写入数据
本文介绍如何通过 DolphinDB C++ API 将数据高效地写入 DolphinDB,涵盖场景介绍、原理简述、场景实践三个部分。
场景介绍
目前大数据技术已广泛应用到金融、物联网等行业,而海量数据的写入是大数据处理和分析的基础。在实际应用中,数据的产生方式和采集途径多种多样,DolphinDB 作为轻量级的大数据平台,提供多种数据写入方式,用户可以在不同应用场景下选择最合适的方式进行数据写入。
以工业物联网场景为例,设备数据的写入场景通常可分为两类。
-
多设备数据分散写入。
如某厂区有100 台设备,每台设备通过独立的传输链路将数据一条条发送到 API 端,再统一通过 API 端写入到 DolphinDB。
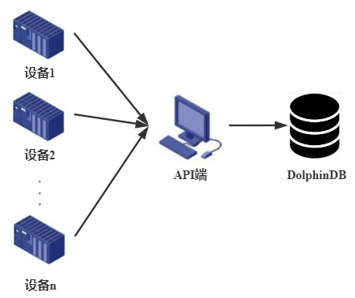
Figure 1. 多设备数据分散写入 -
设备数据汇总后再写入 API。
如某厂区有100 台设备,用采集服务(如 Kafka)将设备数据进行汇总,再统一通过 API 写入 DolphinDB。
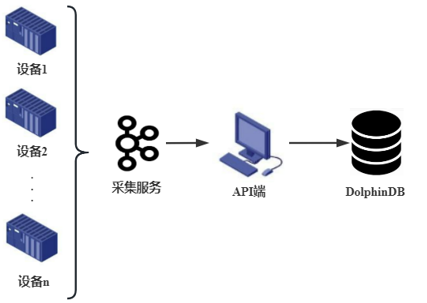
Figure 2. 设备数据汇总写入
针对以上场景,DolphinDB C++ API 提供了多种写入方法,以实现不同来源数据的高效写入:
| 设备场景 | 写入 DolphinDB 表的类型 | 调用 DolphinDB 函数 | 实现方式 |
|---|---|---|---|
| 多设备数据一条条分散写入 | ALL | MTW(MultithreadedTableWriter) | 缓冲行数据后并行写入 |
| 设备数据汇总写入 | ALL | MTW(MultithreadedTableWriter) | 将合并的行数据并行写入 |
| 设备数据汇总写入 | ALL | AFTA(AutoFitTableAppender)/ AFTU (AuoFitTableUpsert) | 单线程按列批量写入 |
| 设备数据汇总写入 | 内存表 | tableInsert | 单表写入 |
| 设备数据汇总写入 | 分布式表 | PTA(PartitionedTableAppender) | 多线程按列批量写入 |
MTW 的写入方式可以适配多种写入场景,推荐首次接触 DolphinDB 的用户使用 MTW 方法。tableInsert 方法可以将汇总数据简单快速地写入内存表。而对于分布式表,C++ API 提供了保障并行写入的 PTA 方法,以及更简单易用,能自动转换写入数据字段类型的 AFTA/AFTU 方法。
原理简述
传统的开发人员通常对关系型数据库的行式存储(Row-Based)比较熟悉,数据按单行或多行的方式提交并写入,这种写入方式很容易理解,但是基于行式存储的数据库实际上并不是为大数据处理而设计的,海量数据的写入很容易遇到性能瓶颈。
DolphinDB 采用列式存储(Column-Based),在内存中维护一个 Cache Engine,当数据写入文件时,并不是直接写入到磁盘,而是先写入操作系统的缓冲页面中,再批量写入磁盘。为了确保写入数据不会在内存中丢失, DolphinDB 使用 WAL(Write Ahead Logging)的机制。
以一个 5 列(字段)的数据表为例,写入100万行的数据时,行式存储按行方式提交并写入,需要执行 100 万次的文件写入操作;而列式存储对单列进行写入,可以按列一次性提交 100 万个值,最少仅需 5 次文件操作就能完成数据写入。两种写入方式在海量数据的处理方面性能差异巨大。
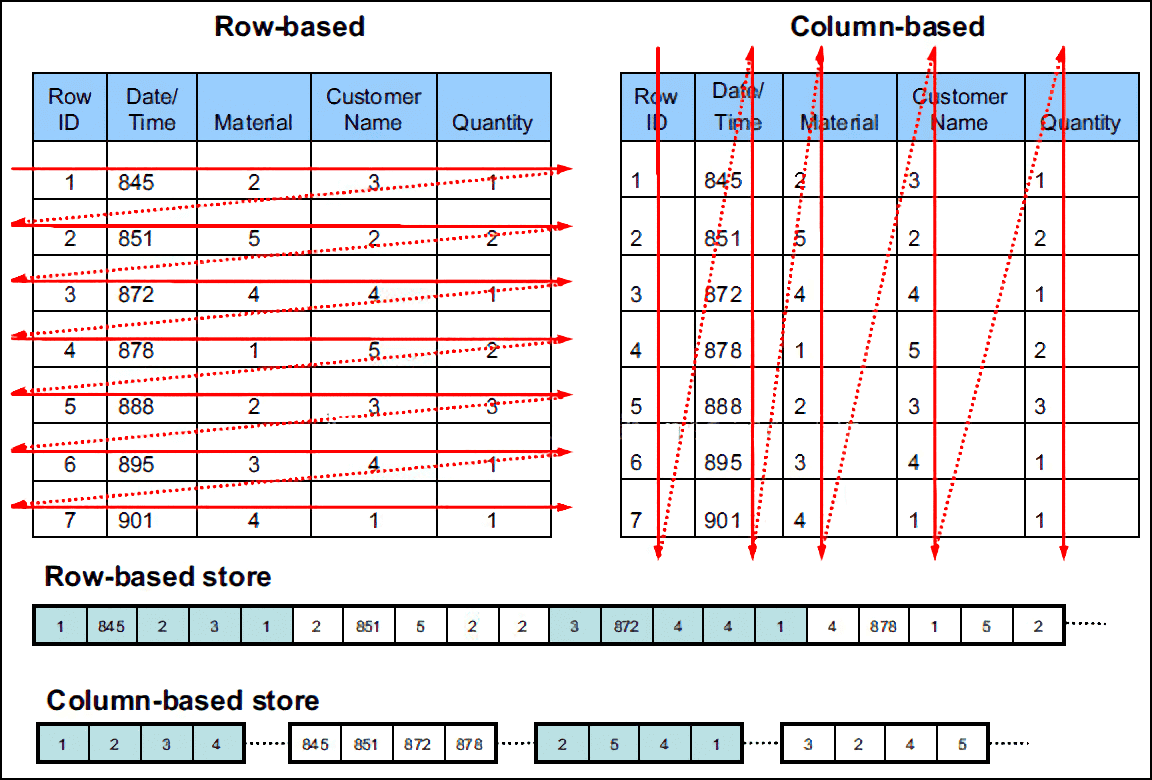
通常我们在为大数据应用场景规划写入方式前,需要理解以上列式存储的写入方式。按列批量写入能最大化发挥列式存储的优势,而当实际场景下多个设备写入数据较为分散时,可以选择有数据缓冲的 API 方法如 MTW,以获得最佳写入性能。
DolphinDB C++ API 支持多种数据写入方法,涵盖多样化的写入场景需求,主要特点如下:
| 写入方式 | 特点 |
|---|---|
| MTW |
|
| tableInsert |
|
| PTA |
|
| AFTA |
|
| AFTU | AFTA 更新写的版本 |
| BatchTableWriter CAUTION: 已停止维护,不推荐使用 |
|
- MTW 支持高效按行写入,通过内置数据缓冲队列,MTW 将数据统一发送到 DolphinDB ,可以保证单条数据的写入效率,适用于多设备一条条分散写入场景。当性能要求不高时,也可用于第三方平台汇总数据后批量写入 API 的场景。
- MTW 是对 BatchTableWriter(旧版本)的升级,二者均支持数据分散地从第三方平台传输到客户端的场景。MTW 的默认功能和 BatchTableWriter 一致,但支持多线程的并发写入。目前 BatchTableWriter 方式已经完全被 MTW 替代,仅因为兼容性而保留。
- tableInsert 使用简单高效,可以支持数据汇总写入场景,若写入的 DolphinDB 表为内存表,可以选择 tableInsert 或者 PTA;但 tableInsert 没有分区写入保障机制,在开启事务机制的情况下,不建议写入分布式表。
- PTA 能够自动按分区实现同步并行写入,适用于数据汇总写入场景。按列并行写入的机制确保了 PTA 方式在批量写入场景下拥有性能优势。
- AFTA 能够自动将 C++ 字段类型转换为 DolphinDB 字段类型完成写入,使用上较 PTA 更为简单,同样适合数据汇总写入场景。PTA 的写入速度要好于 AFTA,在对写入效率有要求且仅进行追加写的情况下,建议优先考虑 PTA。
- AFTU 是 AFTA 的更新写版本,更适合于重复数据存在的场景,读取新数据不存在重复时直接插入,存在重复时更新。针对数据写入是否需要更新,即当写入的数据在数据库中已有相同的主键或者相同的指定字段时,选择更新该条旧数据或者直接插入新数据,C++ API 给出了不同的写入方式。其中,MTW 内部分别实现了更新写和追加写,以 mode 参数的形式提供选择;而 PTA 仅提供了追加写的方式。
MTW,PTA,AFTA,AFTU 四种方法涵盖了绝大多数写入场景,其底层实现均调用了 tableInsert 或
upsert! (关于 tableInsert 的更多介绍请参考 tableInsert)。
场景实践
以下场景案例展示了使用 DolphinDB C++ API 实现数据写入的流程:
某设备实验平台有 100 台设备,单台设备有 1000 个测点,实验平台需要采集设备的测点信息从而评估设备的使用情况。
实验平台要求测点信息按单值模型存储,每台设备每隔 5 分钟对所有 1000 个测点进行数据采集,汇总所有设备的数据后通过消息中间件统一传输到 API 端。实验平台要求支持对数据的批量写入,同时保证数据类型的一致性,不需要数据类型自动转换;若客户端意外崩溃,重启后 API 可重新接受数据。这种场景下采用 MTW 方法将实时数据写入数据库,其流程图如下:
数据集:
- 记录描述:100台设备,每台1000个测点,采集频率5分钟1次,采集持续10天
- 记录行数:2.6亿行
- 磁盘占用:1116 MB
- 字段数量:6
- 字段样式:
- ts:数采时间
- deviceCode:设备编号
- logicalPostionId:逻辑位置ID
- physicalPostionId:物理位置ID
- propertyCode:属性测点编码
- propertyValue:测点值(累计产量)
准备工作:
首先要在 server 端创建分布式数据库 db_demo、分区表 collect:
// 建立分布式数据库及分区表
dbname="dfs://db_demo"
tablename="collect"
cols_info=`ts`deviceCdoe`logicalPostionId`physicalPostionId`propertyCode`propertyValue
cols_type=[DATETIME,SYMBOL,SYMBOL,SYMBOL,SYMBOL,INT]
t=table(1:0,cols_info,cols_type)
db=database(dbname,VALUE,[2022.11.01],engine=`TSDB)
pt=createPartitionedTable(db,t,tablename,`ts,,`deviceCdoe`ts)然后创建一张流数据表 streamtable,使用 MTW 方式将数据写入这张流表,然后订阅流表,数据将从流表流向分区表
collect:
// 建立流表
def saveToDFS(mutable dfstable, msg): dfstable.append!(msg)
share streamTable(1:0, cols_info, cols_type) as streamtable;
subscribeTable(tableName="streamtable", actionName="savetodfs", offset=0, handler=saveToDFS{pt}, msgAsTable=true, batchSize=1000, throttle=1)也可直接在 C++ 代码中使用 conn.run(script) 的方式运行此段代码。
接口调用:
创建一个 MTW 对象,订阅流表
// 建立writer对象
MultithreadedTableWriter writer(
"183.136.170.167", 9900, "admin","123456","","streamtable",NULL,false,NULL,1000,1,5,"deviceid", &compress);
MultithreadedTableWriter::Status status; // 保存 writer 状态这里需要说明的是,本文着重介绍 API 的写入,通过模拟来展示从第三方平台采集数据到 API 端写入这一过程。此外,本场景在 API 端使用单线程写入数据,用户可根据实际场景使用多线程提高 API 端写入效率,完整代码见附件 API_mtw.cpp。
// 模拟接受批量数据,创建单线程写入数据
// bt 模拟接收消息中间件发送的数据,按设备(每台设备1000条数据)遍历采集数据
for(int i=0;i < (bt->rows())/1000;i++){
system_clock::duration begin = system_clock::now().time_since_epoch();
milliseconds milbegin = duration_cast<milliseconds>(begin);
// 每台数据共1000个测点,写入1000行
for(int j=i*1000;j<(i+1)*1000;j++){
ErrorCodeInfo pErrorInfo;
// 模拟对单条数据6个字段的写入
writer.insert(pErrorInfo,
datas[i*6+0], datas[i*6+1], datas[i*6+2], datas[i*6+3], datas[i*6+4], datas[i*6+5]
)
}
system_clock::duration end = system_clock::now().time_since_epoch();
milliseconds milend = duration_cast<milliseconds>(end);
if((milend.count()-milbegin.count())<5000){
// 控制模拟写入的频率
sleep_for(std::chrono::milliseconds(5000-(milend.count()-milbegin.count())));
}
}若后台线程发生错误,MTW 可能退出后未将数据全部写入服务器(包括导致后台线程错误的那一批数据,这批数据可能已经写入服务器也可能未写入服务器)
// 检查写入完成后 MTW 状态
writer.getStatus(status);该情况下首先获取未完成写入的数据
// 获取未写入的数据
std::vector<std::vector<ConstantSP>*> unwrittenData;
writer.getUnwrittenData(unwrittenData);
cout << "Unwritten data length " << unwrittenData.size() << endl;重新写入上述数据
// 重新写入这些数据,原有的 MTW 因为异常退出已经不能用了,需要创建新的 MTW
MultithreadedTableWriter newWriter("192.168.0.61", 8848, "admin", "123456", "dfs://test_MultithreadedTableWriter", "collect", NULL,false,NULL,10000,1,10,"deviceid", &compress);
ErrorCodeInfo errorInfo;
// 插入获取到的未写入数据
if (newWriter.insertUnwrittenData(unwrittenData, errorInfo)) {
// 等待写入完成后检查状态
newWriter.waitForThreadCompletion();
newWriter.getStatus(status);
if (status.hasError()) {
cout << "error in write again: " << status.errorInfo << endl;
}
}
else {
cout << "error in write again: " << errorInfo.errorInfo << endl;
}