ridge
语法
ridge(ds, yColName, xColNames, [alpha=1.0], [intercept=true],
[normalize=false], [maxIter=1000], [tolerance=0.0001], [solver='svd'],
[swColName])
详情
进行 ridge 回归估计。
最小化以下目标函数:
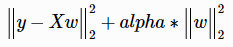
参数
ds 是一个内存表或通常用 sqlDS 函数生成的数据源。
yColName 是字符串,表示数据源中因变量的列名。
xColNames 是字符串标量或向量,表示数据源中自变量的列名。
alpha 是浮点数,表示乘以 L1 范数惩罚项的系数。默认值是1.0。
intercept 是布尔值,表示是否回归模型包含截距。默认值为true。
normalize 是布尔值。默认值为 false。若设为 true,则所有自变量均会进行如下标准化:减去平均值,然后除以 L2 范数。若 intercept 为 false,该参数会被忽略。
maxIter 是正整数,表示最大迭代次数。默认值是1000。
tolerance 是浮点数,表示迭代中止的边界差值。默认值是0.0001。
solver 是字符串,表示回归算法模型。可取值 'svd' 或 'cholesky'。若ds为多个数据源,则 solver 必须为 'cholesky'。
swColName 字符串,表示列名,必须为 ds 中存在的列名。如果未指定该参数,则所有样本的权重都默认为1;如果指定该参数,则将指定的列作为样本的权重。
例子
y = [225.720746,-76.195841,63.089878,139.44561,-65.548346,2.037451,22.403987,-0.678415,37.884102,37.308288]
x0 = [2.240893,-0.854096,0.400157,1.454274,-0.977278,-0.205158,0.121675,-0.151357,0.333674,0.410599]
x1 = [0.978738,0.313068,1.764052,0.144044,1.867558,1.494079,0.761038,0.950088,0.443863,-0.103219]
t = table(y, x0, x1);
ridge(t, `y, `x0`x1);如果 t 是一个 DFS 表,则应使用数据源作为输入:
ridge(sqlDS(<select * from t>), `y, `x0`x1);