规范监控与报警的处理流程
监控告警在运维管理中具有极其重要的作用,能够在 DolphinDB 出现问题或异常时立即发出警报,使得运维团队能够在问题升级为严重故障之前及时采取行动,确保业务连续性。同时也能在故障发生第一时间快速响应并解决问题,减少系统停机的风险和停机时间。
监控告警可以帮助组织进行预防性维护。通过检测潜在问题并在其影响业务之前进行修复,可以降低故障的发生率,帮助组织更好地知悉资源利用情况、优化资源分配,从而有助于降低成本并提高效率。
设置监控规范
监控告警涉及到多方面内容,这些内容共同构成了一个全面的监控体系,以确保系统、应用程序和业务的稳定性和可用性。DolphinDB 提供集成市面主流的监控开源软件,方便用户快速搭建监控体系。详细可以参考运维手册中的监控工具的安装部署各节。参考以下监控体系内容:
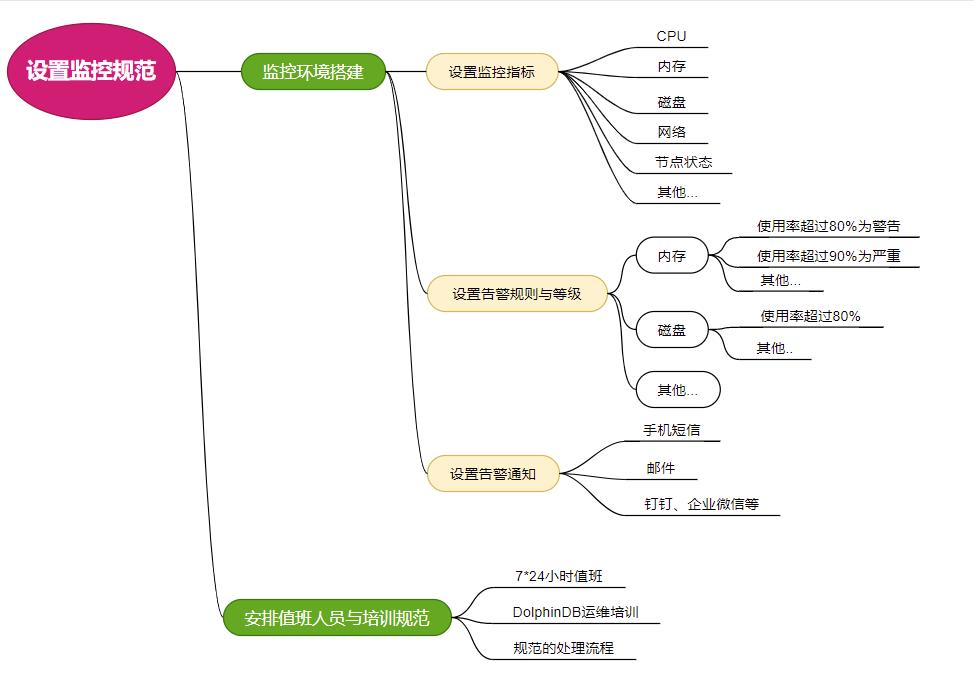
监控环境
运维手册中,监控工具的监控工具的安装部署中提供了标准的监控模版,可以对服务器资源使用情况,如 CPU 频率信息、内存占用信息、磁盘 I/O 信息、网络 IO 信息等,以及 DolphinDB 进程资源使用情况(CPU 占用情况、内存占用情况、磁盘资源使用情况等)详细监控。
对于告警规则,监控安装部署章节中提到了各种规则建立方式,对于告警指标的设置,需要根据实际运行环境或者自身运维体系实际的要求设置。如果不知道如何设置,通常以使用率超过 80% 作为警告,超过 90% 作为严重。当出现警告及以上内容时,应及时处理。
告警通知建议多方式,通常至少有2种方式,常见的组合是:短信和邮件通知。也可以设置钉钉、企业微信等即时通讯软件的通知,参考 设置邮件告警与预警
人员安排
DolphinDB 数据库是基础软件,业务人员随时都有可能依赖数据库来支持其写入、查询、计算等关键业务。数据库的停机或性能下降可能导致业务中断甚至于数据丢失等严重问题。因此建议使用者对 DolphinDB 数据库进行7*24小时实时监控,运维人员应当在问题发生第一时刻及时介入并处理。
运维手册中提供了对于各类型问题的处理方案和步骤,建议在日常对相关运维操作人员进行技能培训,并在发生问题时按照运维手册及时正确的处理。
告警处理流程
运维人员在处理告警时,应当严格按照处理规范处理相关问题。如下处理规范流程可供参考:
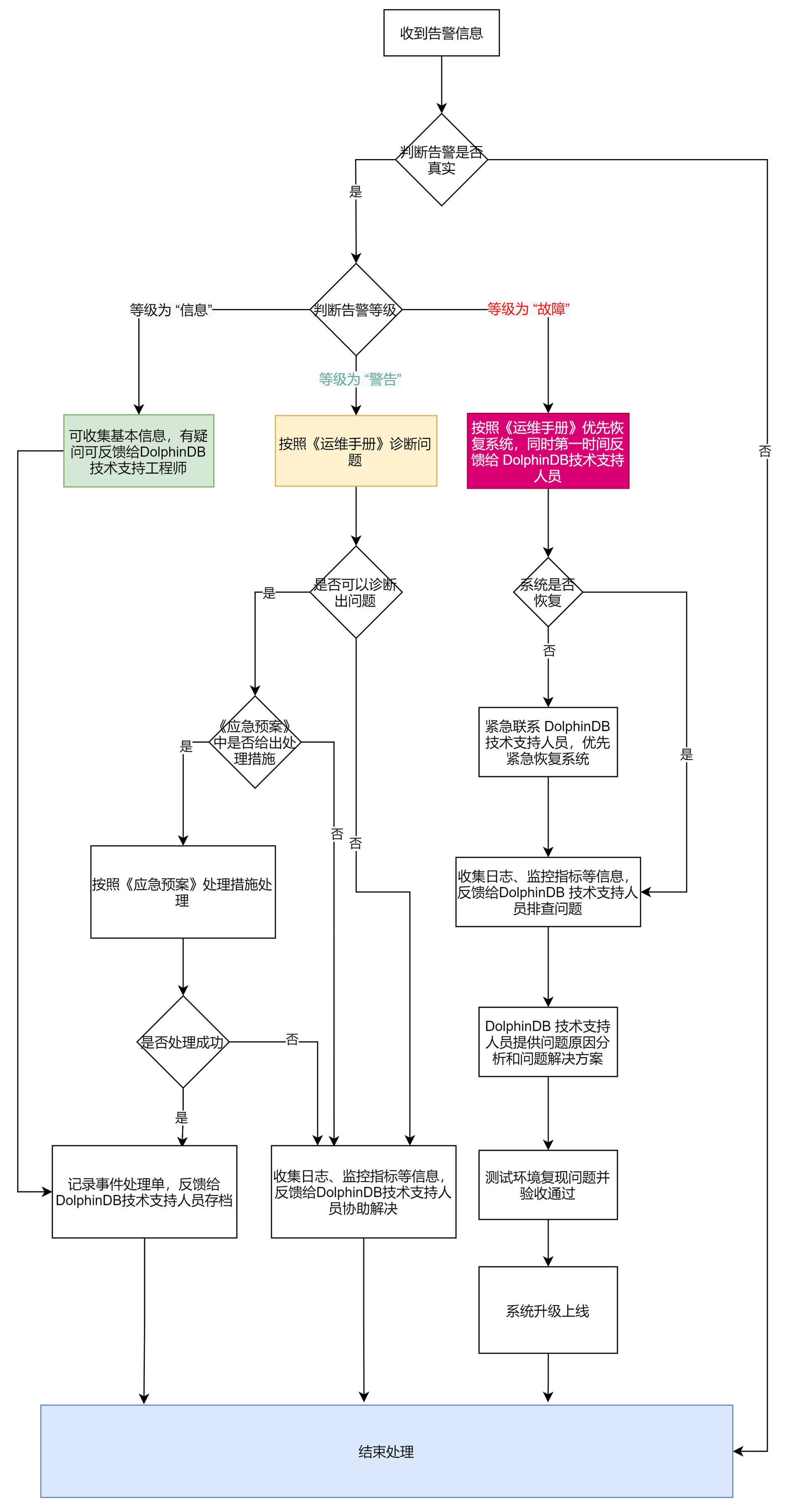
当运维人员接收到告警时,应遵循以下处理原则:
- 运维团队的成员应立即查看告警信息,并确认问题是否真实存在。
- 一旦确认问题存在,团队应迅速进行问题诊断,确定问题的原因和影响范围。
- 诊断后,运维团队需要采取适当的措施来解决问题。
- 首要任务是尽快恢复系统的运行,这里可以参照应急处理部分内容。
- 对于严重故障,应在处理故障的同时通知 DolphinDB 的技术支持人员。
- 如果无法恢复系统,可联系 DolphinDB 的技术支持人员协助恢复。
- 解决问题后,团队需要继续监控系统,确保问题不再发生,并验证解决方案是否有效。
- 每次告警事件都应该有相应的记录和报告,并将问题的相应信息反馈给 DolphinDB 的技术支持人员。
- 对于严重故障,DolphinDB 的技术支持人员会提供对应的问题分析和解决方案。
- 测试人员在测试环境确认解决方案有效并上线后,故障才可以关闭。
- 团队成员需要定期接受培训,以确保他们了解如何正确处理 DolphinDB 各种类型的告警。