排查节点宕机原因
在使用DolphinDB时,有时客户端会抛出异常信息:Connection refused。此时,linux操作系统上使用ps命令查看,会发现dolphindb进程不见了。本教程针对出现这种情况的各种原因进行定位分析,并给出相应解决方案。
查看节点日志排查原因
DolphinDB每个节点的运行情况会记录在相应的日志文件中。通过分析日志,能有效地掌握Dolphindb运行状况,从中发现和定位一些错误原因。当节点宕机时,非DolphinDB系统运行原因导致节点关闭的情形通常有以下三种:
- Web集群管理界面上手动关闭节点或调用
stopDataNode函数停止节点 - 操作系统kill命令杀死节点进程
- license有效期到期关机
通过查看节点在退出前是否打印了日志:MainServer shutdown进行盘查。下面假设宕机节点为datanode1,操作命令示例如下:
less datanode1.log|grep "MainServer shutdown"若命令执行结果显示如下图,推算系统退出的时间点也合理,可初步认定为系统主动退出。

下面分情况讨论进一步的排查步骤。
第一种:查看控制节点日志controller.log,判断是否为Web集群管理界面上手动关闭节点或调用stopDataNode函数停止节点,操作命令示例如下:
less controller.log|grep "has gone offline"
若日志产生的信息如上图,可判断为通过Web界面手动关闭节点或调用stopDataNode函数停止节点。
第二种:查看对应宕机节点运行日志是否含有Received signal信息,判断是否为操作系统kill命令杀死节点进程。操作命令示例如下:
less datanode1.log|grep "Received signal"
若相应时间点上有上图所示信息,则可判定为进程被kill命令杀掉。
第三种:查看节点运行日志是否打印了如下信息:The license has expired,判断是否为license到期而关机:
若出现上图信息,可以判断是license到期退出。用户需要关注license有效期日期,及时更新liense以避免出现因license到期而无法使用的问题。从1.30.11,1.20.20开始,DolphinDB支持不重启系统,在线更新license。但是,DolphinDB 1.30.11及1.20.20之前的版本因为不支持在线更新license,更新license后,需要重启数据节点,控制节点和代理节点,否则会导致数据节点退出。
注意:节点日志存放路径为:单节点模式默认在安装目录server下,文件名为dolphindb.log,集群默认在server/log目录下。若需要修改日志文件路径,只能在命令行中通过logFile配置项指定。如果集群内有节点在运行,可通过如下ps命令查看每一个节点对应的log生成位置,其中logFile参数表示日志文件的路径和名称:
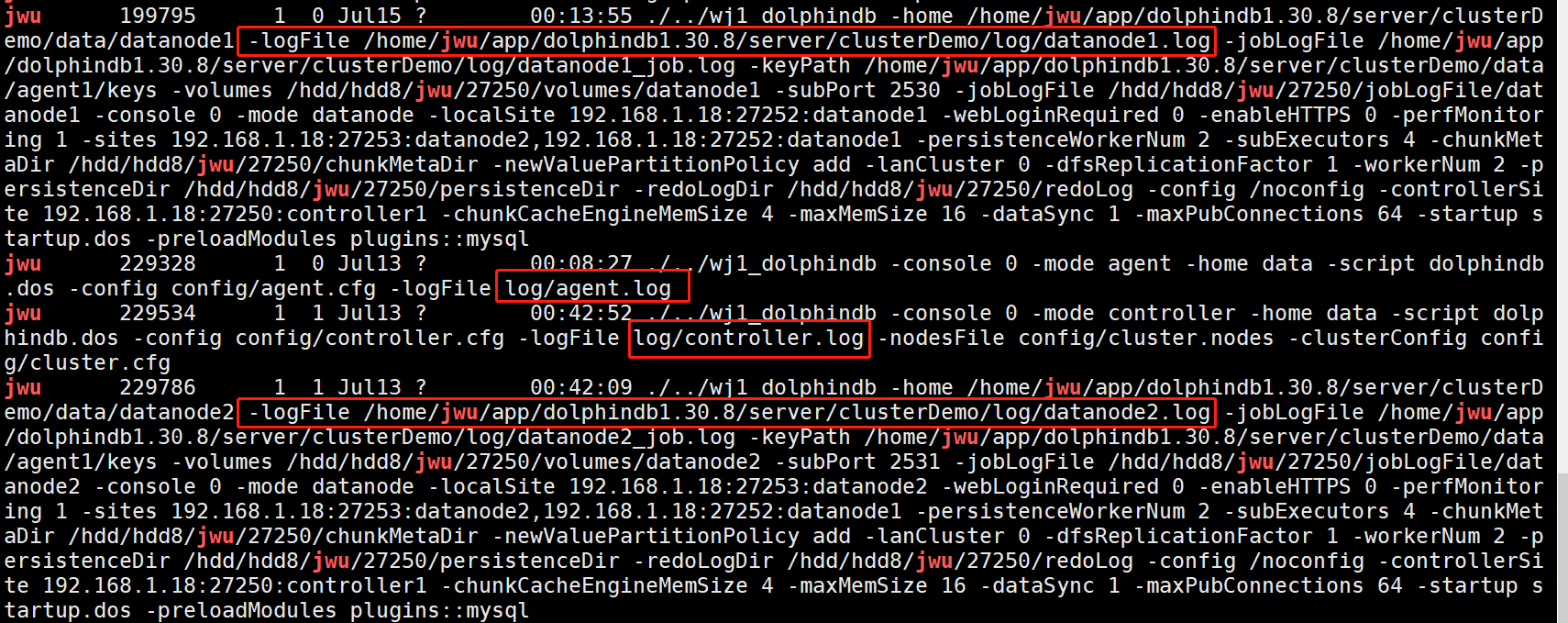
如果未查询到上述的日志信息,需进一步查看相应操作系统日志。
查看操作系统日志排查OOM killer
Linux内核有个机制叫OOM killer(Out Of Memory killer),该机制会监控那些占用内存过大,尤其是瞬间占用很大内存的进程,为防止内存耗尽而自动把该进程杀掉。排查OOM killer可用dmesg命令,示例如下:
dmesg -T|grep dolphindb
如上图,若出现了“Out of memory: Kill process”,说明DolphinDB使用的内存超过了操作系统所剩余的空闲内存,导致操作系统杀死了DolphinDB进程。解决这种问题的办法是:通过参数maxMemSize(单节点模式修改dolphindb.cfg,集群模式修改cluster.cfg)设定节点的最大内存使用量。需要合理设置该参数,设置太小会严重限制集群的性能;设置太大可能触发操作系统杀掉进程。若机器内存为16GB,并且只部署1个节点,建议将该参数设置为12GB左右。
使用上述dmesg命令显示日志信息时,若看到如下图所示的“segfault”,就是发生了段错误,即应用程序访问的内存超出了系统所给的内存空间:

可能导致段错误的原因有:
- DolphinDB访问系统数据区,最常见的就是操作0x00地址的指针
- 内存越界(数组越界,变量类型不一致等):访问到不属于DolphinDB的内存区域
- 栈溢出(Linux一般默认栈空间大小为8192kb,可使用ulimit -s命令查看)
此时若正确开启了core功能,会生成相应的core文件,就可以使用gdb对core文件进行调试。
查看core文件
当程序在运行过程中异常终止,操作系统会将程序当时的内存状态记录下来,保存在一个文件中,这种行为就叫做core dump(中文有的翻译成“核心转储”)。可认为core dump是“内存快照”,但实际上,除了内存信息之外,还有些关键的程序运行状态也会同时dump下来,例如寄存器信息(包括程序指针、栈指针等)、内存管理信息、其他处理器和操作系统状态和信息。core dump对于编程人员诊断和调试程序是非常有帮助的,因为有些程序的错误(例如指针异常)是很难重现的,而core dump文件可以再现程序出错时的情景。core文件默认生成位置与可执行程序位于同一目录下,文件名为core.***,其中***是一串数字。
core文件设置
控制core文件生成
首先在终端中输入ulimit -c查看是否开启core文件。若结果为0,则表示关闭了此功能,不会生成core文件。结果为数字或者"unlimited",表示开启了core文件。因为core文件比较大,建议设置为"unlimited",表示core文件的大小不受限制。可用下列命令设置:
ulimit -c unlimited以上配置只对当前会话起作用,重新登录时,需要重新配置。以下两种方式可使配置永久生效:
- 在
/etc/profile中增加一行ulimit -S -c unlimited >/dev/null 2>&1后保存退出,重启服务器;或者不重启服务器,使用source /etc/profile使配置马上生效。/etc/profile对所有用户有效,若想只针对某一用户有效,则修改此用户的~/.bashrc或者~/.bash_profile文件。 - 在
/etc/security/limits.conf最后增加如下两行记录:为所有用户开启core dump。

注意: 由于DolphinDB数据节点是通过代理节点进行启动的,在不重启代理节点的情况下,无法使开启core功能生效。因此,开启core功能后需要重启代理节点,再重启数据节点。
修改core文件保存路径
core文件默认的文件名称是core.pid,其中pid是指产生段错误程序的进程号。core文件默认路径是该程序的当前目录。
/proc/sys/kernel/core_uses_pid可控制产生的core文件名中是否添加pid作为扩展。1表示添加,0表示不添加。通过以下命令进行修改:
echo "1" > /proc/sys/kernel/core_uses_pid /proc/sys/kernel/core_pattern可设置core文件保存的位置和文件名,通过以下命令将core文件存放到/corefile目录下,产生的文件名为:core-命令名-pid-时间戳:
echo /corefile/core-%e-%p-%t > /proc/sys/kernel/core_pattern 上述命令参数列表如下:
- %p - insert pid into filename 添加pid
- %u - insert current uid into filename 添加当前uid
- %g - insert current gid into filename 添加当前gid
- %s - insert signal that caused the coredump into the filename 添加导致产生core的信号
- %t - insert UNIX time that the coredump occurred into filename 添加core文件生成时的unix时间
- %h - insert hostname where the coredump happened into filename 添加主机名
- %e - insert coredumping executable name into filename 添加命令名
一般情况下,无需修改参数,按照默认的方式即可。
注意:
设置core文件保存路径时首先要创建这个路径,其次要注意所在磁盘的剩余空间大小,不要影响DolphinDB元数据、分区数据的存储。
通过 /proc/sys/kernel/core_pattern 设置的 core 文件保存路径可能在机器重启后失效,若想使设置永久生效,需要在 /etc/sysctl.conf 文件中添加 kernel.core_pattern=/data/core/core-%e-%p-%t.core。可根据实际环境修改 core 文件路径及名称。
测试core文件是否能够生成
使用下列命令对某进程(用ps查到进程号为24758)使用SIGSEGV信号,可以kill掉这个进程:
kill -s SIGSEGV 24758若在core文件夹下生成了core文件,表示设置有效。
gdb调试core文件
若gdb没有安装,需要先安装。以Centos系统为例,安装gdb用命令如下:
yum install gdbgdb调试命令格式:gdb [exec file] [core file],然后执行bt看堆栈信息:

core文件不生成的情况
Linux中信号是一种异步事件处理的机制,每种信号对应有默认的操作,可以在 这里 查看Linux系统提供的信号以及默认处理。默认操作主要包括忽略该信号(Ingore)、暂停进程(Stop)、终止进程(Terminate)、终止并发生core dump等。如果信号均是采用默认操作,那么,以下几种信号发生时会产生 core dump:
| Signal | Action | Comment |
|---|---|---|
| SIGQUIT | core | Quit from keyboard |
| SIGILL | core | Illegal Instruction |
| SIGABRT | core | Abort signal from abort |
| SIGSEGV | core | Invalid memory reference |
| SIGTRAP | core | Trace/breakpoint trap |
当然,Linux提供的信号不仅限于上面的几种。还有一些信号是无法产生core dump的,比如:
(1) 使用Ctrl+z来挂起一个进程或者Ctrl+C结束一个进程均不会产生core dump,因为前者会向进程发出 SIGTSTP 信号,该信号的默认操作为暂停进程(Stop Process);后者会向进程发出 SIGINT 信号,该信号默认操作为终止进程(Terminate Process)。
(2) kill -9命令会发出 SIGKILL 命令,该命令默认为终止进程,同样不会产生core文件。
(3) 查看dolphindb对应日志,假设日志信息出现“Received signal 15”,如下图,即用SIGTERM(kill命令默认信号)杀死dolphindb进程,不会生成core文件。
以下情况也不会产生core文件:
(a) 进程是设置-用户-ID,而且当前用户并非程序文件的所有者;
(b) 进程是设置-组-ID,而且当前用户并非该程序文件的组所有者;
(c) 用户没有写当前工作目录的许可权;
(d) core文件太大。
避免节点宕机
在企业生产环境下,DolphinDB往往作为流数据中心以及历史数据仓库,为业务人员提供数据查询和计算。当用户较多时,不当的使用容易造成Server端宕机。遵循以下建议,可尽量避免不当使用。
监控磁盘容量,避免磁盘满
当硬盘的可用空间小到一定程度时,就会造成系统的交换文件、临时文件缺乏可用空间,降低系统的运行效率。另外,由于用户平时频繁在硬盘上储存、删除各种软件,使得硬盘的可用空间变得支离破碎,磁盘利用率降低。因此,系统在存储文件时常常没有按照连续的顺序存放,这将导致系统存储和读取文件时频繁移动磁头,极大地降低了系统的运行速度。当硬盘空间不够时,可以对磁盘容量进行监控。下面以Linux为例,步骤如下:
(1) 查看目录的剩余空间大小。
df -h 查看整台服务器的硬盘使用情况
du -lh --max-depth=1 查看当前目录下一级子文件和子目录占用的磁盘容量(2) Linux系统下查找大文件或目录
当硬盘空间不够时,用户就很关心哪些目录或文件比较大,看看能否删掉一些无用文件。以易读的格式显示指定目录或文件的大小,-s选项指定详细显示每个子目录或文件的大小。
du -sh [dirname|filename]
//当前目录的大小:du -sh .
//当前目录下个文件或目录的大小:du -sh *
//显示前10个占用空间最大的文件或目录:
du -s * | sort -nr | head(3)删除对应无用大文件
监控内存使用,避免内存高位运行
内存高位运行容易发生OOM,如何监控和高效使用内存详见 内存管理 中为分布式数据库提供写入缓存小节与流数据消息缓存队列小节
避免多线程并发访问某些内存表
DolphinDB内置编程语言,在操作访问表时有一些规则,如内存表详解并发性小节就说明了有些内存表不能并发写入。若不遵守规则,容易出现server崩溃。下例创建了一个以id字段进行RANGE分区的常规内存表:
t=table(1:0,`id`val,[INT,INT])
db=database("",RANGE,1 101 201 301)
pt=db.createPartitionedTable(t,`pt,`id)下面的代码启动了两个写入任务,并且写入的分区相同,运行后即导致server系统崩溃。
def writeData(mutable t,id,batchSize,n){
for(i in 1..n){
idv=take(id,batchSize)
valv=rand(100,batchSize)
tmp=table(idv,valv)
t.append!(tmp)
}
}
job1=submitJob("write1","",writeData,pt,1..300,1000,1000)
job2=submitJob("write2","",writeData,pt,1..300,1000,1000)产生的core文件如下图:
自定义开发插件俘获异常
DolphinDB支持用户自定义开发插件以扩展系统功能。插件与DolphinDB server在同一个进程中运行。若插件崩溃,整个系统(server)就会崩溃。因此,在开发插件时要注意完善错误检测机制。除了插件函数所在线程可以抛出异常(server在调用插件函数时俘获了异常),其他线程都必须自己俘获异常,不得抛出异常。详情请参阅DolphinDB Plugin。
总结
分布式数据库DolphinDB的设计十分复杂,发生宕机的情况各有不同。若发生节点宕机,请按本文所述一步步排查:
- 排查是否为系统主动退出,如是否通过Web集群管理界面手动关闭节点或调用stopDataNode函数停止节点,是否用kill命令杀死节点进程,是否为license有效期到期退出等。当这些原因导致数据库宕机时,系统运行日志会记录相关的信息,请检查对应时间点是否有相应的操作;
- 排查是否因为内存耗尽而被操作系统杀掉。排查OOM killer可查看操作系统日志;
- 检查一下是否有使用不当的脚本,如多线程并发访问了没有共享的分区表、插件没有俘获一些异常等;
- 请查看core文件,用gdb调试获取堆栈信息。若确定系统有问题,请保存节点日志、操作系统日志和core文件,并及时与DolphinDB工程师联系。