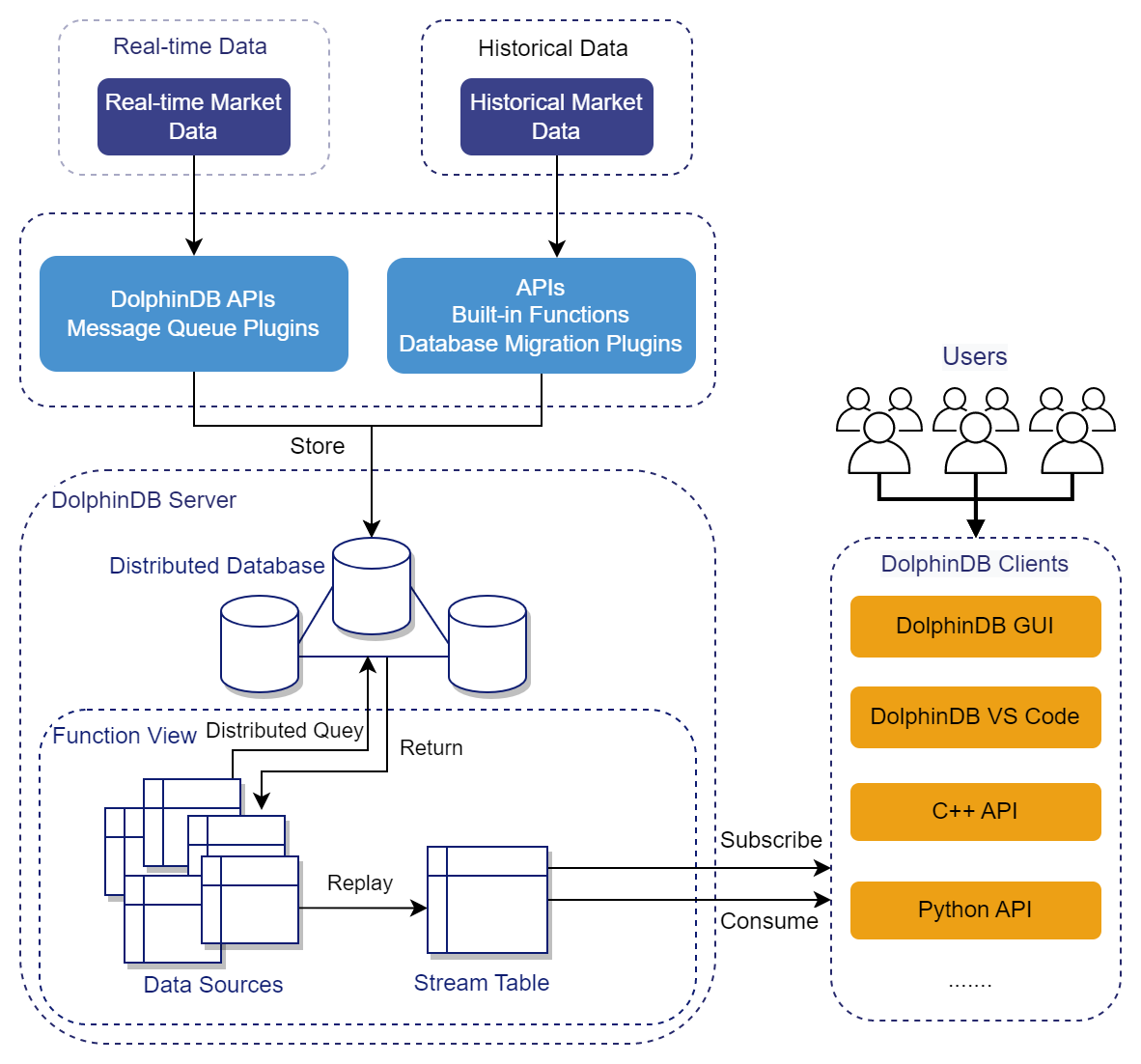
- Market Data Ingestion: Both real-time and historical tick data can be imported to the DolphinDB distributed database via the DolphinDB API or a plugin.
- Function Encapsulation: Functions used during the replay process can be encapsulated as function views. Key parameters such as stock list, replay date, replay rate, data source can still be specified by users.
- User Request: Users can replay market data by calling the function view through DolphinDB clients (such as DolphinDB GUI, VS Code Extension, APIs). Users can also subscribe to and consume real-time replay results on the client side. Additionally, multi-user concurrent replay is supported.
1.2 Steps
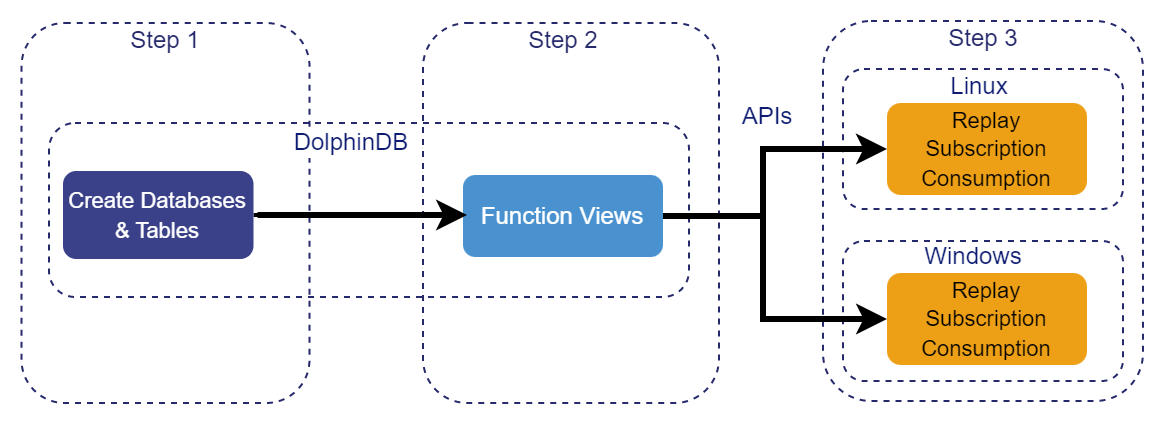
- Step 1 (Chapter 2): Design and implement a suitable distributed database structure in DolphinDB. Create the necessary tables and import historical market data to serve as the replay data source.
- Step 2 (Chapter 3): Develop a DolphinDB function view that encapsulates the entire replay process. This abstraction allows users to initiate replay requests by simply specifying key parameters, without needing to understand the details of DolphinDB's replay functionality.
- Step 3 (Chapter 4 & 5): Utilize the DolphinDB API to call the previously created function view from external applications. This enables the execution of replay operations outside the DolphinDB environment. Additionally, users can set up subscriptions to consume real-time replay results on the client side.
2. Storage Plan for Market Data
The example in this tutorial replays three types of market data: quote tick data, trade tick data and snapshots of Level-2 data.
| Data Source | Table | Partitioning scheme | Sort column | Script |
|---|---|---|---|---|
| quote tick data (dfs://Test_order) | order | VALUE: trade date; HASH: [SYMBOL, 25] | SecurityID; MDTime | create_order |
| trade tick data (dfs://Test_transaction) | transaction | VALUE: trade date; HASH: [SYMBOL, 25] | SecurityID; MDTime | create_transaction |
| snapshots of Level-2 data (dfs://Test_snapshot) | snapshot | VALUE: trade date; HASH: [SYMBOL, 25] | SecurityID; MDTime | create_snapshot |
The replay mechanism operates on a fundamental principle: it retrieves the necessary tick data from the database, sorts it chronologically, and then writes it to the stream table. This process is heavily influenced by the efficiency of database reading and sorting operations, which directly impacts the overall replay speed.
To optimize performance, a well-designed partitioning scheme is crucial. The partitioning scheme of tables outlined above is tailored to common replay requests, which are typically submitted based on specific dates and stocks.
In addition, here, we utilize the DolphinDB cluster for storing historical data. The cluster consists of three data nodes and maintains two chunk replicas. The distributed nature of the cluster allows for parallel data access across multiple nodes, significantly boosting read speeds. By maintaining multiple copies of the data, the system achieves higher resilience against potential node failures.
3. User-Defined Functions for Replay
This chapter delves into the core functionalities of the replay process and their implementation details. These functions are then encapsulated into function views, which can be called through APIs.
| Function Name | Parameter | Description |
|---|---|---|
| stkReplay |
|
Replays data |
| dsTb |
|
Constructs the data source to be replayed |
| createEnd |
|
Returns a signal to indicate the end of the replay |
| replayJob |
|
Defines the replay job |
3.1 stkReplay - Replay
The stkReplay function is used to perform the replay
operation.
def stkReplay(stkList, mutable startDate, mutable endDate, replayRate, replayUuid, replayName)
{
maxCnt = 50
returnBody = dict(STRING, STRING)
startDate = datetimeParse(startDate, "yyyyMMdd")
endDate = datetimeParse(endDate, "yyyyMMdd") + 1
sortColumn = "ApplSeqNum"
if(stkList.size() > maxCnt)
{
returnBody["errorCode"] = "0"
returnBody["errorMsg"] = "Exceeds the limits for a single replay. The maximum is: " + string(maxCnt)
return returnBody
}
if(size(replayName) != 0)
{
for(name in replayName)
{
if(not name in ["snapshot", "order", "transaction"])
{
returnBody["errorCode"] = "0"
returnBody["errorMsg"] = "Input the correct name of the data source. Cannot recognize: " + name
return returnBody
}
}
}
else
{
returnBody["errorCode"] = "0"
returnBody["errorMsg"] = "Missing data source. Input the correct name of the data source."
return returnBody
}
try
{
if(size(replayName) == 1 && replayName[0] == "snapshot")
{
colName = ["timestamp", "biz_type", "biz_data"]
colType = [TIMESTAMP, SYMBOL, BLOB]
sortColumn = "NULL"
}
else
{
colName = ["timestamp", "biz_type", "biz_data", sortColumn]
colType = [TIMESTAMP, SYMBOL, BLOB, LONG]
}
msgTmp = streamTable(10000000:0, colName, colType)
tabName = "replay_" + replayUuid
enableTableShareAndPersistence(table=msgTmp, tableName=tabName, asynWrite=true, compress=true, cacheSize=10000000, retentionMinutes=60, flushMode=0, preCache=1000000)
timeRS = cutPoints(09:30:00.000..15:00:00.000, 23)
inputDict = dict(replayName, each(dsTb{timeRS, startDate, endDate, stkList}, replayName))
dateDict = dict(replayName, take(`MDDate, replayName.size()))
timeDict = dict(replayName, take(`MDTime, replayName.size()))
jobId = "replay_" + replayUuid
jobDesc = "replay stock data"
submitJob(jobId, jobDesc, replayJob{inputDict, tabName, dateDict, timeDict, replayRate, sortColumn})
returnBody["errorCode"] = "1"
returnBody["errorMsg"] = "Replay successfully"
return returnBody
}
catch(ex)
{
returnBody["errorCode"] = "0"
returnBody["errorMsg"] = "Exception occurred when replaying: " + ex
return returnBody
}
}Note: The function definition is flexible and can be customized to suit specific requirements.
The parameters passed in will first be validated and formatted:
- The stkList parameter is limited to a maximum of 50 stocks (defined
by
maxCnt) for a single replay operation. - Parameters startDate and endDate are formatted by
startDateandendDateusing thedatetimeParsefunction. - replayName is the list of data sources to be replayed. It must be one of "snapshot", "order", "transaction", in this example.
If any parameters fail validation, the function reports errors (as defined in
returnBody). Upon successful parameter validation, the
function proceeds to initialize the output table.
The output table "msgTmp” is defined as a heterogeneous stream table where the
BLOB column stores the serialized result of each replayed record. To optimize
memory usage, it is shared and persisted with the
enableTableShareAndPersistence function.
When the data source includes both "transaction” and "order”, an extra sort column can be specified for records with the same timestamp. In this example, records in "transaction” and "order” with the same timestamp are sorted by the record number "ApplSeqNum” (See section 3.3 replayJob function for details). In such case, the output table must contain the sort column. If the data source contains only "snapshots”, the sort column is not required.
Then, submit the replay job using the submitJob function. You
will be informed about the status of the replay job, whether it has executed
successfully or encountered an exception (as defined in
returnBody).
3.2 dsTb - Construct Data Sources
The dsTb function is used to prepare the data sources to be
replayed.
def dsTb(timeRS, startDate, endDate, stkList, replayName)
{
if(replayName == "snapshot"){
tab = loadTable("dfs://Test_snapshot", "snapshot")
}
else if(replayName == "order") {
tab = loadTable("dfs://Test_order", "order")
}
else if(replayName == "transaction") {
tab = loadTable("dfs://Test_transaction", "transaction")
}
else {
return NULL
}
ds = replayDS(sqlObj=<select * from tab where MDDate>=startDate and MDDate<endDate and HTSCSecurityID in stkList>, dateColumn='MDDate', timeColumn='MDTime', timeRepartitionSchema=timeRS)
return ds
}The dsTb function serves as a higher-level wrapper around the
built-in replayDS function.
- It first evaluates the provided replayName to determine which dataset to use.
- Based on the replayName, it loads the corresponding table object from the database.
- Using
replayDS, it segments the data with stkList in the range of [startDate, endDate) into multiple data sources based on timeRS, and returns a list of data sources.
The timeRS parameter, which corresponds to the
timeRepartitionSchema parameter in the replayDS
function, is a vector of temporal types to create finer-grained data sources,
ensuring efficient querying of the DFS table and optimal manage memory
usage.
The timeRS in this example is defined as a variable in the
stkReplay function, timeRS =
cutPoints(09:30:00.000..15:00:00.000, 23), which means to divide
data in trading hours (09:30:00.000..15:00:00.000) into 23
equal parts.
dsTb works, execute the following
script. For the "order" data source, the records with Security ID "000616.SZ" in
trading hours of 2021.12.01 are divided into 3 parts.
timeRS = cutPoints(09:30:00.000..15:00:00.000, 3)
startDate = 2021.12.01
endDate = 2021.12.02
stkList = ['000616.SZ']
replayName = ["order"]
ds = dsTb(timeRS, startDate, endDate, stkList, replayName)DataSource< select [4] * from tab where time(MDTime) < 09:30:00.000,nanotime(MDTime) >= 00:00:00.000000000,date(MDDate) == 2021.12.01,MDDate >= 2021.12.01 and MDDate < 2021.12.02 and SecurityID in ["000616.SZ"] order by MDDate asc,MDTime asc >
DataSource< select [4] * from tab where time(MDTime) < 11:20:00.001,time(MDTime) >= 09:30:00.000,date(MDDate) == 2021.12.01,MDDate >= 2021.12.01 and MDDate < 2021.12.02 and SecurityID in ["000616.SZ"] order by MDDate asc,MDTime asc >
DataSource< select [4] * from tab where time(MDTime) < 13:10:00.001,time(MDTime) >= 11:20:00.001,date(MDDate) == 2021.12.01,MDDate >= 2021.12.01 and MDDate < 2021.12.02 and SecurityID in ["000616.SZ"] order by MDDate asc,MDTime asc >
DataSource< select [4] * from tab where time(MDTime) < 15:00:00.001,time(MDTime) >= 13:10:00.001,date(MDDate) == 2021.12.01,MDDate >= 2021.12.01 and MDDate < 2021.12.02 and SecurityID in ["000616.SZ"] order by MDDate asc,MDTime asc >
DataSource< select [4] * from tab where nanotime(MDTime) <= 23:59:59.999999999,time(MDTime) >= 15:00:00.001,date(MDDate) == 2021.12.01,MDDate >= 2021.12.01 and MDDate < 2021.12.02 and SecurityID in ["000616.SZ"] order by MDDate asc,MDTime asc >3.3 replayJob - Define Replay Job
The replayJob function is used to define the replay job.
def replayJob(inputDict, tabName, dateDict, timeDict, replayRate, sortColumn)
{
if(sortColumn == "NULL")
{
replay(inputTables=inputDict, outputTables=objByName(tabName), dateColumn=dateDict, timeColumn=timeDict, replayRate=int(replayRate), absoluteRate=false, parallelLevel=23)
}
else
{
replay(inputTables=inputDict, outputTables=objByName(tabName), dateColumn=dateDict, timeColumn=timeDict, replayRate=int(replayRate), absoluteRate=false, parallelLevel=23, sortColumns=sortColumn)
}
createEnd(tabName, sortColumn)
}The replayJob function encapsulates the built-in
replay function to perform an N-to-1 heterogeneous replay.
Once all required data has been replayed, the createEnd
function is called to construct and write an end signal into the replay result,
marking the conclusion of the replay process with a special record.
The inputDict, dateDict and timeDict are defined as
variables in the stkReplay function:
- inputDict is a dictionary indicating data sources to be replayed. The
higher-order function
eachis used to define the data source for each replayName. - dateDict and timeDict are dictionaries indicating the date and time columns of the data sources, used for data sorting.
The replayJob function includes a sortColumn parameter
for additional data ordering. If the data source consists only of "snapshots”
(where ordering is not a concern), sortColumn should be set to NULL. In
this case, the built-in replay function is called without its
sortColumns parameter. For other data sources ("order" and
"transaction"), sortColumn can be used to specify an extra column for
sorting the data with the same timestamp.
3.4 createEnd - Signal the End
The createEnd function is used to define the end signal. It can
be optionally defined.
def createEnd(tabName, sortColumn)
{
dbName = "dfs://End"
tbName = "endline"
if(not existsDatabase(dbName))
{
db = database(directory=dbName, partitionType=VALUE, partitionScheme=2023.04.03..2023.04.04)
endTb = table(2200.01.01T23:59:59.000 as DateTime, `END as point, long(0) as ApplSeqNum)
endLine = db.createPartitionedTable(table=endTb, tableName=tbName, partitionColumns=`DateTime)
endLine.append!(endTb)
}
ds = replayDS(sqlObj=<select * from loadTable(dbName, tbName)>, dateColumn='DateTime', timeColumn='DateTime')
inputEnd = dict(["end"], [ds])
dateEnd = dict(["end"], [`DateTime])
timeEnd = dict(["end"], [`DateTime])
if(sortColumn == "NULL")
{
replay(inputTables=inputEnd, outputTables=objByName(tabName), dateColumn=dateEnd, timeColumn=timeEnd, replayRate=-1, absoluteRate=false, parallelLevel=1)
}
else
{
replay(inputTables=inputEnd, outputTables=objByName(tabName), dateColumn=dateEnd, timeColumn=timeEnd, replayRate=-1, absoluteRate=false, parallelLevel=1, sortColumns=sortColumn)
}
}The createEnd function signals the end of the replay process,
writing a record labeled "end” to the output table (specified by
tabName). inputEnd, dateEnd, timeEnd are
dictionaries with the string "end” as the key, which corresponds to the second
column (biz_type) in the output table.
To streamline parsing and consumption of the output table, a separate database is created specifically for the end signal. Within this database, a partitioned table is established. This table must include a time column, with other fields being optional. A simulated record is written to this table. This record is not strictly defined and can be customized as needed. For instructions on how to create database and table, refer to DolphinDB Tutorial: Distributed Database.
createEnd function also includes a sortColumn
parameter to determine whether to call the built-in replay
function with or without its sortColumns parameter. The following figure
demonstrates an end signal in the output table when sortColumn is set to
NULL.
3.5 Encapsulate Functions
addFunctionView function, as shown in the following script.
addFunctionView(dsTb)
addFunctionView(createEnd)
addFunctionView(replayJob)
addFunctionView(stkReplay)4. Replay Data with APIs
By creating function views, we've simplified the interface for API clients. Now, we
only need to invoke the function stkReplay in APIs to initiate the
replay process. The replay process detailed in this chapter is all built upon the
above function view.
4.1 With C++ API
This example runs on a Linux OS, with DolphinDB C++ API environment set up. With executable files compiled, you can run the code from the command line interface. The full script is available in the Appendices: C++ code.
The C++ application interacts with the DolphinDB server using a DBConnection
object (conn). Through DBConnection, you can
execute scripts and functions on the DolphinDB server and transfer data in both
directions.
The application invokes the stkReplay function on the DolphinDB
server using the DBConnection::run function. The args
holds all the necessary arguments for the stkReplay function.
The function's result is captured in a dictionary named 'result'. The
application checks the "errorCode” key of the result using the
get method. If the errorCode is not 1, it indicates
an execution error. In this case, the application returns an error message and
terminates the program.
stkReplay
function.DictionarySP result = conn.run("stkReplay", args);
string errorCode = result->get(Util::createString("errorCode"))->getString();
if (errorCode != "1")
{
std::cout << result->getString() << endl;
return -1;
}string uuid(int len)
{
char* str = (char*)malloc(len + 1);
srand(getpid());
for (int i = 0; i < len; ++i)
{
switch (i % 3)
{
case 0:
str[i] = 'A' + std::rand() % 26;
break;
case 1:
str[i] = 'a' + std::rand() % 26;
break;
default:
str[i] = '0' + std::rand() % 10;
break;
}
}
str[len] = '\0';
std::string rst = str;
free(str);
return rst;
}4.2 With Python API
This example runs on a Windows OS, with DolphinDB Python API environment set up. The full script is available in the Appendices: Python Code.
The Python application interacts with the DolphinDB server using a session object
(s). Through sessions, you can execute scripts and
functions on the DolphinDB server and transfer data in both directions.
Once the necessary variables (stk_list, start_date,
end_date, replay_rate, replay_uuid, and replay_name)
have been defined, the upload method is used to upload these
objects to DolphinDB server and the run method is invoked to
execute the stkReplay function.
stkReplay
function.stk_list = ['000616.SZ','000681.SZ']
start_date = '20211201'
end_date = '20211201'
replay_rate = -1
replay_name = ['snapshot']
s.upload({'stk_list':stk_list, 'start_date':start_date, 'end_date':end_date, 'replay_rate':replay_rate, 'replay_uuid':uuidStr, 'replay_name':replay_name})
s.run("stkReplay(stk_list, start_date, end_date, replay_rate, replay_uuid, replay_name)")def uuid(length):
str=""
for i in range(length):
if(i % 3 == 0):
str += chr(ord('A') + random.randint(0, os.getpid() + 1) % 26)
elif(i % 3 == 1):
str += chr(ord('a') + random.randint(0, os.getpid() + 1) % 26)
else:
str += chr(ord('0') + random.randint(0, os.getpid() + 1) % 10)
return str
uuidStr = uuid(16)5. Consume Replayed Data with APIs
This chapter introduces how to consume replayed data with C++ API and Python API.
5.1 With C++ API
5.1.1 Construct a Deserializer
DictionarySP snap_full_schema = conn.run("loadTable(\"dfs://Test_snapshot\", \"snapshot\").schema()");
DictionarySP order_full_schema = conn.run("loadTable(\"dfs://Test_order\", \"order\").schema()");
DictionarySP transac_full_schema = conn.run("loadTable(\"dfs://Test_transaction\", \"transaction\").schema()");
DictionarySP end_full_schema = conn.run("loadTable(\"dfs://End\", \"endline\").schema()");
unordered_map<string, DictionarySP> sym2schema;
sym2schema["snapshot"] = snap_full_schema;
sym2schema["order"] = order_full_schema;
sym2schema["transaction"] = transac_full_schema;
sym2schema["end"] = end_full_schema;
StreamDeserializerSP sdsp = new StreamDeserializer(sym2schema);The initial four lines get table schemata of "snapshot," "order," "transaction," and "end signal". During replay, the appropriate schema is chosen as needed, with the end being required.
To handle heterogeneous stream tables, a StreamDeserializer
object is created using the sym2schema method. This approach maps
symbols (keys for source tables) to their respective table schemata.
Subsequently, both the data sources and the end signal are deserialized
based on these schemata.
For detailed instructions, see C++ API Reference Guide: Constructing a Deserializer.
5.1.2 Subscribe to Replayed Data
int listenport = 10260;
ThreadedClient threadedClient(listenport);
string tableNameUuid = "replay_" + uuidStr;
auto thread = threadedClient.subscribe(hostName, port, myHandler, tableNameUuid, "stkReplay", 0, true, nullptr, true, 500000, 0.001, false, "admin", "123456", sdsp);
std::cout << "Successfully subscribe to " + tableNameUuid << endl;
thread->join();- listenport is the subscription port of the single-threaded client.
- tableNameUuid is the name of the stream table to be consumed.
We subscribe to the stream table through
threadedClient.subscribe. The thread returned
points to the thread that continuously invokes myHandler. It will
stop calling myHandler when function unsubscribe is
called on the same topic.
For detailed instructions, see the C++ API Reference Guide: Subscription.
5.1.3 Define the Handler for Processing Data
The threadedClient.subscribe method is used to subscribe to
the heterogeneous stream table. During this process, the
StreamDeserializerSP instance deserializes incoming
data and routes it to a user-defined function handler. Users can
customize data processing logic by implementing their own myHandler
function.
threadedClient.unsubscribe. The implementation of
myHandler for this example is as
follows:long sumcount = 0;
long long starttime = Util::getNanoEpochTime();
auto myHandler = [&](vector<Message> msgs)
{
for (auto& msg : msgs)
{
std::cout << msg.getSymbol() << " : " << msg->getString() << endl;
if(msg.getSymbol() == "end")
{
threadedClient.unsubscribe(hostName, port, tableNameUuid,"stkReplay");
}
sumcount += msg->get(0)->size();
}
long long speed = (Util::getNanoEpochTime() - starttime) / sumcount;
std::cout << "callback speed: " << speed << "ns" << endl;
};5.1.4 Execute the Application
After compiling the main file with the aforementioned code within the DolphinDB C++ API environment, you can initiate the "replay -subscription - consumption" process using specific commands.
- To replay data of a single stock from one table ("order") for one day at
maximum
speed:
$ ./main 000616.SZ 20211201 20211201 -1 order - To replay data of two (or more) stocks from three tables ("snapshot",
"order", "transaction") for one day at maximum
speed:
$ ./main 000616.SZ,000681.SZ 20211201 20211201 -1 snapshot,order,transaction
5.1.5 Output the Result
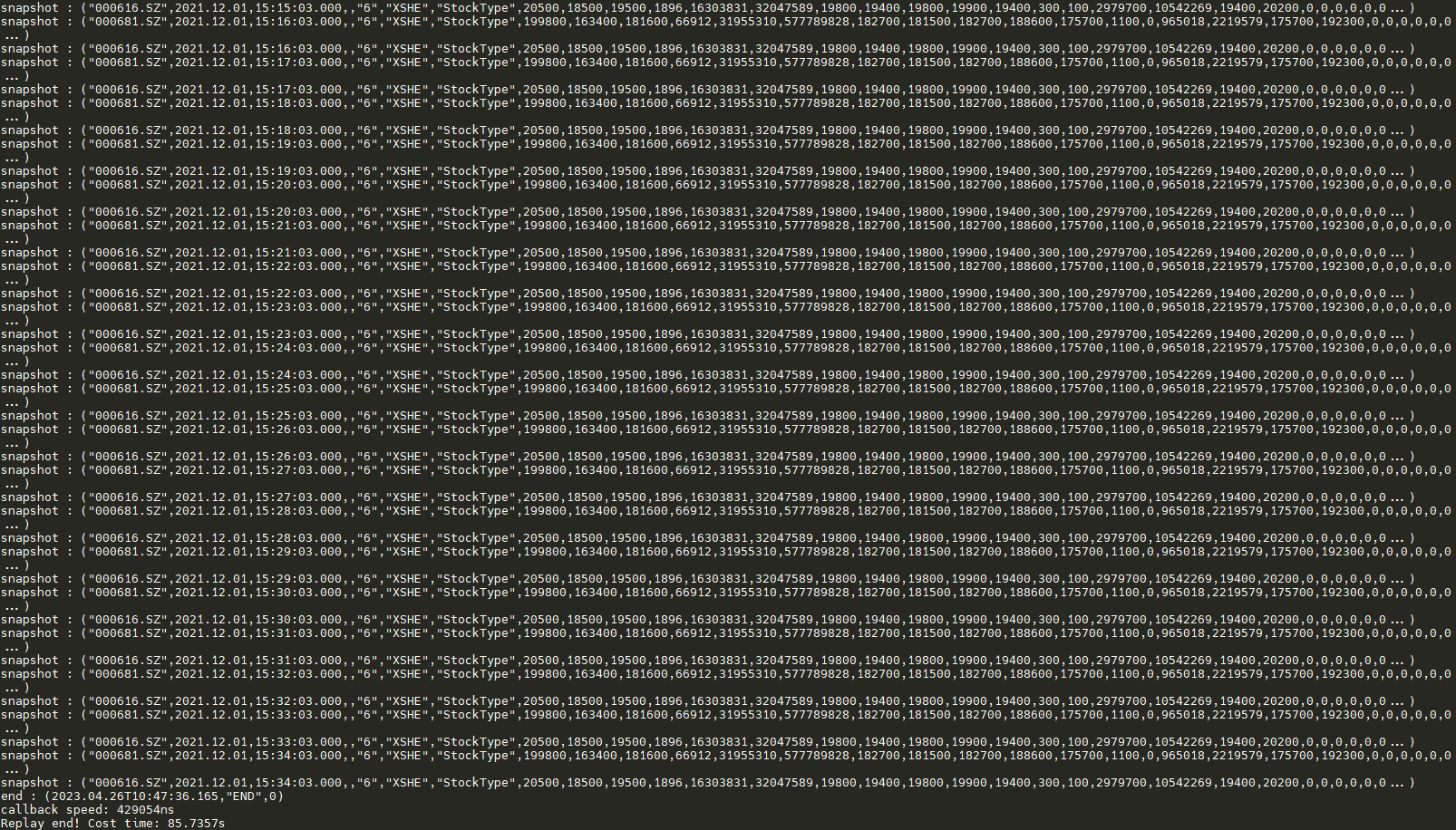
5.2 With Python API
5.2.1 Construct a Deserializer
sd = ddb.streamDeserializer({
'snapshot': ["dfs://Test_snapshot", "snapshot"],
'order': ["dfs://Test_order", "order"],
'transaction': ["dfs://Test_transaction", "transaction"],
'end': ["dfs://End", "endline"],
}, s)To handle heterogeneous stream tables, a streamDeserializer
object is created. The parameter sym2table is defined as a dictionary
object. The keys are the source tables (i.e., "snapshot," "order,"
"transaction," and "end signal") and the values are the schema of each
table. Note that during replay, the appropriate schema is chosen as needed,
with the end signal schema being required.
For detailed instructions, see Python API Reference Guide: streamDeserializer.
5.2.2 Subscribe to Replayed Data
s.enableStreaming(0)
s.subscribe(host=hostname, port=portname, handler=myHandler, tableName="replay_"+uuidStr, actionName="replay_stock_data", offset=0, resub=False, msgAsTable=False, streamDeserializer=sd, userName="admin", password="123456")
event.wait()The enableStreaming method is used to enable streaming data
subscription. Then call s.subscribe to create the
subscription. Call event.wait() to block the current thread
to keep receiving data in the background.
For detailed instructions, see the Python API Reference Guide: Subscription.
5.2.3 Define the Handler for Processing Data
The s.subscribe method is used to subscribe to the
heterogeneous stream table. During this process, the
streamDeserializer instance deserializes incoming data
and routes it to a user-defined function handler. Users can customize
data processing logic by implementing their own myHandler function.
def myHandler(lst):
if lst[-1] == "snapshot":
print("SNAPSHOT: ", lst)
elif lst[-1] == 'order':
print("ORDER: ", lst)
elif lst[-1] == 'transaction':
print("TRANSACTION: ", lst)
else:
print("END: ", lst)
event.set()5.2.4 Output the Result
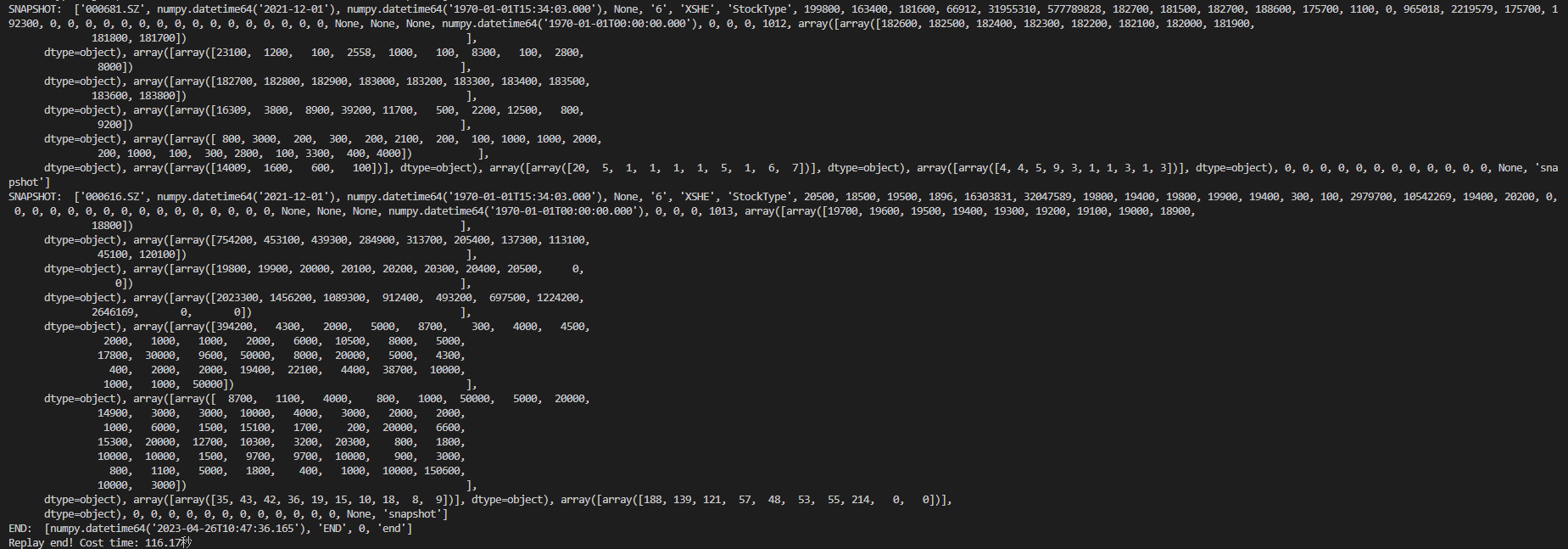
6. Performance Testing
We selected 50 stocks ranged from 2021.12.01 to 2021.12.09 for our performance testing. The test scripts can be found in the Appendices: C++ Test Code.
6.1 Test Environment
- Processor family: Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz
- CPU(s): 64
- Memory: 503 GB
- Disk: SSD
- OS: CentOS Linux release 7.9.2009 (Core)
- DolphinDB Server: version 2.00.9.3 (released on 2023.03.29)
6.2 Concurrent Replays of 50 Stocks on One Trading Day
- Elapsed Time: the latest finish time - the earliest receive time across all replay tasks.
- Replay Rate: the sum of all users' replay data volume / the total elapsed time.
- Average Single-User Elapsed Time: (the sum of start times - the sum of end times) / the number of concurrent tasks.
- Average Single-User Replay Rate: the amount of data replayed by a single user / the average single-user elapsed time.
| Parallelism | Data Source | Data Volume | Elapsed Time (s) | Replay Rate (w/s) | Average Single-User Elapsed Time (s) | Average Single-User Replay Rate (w/s) |
|---|---|---|---|---|---|---|
| 1 | snapshot; transaction; order | 2,775,129 | ≈2.669 | ≈104 | ≈2.669 | ≈104 |
| 10 | snapshot; transaction; order | 27,751,290 | ≈10.161 | ≈273 | ≈8.482 | ≈32 |
| 20 | snapshot; transaction; order | 55,502,580 | ≈18.761 | ≈296 | ≈16.728 | ≈16 |
| 40 | snapshot; transaction; order | 111,005,160 | ≈35.537 | ≈312 | ≈19.091 | ≈14 |
| 1 | snapshot; transaction | 1,416,548 | ≈2.003 | ≈70 | ≈2.003 | ≈70 |
| 10 | snapshot; transaction | 14,165,480 | ≈7.155 | ≈198 | ≈6.382 | ≈22 |
| 20 | snapshot; transaction | 28,330,960 | ≈13.115 | ≈216 | ≈11.436 | ≈12 |
| 40 | snapshot; transaction | 56,661,920 | ≈27.003 | ≈210 | ≈13.740 | ≈10 |
| 1 | snapshot | 194,045 | ≈1.387 | ≈14 | ≈1.387 | ≈14 |
| 10 | snapshot | 1,940,450 | ≈6.428 | ≈30 | ≈5.128 | ≈4 |
| 20 | snapshot | 3,880,900 | ≈11.782 | ≈33 | ≈10.539 | ≈2 |
| 40 | snapshot | 7,761,800 | ≈23.274 | ≈33 | ≈12.393 | ≈1 |
6.3 Replays of 50 Stocks Across Multiple Trading Days
- Elapsed Time = the latest finish time - the earliest receive time.
- Replay Rate = data volume / the total elapsed time.
| Data Source | Data Volume | Elapsed Time (s) | Replay Rate (w/s) |
|---|---|---|---|
| snapshot; transaction; order | one day: 2,775,129 | ≈2.925 | ≈95 |
| snapshot; transaction; order | one week: 17,366,642 | ≈16.393 | ≈106 |
| snapshot; transaction | one day: 1,416,548 | ≈1.912 | ≈74 |
| snapshot; transaction | one week: 8,899,562 | ≈9.142 | ≈97 |
| snapshot | one day: 194,045 | ≈1.267 | ≈15 |
7. Development Environment
7.1 DolphinDB Server
- Server Version: 2.00.9.3 (released on 2023.03.29)
- Deployment: standalone mode (see standalone deployment)
- Configuration: cluster.cfg
maxMemSize=128
maxConnections=5000
workerNum=24
webWorkerNum=2
chunkCacheEngineMemSize=16
newValuePartitionPolicy=add
logLevel=INFO
maxLogSize=512
node1.volumes=/ssd/ssd3/pocTSDB/volumes/node1,/ssd/ssd4/pocTSDB/volumes/node1
node2.volumes=/ssd/ssd5/pocTSDB/volumes/node2,/ssd/ssd6/pocTSDB/volumes/node2
node3.volumes=/ssd/ssd7/pocTSDB/volumes/node3,/ssd/ssd8/pocTSDB/volumes/node3
diskIOConcurrencyLevel=0
node1.redoLogDir=/ssd/ssd3/pocTSDB/redoLog/node1
node2.redoLogDir=/ssd/ssd4/pocTSDB/redoLog/node2
node3.redoLogDir=/ssd/ssd5/pocTSDB/redoLog/node3
node1.chunkMetaDir=/ssd/ssd3/pocTSDB/metaDir/chunkMeta/node1
node2.chunkMetaDir=/ssd/ssd4/pocTSDB/metaDir/chunkMeta/node2
node3.chunkMetaDir=/ssd/ssd5/pocTSDB/metaDir/chunkMeta/node3
node1.persistenceDir=/ssd/ssd6/pocTSDB/persistenceDir/node1
node2.persistenceDir=/ssd/ssd7/pocTSDB/persistenceDir/node2
node3.persistenceDir=/ssd/ssd8/pocTSDB/persistenceDir/node3
maxPubConnections=128
subExecutors=24
subThrottle=1
persistenceWorkerNum=1
node1.subPort=8825
node2.subPort=8826
node3.subPort=8827
maxPartitionNumPerQuery=200000
streamingHAMode=raft
streamingRaftGroups=2:node1:node2:node3
node1.streamingHADir=/ssd/ssd6/pocTSDB/streamingHADir/node1
node2.streamingHADir=/ssd/ssd7/pocTSDB/streamingHADir/node2
node3.streamingHADir=/ssd/ssd8/pocTSDB/streamingHADir/node3
TSDBCacheEngineSize=16
TSDBCacheEngineCompression=false
node1.TSDBRedoLogDir=/ssd/ssd3/pocTSDB/TSDBRedoLogDir/node1
node2.TSDBRedoLogDir=/ssd/ssd4/pocTSDB/TSDBRedoLogDir/node2
node3.TSDBRedoLogDir=/ssd/ssd5/pocTSDB/TSDBRedoLogDir/node3
TSDBLevelFileIndexCacheSize=20
TSDBLevelFileIndexCacheInvalidPercent=0.6
lanCluster=0
enableChunkGranularityConfig=trueNote: Modify configuration parameter persistenceDir with your own path.
7.2 DolphinDB Client
- Processor family: Intel(R) Core(TM) i5-11500 @ 2.70GHz 2.71 GHz
- CPU(s): 12
- Memory: 16 GB
- OS: Windows 11 Pro
- DolphinDB GUI Version: 1.30.20.1
See GUI to install DolphinDB GUI.
7.3 DolphinDB C++ API
- C++ API Version: release200.9Note: It is recommended installing C++API with the version corresponding to DolphinDB server. For example, install the API of release 200 for the DolphinDB server V2.00.9.
- For instruction on installing and using C++ API, see C++ API Reference Guide.
7.4 DolphinDB Python API
- Python API Version: 1.30.21.1
- For instruction on installing and using Python API, see Python API Reference Guide.
8. Appendices
- Script for importing data:
- Script for creating databases and tables:
- API code for replaying data:
- Performance Testing: C++ Test Code