基于函数的元编程应用
DolphinDB 支持使用元编程来动态创建表达式,包括函数调用的表达式与 SQL 查询表达式等。DolphinDB 中有3种方法实现元编程,本文将展开说明如何在 DolphinDB 中基于函数编写元代码。如需了解宏变量元编程方法,请参考基于宏变量的元编程应用。
1. 基于函数生成元代码
基于函数的元编程实现,是指通过内置元编程函数的组合调用生成元代码。以 select 查询语句为例,一个 select 语句通常可以拆分为以下几个部分:select 查询主体,表对象,分组字段,排序字段,过滤条件,返回记录数约束等(参考下图标红部分)。

为了适用于各种 SQL 语句的生成,DolphinDB 设计了用于 SQL 语句的组装的函数 sql(select 语句), sqlUpdate(update 语句), sqlDelete(delete 语句),或者也可以通过 parseExpr + SQL 字符串生成 SQL 元代码。
以 sql 函数为例,其语法为:
sql(select, from, [where], [groupBy], [groupFlag], [csort], [ascSort], [having], [orderBy], [ascOrder], [limit], [hint], [exec=false])sql 函数的每个参数都对应 SQL 的一个子句,通过变量传入即可动态生成对应的 SQL 元代码。
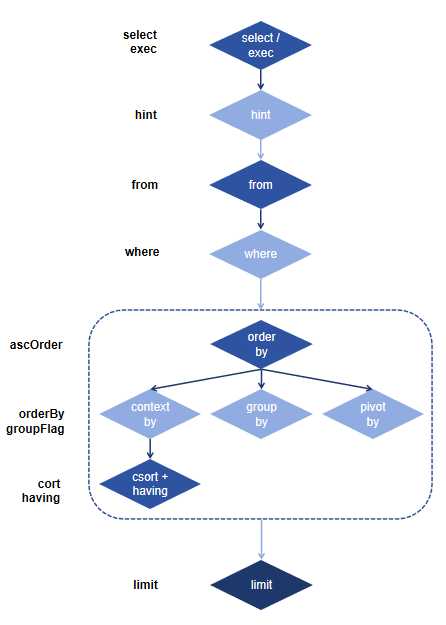
下面将详细介绍在 DolphinDB 中如何使用函数生成元代码。
expr函数根据输入的对象、运算符或其他元代码生成元代码。例如:
a=6
expr(a,+,1);
< 6 + 1 >parseExpr函数把字符串转换为元代码。例如:
t=table(1 2 3 4 as id, 5 6 7 8 as value, `IBM`MSFT`IBM`GOOG as name)
parseExpr("select * from t where name='IBM'").eval();
id value name
-- ----- ----
1 5 IBM
3 7 IBMbinaryExpr生成一个二元运算的元代码。例如:
binaryExpr(1, 1, +).eval()
2
binaryExpr(1 2.2 3, 1 2 3, *).eval()
[1 4.4 9]
binaryExpr(`id`st`nm, `fff, +).eval()
["idfff","stfff","nmfff"]unifiedExpr生成一个多元运算表达式的元代码。例如:
t=table(1..3 as price1, 4..6 as price2, 5..7 as price3)
a=sqlColAlias(unifiedExpr((sqlCol("price1"), sqlCol("price2"), sqlCol("price3")), take(add, 2)))
sql(select=(sqlCol(`price1),sqlCol(`price2),sqlCol(`price3),a), from=t)
< select price1,price2,price3,price1 + price2 + price3 as price1_add from tc0ccbd6a00000000 >partial函数固定一个函数的部分参数,产生一个参数较少的函数。例如:
partial(add,1)(2);
3
def f(a,b):a pow b
g=partial(f, 2)
g(3);
8sqlCol,sqlColAlias和sql函数用于动态生成 SQL 表达式。sqlCol函数将列名转换为可带有计算内容的表达式,sqlColAlias常用于生成计算列的元代码,sql函数可以动态地生成SQL语句。
symbol = take(`GE,6) join take(`MSFT,6) join take(`F,6)
date=take(take(2017.01.03,2) join take(2017.01.04,4), 18)
price=31.82 31.69 31.92 31.8 31.75 31.76 63.12 62.58 63.12 62.77 61.86 62.3 12.46 12.59 13.24 13.41 13.36 13.17
volume=2300 3500 3700 2100 1200 4600 1800 3800 6400 4200 2300 6800 4200 5600 8900 2300 6300 9600
t1 = table(symbol, date, price, volume);
x=5000
whereConditions = [<symbol=`MSFT>,<volume>x>]
havingCondition = <sum(volume)>200>;
sql(sqlCol("*"), t1);
< select * from t1 >
sql(sqlCol("*"), t1, whereConditions);
< select * from t1 where symbol == "MSFT",volume > x >
sql(select=sqlColAlias(<avg(price)>), from=t1, where=whereConditions, groupBy=sqlCol(`date));
< select avg(price) as avg_price from t1 where symbol == "MSFT",volume > x group by date >
sql(select=sqlColAlias(<avg(price)>), from=t1, groupBy=[sqlCol(`date),sqlCol(`symbol)]);
< select avg(price) as avg_price from t1 group by date,symbol >
sql(select=(sqlCol(`symbol),sqlCol(`date),sqlColAlias(<cumsum(volume)>, `cumVol)), from=t1, groupBy=sqlCol(`date`symbol), groupFlag=0);
< select symbol,date,cumsum(volume) as cumVol from t1 context by date,symbol >
sql(select=(sqlCol(`symbol),sqlCol(`date),sqlColAlias(<cumsum(volume)>, `cumVol)), from=t1, where=whereConditions, groupBy=sqlCol(`date), groupFlag=0);
< select symbol,date,cumsum(volume) as cumVol from t1 where symbol == "MSFT",volume > x context by date >
sql(select=(sqlCol(`symbol),sqlCol(`date),sqlColAlias(<cumsum(volume)>, `cumVol)), from=t1, where=whereConditions, groupBy=sqlCol(`date), groupFlag=0, csort=sqlCol(`volume), ascSort=0);
< select symbol,date,cumsum(volume) as cumVol from t1 where symbol == "MSFT",volume > x context by date csort volume desc >
sql(select=(sqlCol(`symbol),sqlCol(`date),sqlColAlias(<cumsum(volume)>, `cumVol)), from=t1, where=whereConditions, groupBy=sqlCol(`date), groupFlag=0, having=havingCondition);
< select symbol,date,cumsum(volume) as cumVol from t1 where symbol == "MSFT",volume > x context by date having sum(volume) > 200 >
sql(select=sqlCol("*"), from=t1, where=whereConditions, orderBy=sqlCol(`date), ascOrder=0);
< select * from t1 where symbol == "MSFT",volume > x order by date desc >
sql(select=sqlCol("*"), from=t1, limit=1);
< select top 1 * from t1 >
sql(select=sqlCol("*"), from=t1, groupBy=sqlCol(`symbol), groupFlag=0, limit=1);
< select top 1 * from t1 context by symbol >eval函数执行元代码。例如:
a = <1 + 2 * 3>
eval(a);
7
sql(sqlColAlias(<avg(vol)>,"avg_vol"),t1,,sqlCol(["sym","date"])).eval();
sym date avg_vol
---- ---------- -------
F 2017.01.03 4900
F 2017.01.04 6775
GE 2017.01.03 2900
GE 2017.01.04 2900
MSFT 2017.01.03 8300
MSFT 2017.01.04 4925
//这里使用的t1是上一个例子中的t1sqlUpdate函数动态生成 SQL update 语句的元代码。执行生成的元代码需要配合使用eval函数。例如:
t1=table(`A`A`B`B as symbol, 2021.04.15 2021.04.16 2021.04.15 2021.04.16 as date, 12 13 21 22 as price)
t2=table(`A`A`B`B as symbol, 2021.04.15 2021.04.16 2021.04.15 2021.04.16 as date, 10 20 30 40 as volume);
sqlUpdate(t1, <price*2 as updatedPrice>).eval()
t1;| symbol | date | price | updatedPrice |
|---|---|---|---|
| A | 2021.04.15 | 12 | 24 |
| A | 2021.04.16 | 13 | 26 |
| B | 2021.04.15 | 21 | 42 |
| B | 2021.04.16 | 22 | 44 |
sqlDelete函数动态生成 SQL delete 语句的元代码。执行生成的元代码需要配合使用eval函数。例如:
t1=table(`A`B`C as symbol, 10 20 30 as x)
sqlDelete(t1, <symbol=`C>).eval()
t1;| symbol | x |
|---|---|
| A | 10 |
| B | 20 |
makeCall函数和makeUnifiedCall根据指定的函数与参数生成元代码。
例如,查询表 t1 时,把 date 列输出为字符串,并以类似于03/01/2017的形式显示:
sql([sqlColAlias(makeCall(temporalFormat,sqlCol(`date),"dd/MM/yyyy"),"date"),sqlCol(`sym),sqlCol(`PRC),sqlCol(`vol)],t1)
< select temporalFormat(date, "dd/MM/yyyy") as date,sym,PRC,vol from t1 >makeUnifiedCall(matrix, (1 2 3, 4 5 6));
< matrix([1,2,3], [4,5,6]) >在了解了相关的生成元代码的函数后,我们利用这些函数生成第一节的图中展示的查询语句:
sel=sqlColAlias(makeUnifiedCall(cumsum, sqlCol("price")), "cum_price")
fm="t"
wre=parseExpr("time between 09:00:00 and 15:00:00")
ctxBy=sqlCol("securityID")
cs=sqlCol("time")
lim=-1
sql(select=sel, from=fm, where=wre, groupby=ctxBy, groupFlag=0, csort=cs, limit=lim)
// output:
< select cumsum(price) as cum_price from objByName("t") where time between pair(09:00:00, 15:00:00) context by securityID csort time asc limit -1 >通过以上代码,可以总结出出 sql 函数生成元代码的规则:
- 查询字段须以
sqlCol或者sqlColAlias声明。 - 对表字段计算的元代码:
- 单字段参与计算:
sqlCol函数指定 func 参数。 - 多字段参与计算:
sqlColAlias函数 搭配makeCall或者makeUnifiedCall函数。
- 单字段参与计算:
- 表对象可以是一个表变量名字符串、表变量如 t 或
loadTable返回的句柄。
具体的参数说明请参考:sql
进一步可以发现 sql 函数生成的元代码是基于一些小的元代码片段组装的,即通过一些元代码生成函数组装而成。为了进一步理解这个规则,下面介绍一下组装涉及到的相关函数及其作用:
sqlCol:支持生成单字段或多字段应用同一函数的表达式,支持指定别名;生成的表达式形如:
(1) sqlCol("col") --> <col>
(2) sqlCol(["col0","col1","col2"]) --> [<col0>, <col1>, …, <colN>]
(3) sqlCol("col", func=sum, alias="newCol") --> <sum(col) as newCol>
(4) sqlCol(["col0","col1","col2"], func=sum, alias=["newCol0","newCol1","newCol2"])
--> [<sum(col0) as newCol0>, <sum(col1) as newCol1>, <sum(col2) as newCol2>]sqlColAlias:为复杂的列字段计算元代码指定别名;makeCall,makeUnifiedCall:用于生成 <func(cols.., args…)> 的元代码表达式。expr,unifiedExpr,binaryExpr:生成多元算术表达式,例如 <a+b+c>, <a1b1+a2b2+… +an*bn>。
生成的表达式形如:
(1) sqlColAlias(sqlCol("col"), "newCol") --> <col as newCol>
(2) sqlColAlias(makeCall(sum, sqlCol("col")), "newCol")
--> <func(col) as newCol>
(3) sqlColAlias(makeCall(corr, sqlCol("col0"), sqlCol("col1")), "newCol")
--> <func(col1, col2, …, colN) as newCol>parseExpr:从字符串生成元代码,将拼接、 API 上传或脚本读取的字符串,生成可执行的脚本。例如parseExpr("select * from t")即可生成 <select * from t> 的元代码;parseExpr("where vol>1000")生成sql函数 where 参数部分的元代码等。
以一个更复杂的场景为例:基于函数生成 select 部分的元代码 < nullFill(price, quantile(price, 0.5)) as price >,其中 price 是动态传入的一个字段名:
colName=`price
sqlColAlias(makeCall(nullFill, sqlCol(colName), makeUnifiedCall(quantile, (sqlCol(colName), 0.5))), colName)2. DolphinDB 元编程应用
2.1. 更新内存表
内存表的更新、删除等操作不仅可以通过SQL语句完成,也可以通过元编程完成。
创建内存表:
n=1000000
sym=rand(`IBM`MSFT`GOOG`FB`IBM`MSFT,n)
date=rand(2018.01.02 2018.01.02 2018.01.02 2018.01.03 2018.01.03 2018.01.03,n)
price=rand(1000.0,n)
qty=rand(10000,n)
trades=table(sym,date,price,qty)2.1.1. 更新数据
例如,更新 IBM 的交易量:
trades[`qty,<sym=`IBM>]=<qty+100>
//等价于 update trades set qty=qty+100 where sym=`IBM2.1.2. 新增一个列
例如,添加一个新的列 volume,用于保存交易量:
trades[`volume]=<price*qty>
//等价于 update trades set volume=price*qty2.1.3. 删除数据
例如,删除 qty 为 0 的数据:
trades.erase!(<qty=0>)
//等价于 delete from trades where qty=02.1.4. 动态生成过滤条件并更新数据
本例使用了以下数据表:
ind1=rand(100,10)
ind2=rand(100,10)
ind3=rand(100,10)
ind4=rand(100,10)
ind5=rand(100,10)
ind6=rand(100,10)
ind7=rand(100,10)
ind8=rand(100,10)
ind9=rand(100,10)
ind10=rand(100,10)
indNum=1..10
t=table(ind1,ind2,ind3,ind4,ind5,ind6,ind7,ind8,ind9,ind10,indNum)使用以下 SQL 语句对该数据表进行更新操作:
update t set ind1=1 where indNum=1
update t set ind2=1 where indNum=2
update t set ind3=1 where indNum=3
update t set ind4=1 where indNum=4
update t set ind5=1 where indNum=5
update t set ind6=1 where indNum=6
update t set ind7=1 where indNum=7
update t set ind8=1 where indNum=8
update t set ind9=1 where indNum=9
update t set ind10=1 where indNum=10如果数据表的列数非常多,需要手工编写非常多的 SQL 语句。使用元编程可以非常简便地完成以上操作。
for(i in 1..10){
t["ind"+i,<indNum=i>]=1
}2.2. 在内置函数中使用元编程
DolphinDB 的一些内置函数的参数中需要使用元编程。
2.2.1. 窗口连接
在窗口连接(window join)中,需要为右表的窗口数据集指定一个或多个聚合函数以及这些函数运行时需要的参数。由于问题的描述和执行在两个不同的阶段,必须使用元编程以实现延后执行。
t = table(take(`ibm, 3) as sym, 10:01:01 10:01:04 10:01:07 as time, 100 101 105 as price)
q = table(take(`ibm, 8) as sym, 10:01:01+ 0..7 as time, 101 103 103 104 104 107 108 107 as ask, 98 99 102 103 103 104 106 106 as bid)
wj(t, q, -2:1, < [max(ask), min(bid), avg((bid+ask)*0.5) as avg_mid]>, `time)
sym time price max_ask min_bid avg_mid
--- -------- ----- ------- ------- -------
ibm 10:01:01 100 103 98 100.25
ibm 10:01:04 101 104 99 102.625
ibm 10:01:07 105 108 103 105.625
2.2.2. 流计算引擎
DolphinDB 提供多种流计算引擎。在使用这些流计算引擎时,需要为数据窗口中的数据指定函数或表达式以及所需参数,这些都需要使用元编程。
以时间序列引擎的应用为例:
share streamTable(1000:0, `time`sym`qty, [DATETIME, SYMBOL, INT]) as trades
output1 = table(10000:0, `time`sym`sumQty, [DATETIME, SYMBOL, INT])
agg1 = createTimeSeriesEngine(name="engine1", windowSize=60, step=60, metrics=<[sum(qty)]>, dummyTable=trades, outputTable=output1, timeColumn=`time, useSystemTime=false, keyColumn=`sym, garbageSize=50, useWindowStartTime=false)
subscribeTable(tableName="trades", actionName="tableName", offset=0, handler=append!{agg1}, msgAsTable=true)
insert into trades values(2018.10.08T01:01:01,`A,10)
insert into trades values(2018.10.08T01:01:02,`B,26)
insert into trades values(2018.10.08T01:01:10,`B,14)
insert into trades values(2018.10.08T01:01:12,`A,28)
insert into trades values(2018.10.08T01:02:10,`A,15)
insert into trades values(2018.10.08T01:02:12,`B,9)
insert into trades values(2018.10.08T01:02:30,`A,10)
insert into trades values(2018.10.08T01:04:02,`A,29)
insert into trades values(2018.10.08T01:04:04,`B,32)
insert into trades values(2018.10.08T01:04:05,`B,23)
select * from output1
time sym sumQty
------------------- --- ------
2018.10.08T01:02:00 A 38
2018.10.08T01:03:00 A 25
2018.10.08T01:02:00 B 40
2018.10.08T01:03:00 B 9 2.3. 定制报表
下例定义了一个用于生成报表的自定义函数,用户只需要输入数据表、字段名称以及字段相应的格式字符串,即可按指定格式输出报表。
def generateReport(tbl, colNames, colFormat, filter){
colCount = colNames.size()
colDefs = array(ANY, colCount)
for(i in 0:colCount){
if(colFormat[i] == "")
colDefs[i] = sqlCol(colNames[i])
else
colDefs[i] = sqlCol(colNames[i], format{,colFormat[i]})
}
return sql(colDefs, tbl, filter).eval()
}创建模拟的历史数据库:
n=31
date=2020.09.30+1..n
sym=take(`A,n) join take(`B,n)
t=table(take(date,2*n) as date, sym, 100+rand(1.0,2*n) as price, rand(1000..10000,2*n) as volume)
select * from t where date=2020.10.16 and sym=`B;
date sym price volume
---------- --- ------------------- ------
2020.10.16 B 100.324969965266063 6657为2020年10月16日的 B 生成指定格式的报表:
generateReport(t,`date`sym`price`volume,["MM/dd/yyyy","","###.00","#,###"],<date=2020.10.16 and sym=`B >);
date sym price volume
---------- --- ------ ------
10/16/2020 B 100.32 6,657以上语句等价于以下 SQL 语句:
select format(date,"MM/dd/yyyy") as date, sym, format(price,"###.00") as price, format(volume,"#,###") as volume from t where date=2020.10.16 and sym=`B2.4. 物联网应用中动态生成计算指标
在物联网的实时流计算中,数据源包含 tag, timestamp 和 value 三个字段,需要对输入的原始数据进行实时计算。由于每次收到的原始数据的 tag 数量和种类有可能不同,并且每次计算的指标也可能不同,我们无法将计算指标固定下来。这种情况下可以采用元编程的方法。定义一个配置表,将计算的指标放到该表中,可以后续增加、删除或修改计算指标。每次实时计算时,从配置表中动态地读取需要计算的指标,并把计算的结果输出到另外一个表中。
以下是示例代码。pubTable 是流数据的发布表。config 表是存储计算指标的配置表,由于计算指标有可能每次都不相同,config 表是并发版本控制表(mvccTable)。subTable 通过订阅 pubTable,对流数据进行实时计算。
t1=streamTable(1:0,`tag`value`time,[STRING,DOUBLE,DATETIME])
share t1 as pubTable
config = mvccTable(`index1`index2`index3`index4 as targetTag, ["tag1 + tag2", "sqrt(tag3)", "floor(tag4)", "abs(tag5)"] as formular)
subTable = streamTable(100:0, `targetTag`value, [STRING, FLOAT])
def calculateTag(mutable subTable,config,msg){
pmsg = select value from msg pivot by time, tag
for(row in config){
try{
insert into subTable values(row.targetTag, sql(sqlColAlias(parseExpr(row.formular), "value"), pmsg).eval().value)
}
catch(ex){print ex}
}
}
subscribeTable(,`pubTable,`calculateTag,-1,calculateTag{subTable,config},true)
//模拟写入数据
tmp = table(`tag1`tag2`tag3`tag4 as tag, 1.2 1.3 1.4 1.5 as value, take(2019.01.01T12:00:00, 4) as time)
pubTable.append!(tmp)
select * from subTable
targetTag value
--------- --------
index1 2.5
index2 1.183216
index3 1
2.5. 执行一组查询,合并查询结果
在数据分析中,有时我们需要对同一个数据集执行多个相似的查询。我们可以使用元编程动态生成 SQL 语句,以简化大量查询语句的编写。
本例使用的数据集结构如下(以第一行为例):
| mt | vn | bc | cc | stt | vt | gn | bk | sc | vas | pm | dls | dt | ts | val | vol |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 52354955 | 50982208 | 25 | 814 | 11 | 2 | 1 | 4194 | 0 | 0 | 0 | 2020.02.05 | 2020.02.05 | 153234 | 5.374 | 18600 |
需要对每天的数据都执行一组查询。为了便于理解,这里我们使用了以下4个查询。实际应用中可能会有几千个查询。
select * from t where vn=50982208,bc=25,cc=814,stt=11,vt=2, dls=2020.02.05, mt<52355979 order by mt desc limit 1
select * from t where vn=50982208,bc=25,cc=814,stt=12,vt=2, dls=2020.02.05, mt<52355979 order by mt desc limit 1
select * from t where vn=51180116,bc=25,cc=814,stt=12,vt=2, dls=2020.02.05, mt<52354979 order by mt desc limit 1
select * from t where vn=41774759,bc=1180,cc=333,stt=3,vt=116, dsl=2020.02.05, mt<52355979 order by mt desc limit 1可以观察到,这一组查询中,过滤条件包含的列和排序列都相同,部分过滤条件的值相同,并且都是取排序后的第一行记录。为此,我们编写了自定义函数 bundleQuery:
def bundleQuery(tbl, dt, dtColName, mt, mtColName, filterColValues, filterColNames){
cnt = filterColValues[0].size()
filterColCnt =filterColValues.size()
orderByCol = sqlCol(mtColName)
selCol = sqlCol("*")
filters = array(ANY, filterColCnt + 2)
filters[filterColCnt] = expr(sqlCol(dtColName), ==, dt)
filters[filterColCnt+1] = expr(sqlCol(mtColName), <, mt)
queries = array(ANY, cnt)
for(i in 0:cnt) {
for(j in 0:filterColCnt){
filters[j] = expr(sqlCol(filterColNames[j]), ==, filterColValues[j][i])
}
queries.append!(sql(select=selCol, from=tbl, where=filters, orderBy=orderByCol, ascOrder=false, limit=1))
}
return loop(eval, queries).unionAll(false)
}bundleQuery 中各个参数的含义如下:
- tbl 是数据表。
- dt 是过滤条件中日期列的值。
- dtColName 是过滤条件中日期列的名称。
- mt 是过滤条件中 mt 的值。
- mtColName 是过滤条件中 mt 列的名称。
- filterColValues 是其他过滤条件中的值,用元组表示,其中的每个向量表示在所有查询语句中的一个过滤条件的值。
- filterColNames 是其他过滤条件中的列名,用向量表示。
上面一组 SQL 语句,相当于执行以下代码:
dt = 2020.02.05
dtColName = "dls"
mt = 52355979
mtColName = "mt"
colNames = `vn`bc`cc`stt`vt
colValues = [50982208 50982208 51180116 41774759, 25 25 25 1180, 814 814 814 333, 11 12 12 3, 2 2 2 116]
bundleQuery(t, dt, dtColName, mt, mtColName, colValues, colNames)可以执行以下脚本把 bundleQuery 函数定义为函数视图。这样,在集群中的其他数据节点上或者重启系统后,无需重新定义,可以直接调用该函数。
//please login as admin first
addFunctionView(bundleQuery)3. 小结
DolphinDB 的元编程功能强大,使用简单,能够极大地提高程序开发效率。