mapr
Use the mapr statement to implement:
-
the MapReduce model of a user-defined aggregate functions (UDAF) in a distributed system
-
the cumulative calculation (particularly in a SQL query with cgroup by clause) of a UDAF
Syntax
mapr udaf(args..){mapF1, mapF2, ..., mapFn -> reduceFunc[; cumF1, cumF2, ...,
cumFn -> runningReduceFunc]}
Arguments
-
udaf(args...)indicates the name and parameter list of the UDAF. -
mapF1, mapF2, ..., mapFnindicates the map functions, which will be applied to all relevant partitions on each data node. -
reduceFuncindicates the reduce function, which accepts the results of the map functions as inputs. -
[; cumF1, cumF2, ..., cumFn -> runningReduceFunc]is optional. It implements the cumulative calculation of the UDAF in a SQL statement with the cgroup by clause.
Cumulative grouping ("cgroup by") is used to calculate cumulative metrics of data grouped by time. Unlike group by, which performs calculation on each group, cgroup by performs cumulative grouping calculations based on the groups encountered so far.
cumF1, cumF2, ..., cumFn correspond to mapF1, mapF2, ...,
mapFn, respectively, and are usually built-in cumulative window
functions, e.g., cumsum. You can also specify the argument as the
function copy, which directly passes the results of a map function
to runningReduceFunc.
runningReduceFunc indicates the function which implements the logic
of the cumulative aggregation.
For the mapr statement to take effect, add the statement and the associated function definitions to the system initialization script (specified by the configuration parameter init, defaults to dolphindb.dos) and reboot the server.
Examples
Define a UDAF to calculate the harmonic mean. The formula is as follows:
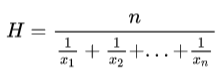
The formula expresses the harmonic mean as the reciprocal of the arithmetic mean of the reciprocals of the given set of observations. With the MapReduce model, we can calculate the arithmetic mean of the data in each partition in parallel during the map phase, then calculates the reciprocal of the weighted sum of all map results in the reduce phase.
// define a udaf
defg harmonicMean(x){
return x.reciprocal().avg().reciprocal()
}
// distributed implementation
// define the map function reciprocalAvg for the arithmetic mean of reciprocals
def reciprocalAvg(x) : reciprocal(x).avg()
// define the reduce function harmonicMeanReduce for the reciprocal of the arithmetic mean of the map function results
defg harmonicMeanReduce(reciprocalAvgs, counts) : wavg(reciprocalAvgs, counts).reciprocal()
// the mapr statement for the MapReduce implementation of harmonicaMean
mapr harmonicMean(x){reciprocalAvg(x), count(x) -> harmonicMeanReduce}Add the script above to the system initialization script and reboot the server. Run the following script on your client:
// define a standard UDAF for comparison against the MapReduce implementation of UDAF
defg harmonicMean_norm(x){
return x.reciprocal().avg().reciprocal()
}
// create a partitioned in-memory table
n = 100000
t = table((2020.09.01 + rand(9, n)).sort!() as date, take(`IBM`MSFT, n) as sym, rand(10.0, n) as value)
db = database("", RANGE, [2020.09.01, 2020.09.03, 2020.09.10])
stock = db.createPartitionedTable(t, "stock", "date").append!(t)
// compare the elapsed time of queries to the table
timer(1000) select harmonicMean_norm(value) as gval from stock group by sym // Time elapsed: 4932.661 ms
timer(1000) select harmonicMean(value) as gval from stock group by sym // Time elapsed: 2490.347 msWe can see that the parallel computing of MapReduce has improved query performance in this example.
Based on the example above, we can adjust the mapr statement for the implementation of cumulative grouping.
// define a cumulative aggregate function harmonicMeanRunning
defg harmonicMeanRunning(reciprocalAvgs, counts) : cumwavg(reciprocalAvgs, counts).reciprocal()
// add the implementation of cumulative grouping of harmonicMean
mapr harmonicMean(x){reciprocalAvg(x), count(x) -> harmonicMeanReduce; copy, copy -> harmonicMeanRunning}Add the script above to the system initialization script and reboot the server. Run the following script on your client (the table "stock" is created in the previous example):
// call harmonicMean in a SQL statement with croup by
select harmonicMean(value) as gval from stock cgroup by date order by date