ridgeBasic
Syntax
ridgeBasic(Y, X, [mode=0], [alpha=1.0], [intercept=true], [normalize=false],
[maxIter=1000], [tolerance=0.0001], [solver='svd'], [swColName])
Details
Perform Ridge regression.
Minimize the following objective function:
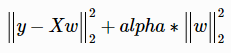
Arguments
Y is a numeric vector indicating the dependent variable.
X is a numeric vector/tuple/matrix/table indicating the independent variable.
-
When X is a vector/tuple, it must be of the same length as Y.
-
When X is a matrix/table, the number of rows must be the same as the length of Y.
modeis an integer indicating the contents in the output. It can be:
-
0 (default): a vector of the coefficient estimates.
-
1: a table with coefficient estimates, standard error, t-statistics, and p-values.
-
2: a dictionary with the following keys: ANOVA, RegressionStat, Coefficient, and Residual.
|
Source of Variance |
DF (degree of freedom) |
SS (sum of square) |
MS (mean of square) |
F (F-score) |
Significance |
|---|---|---|---|---|---|
| Regression | p | sum of squares regression, SSR | regression mean square, MSR=SSR/R | MSR/MSE | p-value |
| Residual | n-p-1 | sum of squares error, SSE | mean square error, MSE=MSE/E | ||
| Total | n-1 | sum of squares total, SST |
|
Item |
Description |
|---|---|
| R2 | R-squared |
| AdjustedR2 | The adjusted R-squared corrected based on the degrees of freedom by comparing the sample size to the number of terms in the regression model. |
| StdError | The residual standard error/deviation corrected based on the degrees of freedom. |
| Observations | The sample size. |
|
Item |
Description |
|---|---|
| factor | Independent variables |
| beta | Estimated regression coefficients |
| StdError | Standard error of the regression coefficients |
| tstat | t statistic, indicating the significance of the regression coefficients |
Residual: the difference between each predicted value and the actual value.
alpha(optional) is a floating number representing the constant that multiplies the L1-norm. The default value is 1.0.
intercept (optional) is a Boolean value indicating whether to include the intercept in the regression. The default value is true.
normalize (optional) is a Boolean value. If true, the regressors will be normalized before regression by subtracting the mean and dividing by the L2-norm. If intercept=false, this parameter will be ignored. The default value is false.
maxIter (optional) is a positive integer indicating the maximum number of iterations. The default value is 1000.
tolerance (optional) is a floating number. The iterations stop when the improvement in the objective function value is smaller than tolerance. The default value is 0.0001.
solver (optional) is a string indicating the solver to use in the computation. It can be either 'svd' or 'cholesky'. It ds is a list of data sources, solver must be 'cholesky'.
swColName (optional) is a STRING indicating a column name of ds. The specified column is used as the sample weight. If it is not specified, the sample weight is treated as 1.