10 Commonly Overlooked Details in Data Importing
Whether you're importing from local disk files (such as .csv or .txt) or using plugins to import data from external sources, overlooking certain operational details can lead to failed imports or incorrect results.
This article outlines the 10 most commonly overlooked pitfalls during data import in DolphinDB—ranging from data formats and type handling, import speed, preprocessing, connection issues, and concurrent write-write conflicts—along with practical solutions for each.
1. Handle Numeric Column Names
loadText and ploadText are the most commonly used
functions for importing text files in DolphinDB. However, DolphinDB requires that
all column names start with a letter. When headers in your file start with digits,
these functions behave as follows:
- If containHeader is not specified:
The first row is treated as data. If any value in that row starts with a digit, DolphinDB assigns default column names such as col0, col1, etc. In this case, the first row of the file will be imported as the first row of data in the table.
- If set
containHeader = true:The first row is treated as the header. If any column name starts with a digit, DolphinDB automatically prefixes it with “c”. For example, "123Name" becomes "c123Name".
Neglecting this behavior may result in unexpected column names in the imported data.
For example, when importing the following colName.csv with column names starting with numbers:
| id | name | totalSale | 2023Q1 | 2023Q2 | 2023Q3 |
|---|---|---|---|---|---|
| 1 | shirt | 8000 | 2000 | 3000 | 3000 |
| 2 | skirt | 10000 | 2000 | 5000 | 3000 |
| 3 | hat | 2000 | 1000 | 300 | 700 |
1.1. Incorrect Operation
When containHeader is not specified, DolphinDB defaults to assigning column names as col0, col1, …, etc.
For instance, when executing loadText("/xxx/colName.csv") to
import the data, the result is as follows:
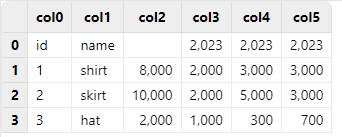
Note that since “col0” and “col1” contain discrete values, DolphinDB defaults to parsing them as SYMBOL type. In contrast, columns “col2” through “col5” contain integer data, which is parsed as INT type by default. As a result, the original column name “totalSale” cannot be correctly mapped in “col2”, leaving the first row empty. Furthermore, the column names in “col3” through “col5” only retain the numeric portion that can be parsed (e.g., 2023).
1.2. Correct Operation
When containHeader = true is specified, DolphinDB prefixes a "c"
to column names that start with a number, ensuring valid column names.
For example, when executing loadText("/xxx/colName.csv", containHeader =
true) to import the data, the result is as follows:
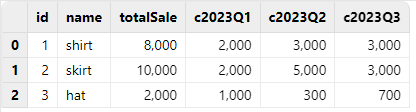
By specifying containHeader = true, column names starting with a
number are correctly handled by simply adding a "c" prefix, which is the
recommended approach. Therefore, when importing a text file using
loadText, if the header contains column names starting with
a number, containHeader = true should always be specified.
2. Infer Data Types Automatically
The loadText, ploadText, and
loadTextEx functions all support the schema parameter,
which specifies the data types for each column by passing a table object. If the
schema parameter is not specified, DolphinDB infers the data type for
each column based on a random sample of the rows. However, this approach may not
always accurately determine the correct data types for all columns. To address this,
DolphinDB provides the extractTextSchema function, which allows
users to view the data types inferred by DolphinDB. It is recommended to use
extractTextSchema to review the automatic detection results
before importing data. If the inferred types do not meet expectations, the data
types can be adjusted, and the modified table can be passed as the schema
parameter to the loadText, ploadText, or
loadTextEx functions for data import.
For example, when importing the following type.csv file:
| id | ticker | price |
|---|---|---|
| 1 | 300001 | 25.80 |
| 2 | 300002 | 6.85 |
| 3 | 300003 | 7.19 |
2.1. Incorrect Operation
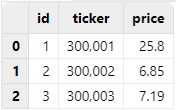
Executing loadText("/xxx/type.csv") results in the
following:
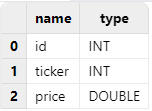
By executing extractTextSchema("/xxx/type.csv"), it can be
observed that the “ticker” column is incorrectly inferred as INT type, which
does not meet expectations:
2.2. Correct Operation
You can use the extractTextSchema function to first view the
inferred results, then specify the “ticker” column's type as SYMBOL. The
modified result can then be passed as the schema parameter to the
loadText function for importing, which will yield the
expected outcome.
schema = extractTextSchema("/xxx/type.csv")
update schema set type =`SYMBOL where name = "ticker"
loadText("/xxx/type.csv", schema=schema)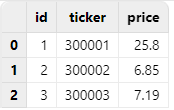
3. Import Dates and Times Data
When using the loadText function to import data that contains dates
and times without explicitly specifying schema, the system will automatically
infer the column types based on the data. The inference rules are as follows:
- Data with delimiters:
- Data containing "-", "/", or "." will be converted to the DATE type (e.g., "2023-04-10", "23.04.10").
- Data containing ":" will be converted to the SECOND type (e.g., "12:34:56").
- Numeric strings without delimiters:
- Data in the format of “yyMMdd” that meets 0 ≤ yy ≤ 99, 0 ≤ MM ≤ 12, 1 ≤ dd ≤ 31 will be preferentially parsed as DATE.
- Data in the format of “yyyyMMdd” pattern that meets 1900 ≤ yyyy ≤ 2100, 0 ≤ MM ≤ 12, 1 ≤ dd ≤ 31 will also be preferentially parsed as DATE.
For example, when importing the following notdate.csv file:
| id | ticker | price |
|---|---|---|
| 1 | 111011 | 133.950 |
| 2 | 111012 | 125.145 |
| 3 | 111013 | 113.240 |
3.1. Incorrect Operation
Executing loadText("/xxx/notdate.csv") results in the
following:
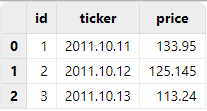
3.2. Correct Operation
Explicitly specify the column type (e.g., SYMBOL) via the schema parameter during import to ensure correct parsing.
Example:
schema = table(`id`ticker`price as name, `INT`SYMBOL`DOUBLE as type)
loadText("/xxx/notdate.csv", schema = schema)Result:
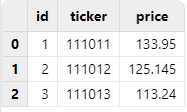
4. Improve Import Performance with loadTextEx
In many practical scenarios, data files are imported directly into the distributed
database without intermediate in-memory processing. To support this, DolphinDB
provides the loadTextEx function, which writes data to the database
directly, bypassing in-memory tables. This streamlines the workflow and improves
performance.
For example, consider importing the following data.csv file:
| ID | date | vol |
|---|---|---|
| 23 | 2023.08.08 | 34.461863990873098 |
| 27 | 2023.08.08 | 4.043174418620766 |
| 36 | 2023.08.08 | 5.356599518563599 |
| 98 | 2023.08.09 | 5.630887264851481 |
| … | … | … |
4.1. Import Files with loadText
Loading the file into memory with loadText before writing it to
the database takes 771.618 ms.
timer{
t = loadText("/xxx/data.csv")
loadTable("dfs://test_load","data").append!(t)
}
>> Time elapsed: 771.618ms4.2. Import Files with loadTextEx
In contrast, using loadTextEx to import the file directly to the
database takes only 384.097 ms.
timer{
loadTextEx(database("dfs://test_load"), "data", "date", "/xxx/data.csv", sortColumns=`id)
}
>> Time elapsed: 384.097msloadTextEx offers increasing performance benefits as the dataset
grows.
5. Preprocess Data with loadTextEx
The loadTextEx function provides a transform parameter that
enables data cleaning and preprocessing during data import. The processed data is
then written directly to the distributed database without intermediate memory
storage. This approach eliminates the need to load data into memory, streamlining
the workflow and improving performance.
For example, when importing the dataWithNULL.csv file, the “vol” column contains null values that need to be replaced with 0 before writing to the database:
| ID | date | vol |
|---|---|---|
| 52 | 2023.08.08 | 5.08143 |
| 77 | 2023.08.09 | |
| 35 | 2023.08.08 | 0.22431 |
| 99 | 2023.08.09 | |
| … | … | … |
5.1. Import Files with loadTex
Using loadText to load the file into memory, applying
nullFill! to handle null values, and then writing to the
database takes 802.23 ms.
timer{
t = loadText("/xxx/dataWithNULL.csv")
t.nullFill!(0.0)
loadTable("dfs://test_load","data").append!(t)
}
>> Time elapsed: 802.23ms5.2. Import Files with loadTextEx
In contrast, using loadTextEx with the transform
parameter to import and preprocess data in one step takes only 385.086
ms.
timer{
loadTextEx(database("dfs://test_load"), "data", "date", "/xxx/dataWithNULL.csv", transform = nullFill!{, 0.0}, sortColumns=`id)
}
>> Time elapsed: 385.086 ms6. Import Long Integer Timestamps
In many datasets, Unix timestamps are stored as long integers (LONG type), representing the number of milliseconds since January 1, 1970 (UTC).
When importing such data:
- If the type is not specified, the timestamp column is imported as LONG, with values displayed as integers.
- If the type is explicitly set to TIMESTAMP, the system fails to parse the string format correctly and imports null values instead.
Neither approach yields the expected result.
The recommended solution is to first import the column as LONG, and then manually
convert it using the timestamp function.
Below is the original structure of the sample file time.csv:
| timestamp | ticker | price |
|---|---|---|
| 1701199585108 | SH2575 | 9.05991137959063 |
| 1701101960267 | SH1869 | 9.667245978489518 |
| 1701292328832 | SH1228 | 19.817104414105415 |
| 1701186220641 | SH2471 | 3.389011020772159 |
6.1. Incorrect Operation
If the “timestamp” column is specified as TIMESTAMP during import, the result will be all null values.
schema = extractTextSchema("/xxx/time.csv")
update schema set type = "TIMESTAMP" where name = "timestamp"
loadText("/xxx/time.csv", schema=schema)Result:
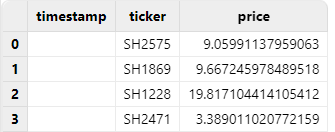
6.2. Correct Operation
The correct approach is to import the ”timestamp” column as LONG type, then use
the replaceColumn! function and timestamp
function to convert it to TIMESTAMP type, achieving the expected result.
t = loadText("/xxx/time.csv")
replaceColumn!(t, `timestamp, timestamp(exec timestamp from t))
t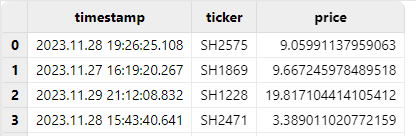
Although converting long integers to the TIMESTAMP type allows them to be displayed in a readable time format, DolphinDB parses all timestamps as UTC by default. If the original timestamps were generated based on local time, you may need to adjust for time zone differences as described in the next section.
7. Handle UTC Offsets in Long Integer Timestamps
Some databases store time data as Unix timestamps (UTC) and store the UTC offset separately.
In contrast, DolphinDB stores local timestamps without separately saving time zone information.
DolphinDB defaults to parsing all timestamps as UTC time without automatically applying UTC offsets. If the original long integer timestamps are already converted to UTC milliseconds based on a specific time zone (e.g., Beijing Time), this may result in discrepancies between the parsed and expected values upon import.
For example, in the localtime.csv file below, the “timestamp” column contains long integer values converted from the local time 2023.11.30T16:00:00.000 in Beijing Time:
| timestamp | ticker | price |
|---|---|---|
| 1701331200000 | SH3149 | 8.676103590987622 |
| 1701331200000 | SH0803 | 12.16052254475653 |
| 1701331200000 | SH2533 | 12.076009283773601 |
| 1701331200000 | SH3419 | 0.239130933769047 |
7.1. Incorrect Operation
Directly using the timestamp function to convert a LONG value to
TIMESTAMP results in UTC time, which is 8 hours behind Beijing Time.
t = loadText("/xxx/localtime.csv")
replaceColumn!(t, `timestamp, timestamp(exec timestamp from t))
tResult:
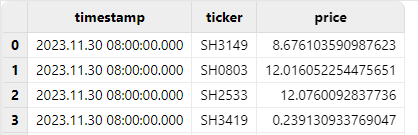
7.2. Correct Operation
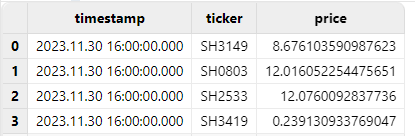
Using the time zone conversion function localtime to convert the
UTC time to local time (in this example, the local time is UTC+8).
t = loadText("/xxx/localtime.csv")
replaceColumn!(t, `timestamp, localtime(timestamp(exec timestamp from t)))
tResult:
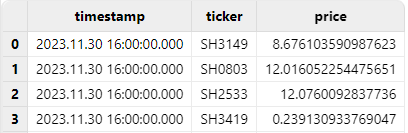
Alternatively, using the convertTZ function to convert between
two specified time zones.
t = loadText("/xxx/localtime.csv")
replaceColumn!(t, `timestamp, convertTZ(timestamp(exec timestamp from t), "UTC", "Asia/Shanghai"))
tResult:
8. Use Standard ODBC Connection Strings
DolphinDB supports importing data from external sources via the ODBC plugin. If a
connection attempt results in an error such as FATAL: password
authentication failed for user 'xxx', even when the username and
password are correct, the issue is often caused by an incorrectly configured ODBC
connection string. Refer to the Connection String Reference for the
correct format.
8.1. Incorrect Operation
In the following example, a DSN connection string is used to connect to PostgreSQL, resulting in the authentication failure mentioned above:
odbcConfig = "DSN=PIE_PGSQL;Server="+ip+";port="+port+";DATABASE="+db+";Uid="+userName+";Password="+password+";"
conn = odbc::connect(odbcConfig)
>> FATAL: password authentication failed for user "pie_dev"DolphinDB’s ODBC plugin on Linux is built on unixODBC. To verify whether a connection string is correctly configured, you can use the isql tool provided by unixODBC, which operates independently of DolphinDB. If the same DSN string results in an error with isql, the issue is likely with the connection string itself rather than with the DolphinDB plugin.
[28P01][unixODBC]FATAL: password authentication failed for user "pie_dev"
[ISQL]ERROR: Could not SQLDriverConnect8.2. Correct Operation
Refer to the Connection String Reference for the standard ODBC connection string format for PostgreSQL:

Modify the connection string according to the standard format, and the connection will succeed:
odbcConfig = "Driver={PostgreSQL};Server="+ip+";port="+port+";DATABASE="+db+";Uid="+userName+";Password="+password+";"
conn = odbc::connect(odbcConfig)9. Avoid I/O Conflicts in Data Import
When dealing with compressed data files, it is common to decompress the files before import. If the decompression and data import operations are performed concurrently on the same disk, disk I/O contention may occur, significantly impacting import performance.
For example, importing the mdl_6_28_0.csv file, which is 4.3 GB in size:
9.1. Incorrect Operation
If decompression and data import are performed simultaneously on the same disk
where DolphinDB stores its data—such as decompressing a .zip file while
using loadTextEx to import a CSV—can result in an import time
of about 1 minute and 41 seconds.
timer loadTextEx(database("dfs://test_load"), "data", "SecurityID", "/xxx/mdl_6_28_0.csv", sortColumns=`SecurityID`UpdateTime)
>> Time elapsed: 101156.78msDuring the import process, the disk read/write speed is as follows:
- Disk read speed: 16.2 KB/s
- Disk write speed: 32.6 MB/s
- Disk read volume in the past minute: 1.1 GB
- Disk write volume in the past minute: 1.1 GB
- Remaining disk space: 1.3 TB
- Total disk capacity: 2.2 TB
- Available disk space: 58.74%
Performing both decompression and import on the same disk concurrently significantly slows down the data import speed.
9.2. Correct Operation
When the disk is idle and no decompression tasks are running, directly using the
loadTextEx function to import the same file takes about 46
seconds:
timer loadTextEx(database("dfs://test_load"), "data", "SecurityID", "/xxx/mdl_6_28_0.csv", sortColumns=`SecurityID`UpdateTime)
>> Time elapsed: 46203.117msThe disk read/write speed during this process is as follows:
- Disk read speed: 174.8 MB/s
- Disk write speed: 138.7 MB/s
- Disk read volume in the past minute: 3.5 GB
- Disk write volume in the past minute: 3.5 GB
- Remaining disk space: 1.3 TB
- Total disk capacity: 2.2 TB
- Available disk space: 58.23%
To improve data import performance, avoid performing data extraction and import on the same disk simultaneously. Separating these tasks or using different disks for each can reduce disk I/O contention and enhance import speed.
10. Avoid Concurrent Writes to the Same Partition
When importing data into a distributed database, concurrent writes to the same partition may occur. The behavior depends on the atomic parameter specified during database creation:
- atomic='TRANS': Concurrent writes to the same partition are not allowed. If a transaction attempts to write to multiple partitions and one of them is locked by another transaction, a write-write conflict occurs and entire transaction fails.
- atomic='CHUNK': Concurrent writes to the same partition are allowed. If a transaction encounters a locked partition, it continues writing to other available partitions and repeatedly attempts to write to the locked one for a few minutes. The writes may succeed in some partitions and fail in others. Note that repeated attempts may impact write performance.
When a write-write conflict occurs, error code S00002 is raised with the message:
<ChunkInTransaction>filepath has been owned by transaction,
indicating the partition is locked by another transaction and cannot be locked
again. Ignoring this issue could lead to data import failures.
Consider a database dfs://test_month, partitioned by month and created with atomic='TRANS'.
10.1. Incorrect Operation
For example, parallel import of CSV files into the same partition (2023.08M) is considered:
Submit the import tasks using submitJob:
filePath = "/xxx/dailyData"
for (i in files(filePath).filename){
submitJob("loadCSVTest", "load daily files to monthly db", loadTextEx, database("dfs://test_month"), "data", "date", filePath+i)
}Upon checking the task completion status, only one task succeeds, while others fail due to write-write conflicts, throwing error code S00002.

10.2. Correct Operation
To avoid write-write conflicts, import the files sequentially:
def loadDaily(filePath){
for (i in files(filePath).filename){
loadTextEx(database("dfs://test_month"), "data",`date,filePath+i,sortColumns=`ID)
}
}
path = "/xxx/dailyData/"
submitJob("loadCSVTest","load daily files to monthly db",loadDaily, path)Upon checking the task completion status, the data is successfully imported without errors.

11. Conclusion
This article highlights 10 commonly overlooked details in data import with DolphinDB, covering aspects such as data format and column name handling, data type inference, import performance optimization, data preprocessing methods, ODBC connection configuration, I/O conflict management, and concurrent write-write conflicts. Understanding and addressing these factors can significantly improve the speed and quality of data imports.