Streaming Subscription
Streaming in DolphinDB is based on the publish-subscribe model. Streaming data is ingested into and published by a stream table. A data node or a third-party application can subscribe to and consume the streaming data through DolphinDB script or API.
Stream Table
Stream table is a special type of in-memory table to store and publish streaming data. Stream table supports concurrent read and write. We can append to stream tables, but cannot delete or modify the records of stream tables.
Steam tables can be created with function streamTable . Since for any publisher there are usually multiple subscribers in different sessions, a stream table must be shared with command share before it can publish streaming data. Stream tables that are not shared cannot publish data.
colName=["Name","Age"]
colType=["string","int"]
t = streamTable(100:10, colName, colType)
share t as st;Publish-Subscribe
For streaming, we need to configure 2 types of nodes: publisher and subscriber. A publisher can simultaneously send data to multiple subscribers; a subscriber can simultaneously receive data from multiple publishers. A node can serve as both a publisher and a subscriber at the same time.
For a publisher, the configuration parameter maxPubConnections must be a positive integer indicating . For a subsriber, parameter subPort must be specified. If there are multiple subsribers, each of them should be configured with a different value for subPort.
Use the following 3 ways to configure the publishers and subscribers.
In the examples below, local8080 is a publisher and local8081 is a subscriber.
(1) Use the Nodes Config in web-based cluster management interface:
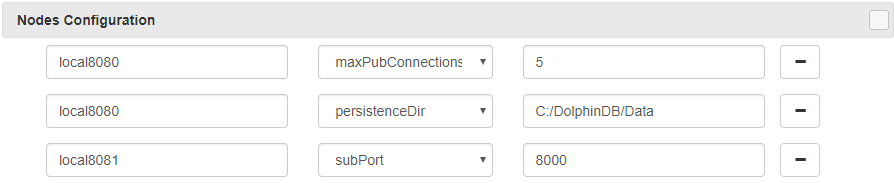
To persist the stream table to disk, we need to specify persistenceDir. After changing the configuration parameters, we need to restart the data nodes.
-
Specify parameter maxPubConnections for the publisher:
dolphindb -home C:/DolphinDB/clusters/inst1 -logFile inst1.log -localSite localhost:8080:local8080 -maxPubConnections 5 -persistenceDir C:/DolphinDB/Data -
Specify parameter subPort for the subscriber:
dolphindb -home C:/DolphinDB/clusters/inst2 -logFile inst2.log -localSite localhost:8081:local8081 -subPort 8000Port 8081 and 8000 are on the same node. The publisher sends the streaming data to port 8000. Port 8081 is reserved for other uses.
(3) In the configuration file cluster.cfg:
local8080.maxPubConnections=5
local8080.persistenceDir=C:/DolphinDB/Data
local8081.subPort=8000Example
For this example, configure a cluster with 2 nodes: DFS_NODE1 and DFS_NODE2. We need to specify maxPubConnections and subPort in cluster.cfg to enable publish/subscribe. For example:
maxPubConnections=32
DFS_NODE1.subPort=9010
DFS_NODE2.subPort=9011
DFS_NODE1.persistenceDir=C:/DolphinDB/DataExecute the following script on DFS_NODE1 for the following tasks:
(1) Create a shared stream table trades_stream with persistence in synchronous mode. At this stage table trades_stream is empty.
n=20000000
colNames = `time`sym`qty`price
colTypes = [TIME,SYMBOL,INT,DOUBLE]
enableTableShareAndPersistence(streamTable(n:0, colNames, colTypes), "trades_stream", false, true, n)
go;(2) Create a distributed table trades. At this stage table trades is empty.
if(existsDatabase("dfs://STREAM_TEST")){
dropDatabase("dfs://STREAM_TEST")
}
dbDate = database("", VALUE, temporalAdd(date(today()),0..30,'d'))
dbSym= database("", RANGE, string('A'..'Z') join "ZZZZ")
db = database("dfs://STREAM_TEST", COMPO, [dbDate, dbSym])
colNames1 = `date`time`sym`qty`price
colTypes1 = [DATE,TIME,SYMBOL,INT,DOUBLE]
trades = db.createPartitionedTable(table(1:0, colNames1, colTypes1), "trades", `date`sym)(3) Create a local subscription to table trades_stream. Create function saveTradesToDFS to save streaming data from trades_stream and today's date to table trades.
def saveTradesToDFS(mutable dfsTrades, msg): dfsTrades.append!(select today() as date,* from msg)
subscribeTable(tableName="trades_stream", actionName="trades", offset=0, handler=saveTradesToDFS{trades}, msgAsTable=true, batchSize=100000, throttle=60);(4) Create another local subscription to table trades_stream. Calculate volume-weighted average price (vwap) with streaming data for each minute and save the result to a shared stream table vwap_stream with persistence in asynchronous mode.
n=1000000
tmpTrades = table(n:0, colNames, colTypes)
lastMinute = [00:00:00.000]
colNames2 = `time`sym`vwap
colTypes2 = [MINUTE,SYMBOL,DOUBLE]
share streamTable(n:0, colNames2, colTypes2) as vwap_stream
enableTablePersistence(vwap_stream, true)
def calcVwap(mutable vwap, mutable tmpTrades, mutable lastMinute, msg){
tmpTrades.append!(msg)
curMinute = time(msg.time.last().minute()*60000l)
t = select wavg(price, qty) as vwap from tmpTrades where time < curMinute, time >= lastMinute[0] group by time.minute(), sym
if(t.size() == 0) return
vwap.append!(t)
t = select * from tmpTrades where time >= curMinute
tmpTrades.clear!()
lastMinute[0] = curMinute
if(t.size() > 0) tmpTrades.append!(t)
}
subscribeTable(tableName="trades_stream", actionName="vwap", offset=0, handler=calcVwap{vwap_stream, tmpTrades, lastMinute}, msgAsTable=true, batchSize=100000, throttle=60);Execute the following script on DFS_NODE2 to create a remote subscription to table trades_stream. This subscription saves streaming data to a shared stream table trades_stream_slave with persistence in asynchronous mode.
n=20000000
colNames = `time`sym`qty`price
colTypes = [TIME,SYMBOL,INT,DOUBLE]
share streamTable(n:0, colNames, colTypes) as trades_stream_slave
enableTablePersistence(table=trades_stream_slave, cacheSize=n)
go;
subscribeTable(server="DFS_NODE1", tableName="trades_stream", actionName="slave", offset=0, handler=trades_stream_slave);Execute the following script on DFS_NODE1 to simulate the streaming data for 3 stocks and 10 minutes. Generate 2,000,000 records for each stock in each minute. Data in each minute are inserted into the stream table trades_stream in 600 blocks, with a 100 millisecond interval between blocks.
n=10
ticks = 2000000
rows = ticks*3
startMinute = 09:30:00.000
blocks=600
for(x in 0:n){
time = startMinute + x*60000 + rand(60000, rows)
indices = isort(time)
time = time[indices]
sym = array(SYMBOL,0,rows).append!(take(`IBM,ticks)).append!(take(`MSFT,ticks)).append!(take(`GOOG,ticks))[indices]
price = array(DOUBLE,0,rows).append!(norm(153,1,ticks)).append!(norm(91,1,ticks)).append!(norm(1106,20,ticks))[indices]
indices = NULL
blockSize = rows / blocks
for(y in 0:blocks){
range =pair(y * blockSize, (y+1)* blockSize)
insert into trades_stream values(subarray(time,range), subarray(sym,range), 10+ rand(100, blockSize), subarray(price,range))
sleep(100)
}
blockSize = rows % blocks
if(blockSize > 0){
range =pair(rows - blockSize, rows)
insert into trades_stream values(subarray(time,range), subarray(sym,range), 10+ rand(100, blockSize), subarray(price,range))
}
}To check the results, run the following script on DFS_NODE1:
trades=loadTable("dfs://STREAM_TEST", `trades)
select count(*) from tradesWe expect to see a result of 60,000,000.
select * from vwap_streamWe expect the table vwap_stream has 27 rows.
Run the following script on DFS_NODE2:
select count(*) from trades_stream_slaveWe expect to see a result of less than 60,000,000 as part of the table has been persisted to disk.
Streaming Data Persistence
By default, the stream table keeps all streaming data in memory. Streaming data can be persisted to disk for the following 3 reasons:
-
Mitigate out-of-memory problems.
-
Backup streaming data. When a node reboots, the persisted data can be automatically loaded into the stream table.
-
Resubscribe from any position.
To persist a stream table, we first need to specify parameter persistenceDir for the publisher node, then execute command enableTableShareAndPersistence .
Syntax:
enableTableShareAndPersistence(table, tableName, [asynWrite=true], [compress=true], [cacheSize=-1], [retentionMinutes=1440], [flushMode=0])
-
asynWrite indicates whether table persistence is in asynchronous mode. Asynchronous mode increases throughput but may incur data loss in case of node crash or power outage. If the application requires data consistency in streaming, the synchronous mode is preferred. This way streaming data won't enter the publishing queue until it has been persisted to disk.
-
compress indicates whether the table is saved to disk in compression mode.
-
cacheSize indicates the maximum number of rows of the stream table to keep in memory.
-
retentionMinutes indicates for how long the log file keeps the records.
-
If flushMode=0, newly appended messages are flushed to OS page buffer. A power outage may result in data loss. If flushMode=1, newly appended messages are flushed to disk immediately.
Related functions:
-
getPersistenceMeta returns metadata of a shared stream table that has been enabled to be persisted to disk.
-
clearTablePersistence stops persistence of a stream table and then deletes the content of the table on disk.
-
disableTablePersistence stops persistence of a stream table.
Automatic Reconnection
To enable automatic reconnection after network disruption, the stream table must be persisted on the publisher. When parameter 'reconnect' of function subscribeTable is set to true, the subscriber will record the offset of the streaming data. When the network connection is interrupted, the subscriber will automatically re-subscribe from the offset. If the subscriber crashes or the stream table is not persisted on the publisher, the subscriber cannot automatically reconnect.
Filtering of Streaming Data
Streaming data can be filtered at the publisher to significantly reduce network traffic. Use command setStreamTableFilterColumn on the stream table to specify the filtering column, then specify a vector for parameter filter in function subscribeTable. Only the rows with filtering column values in vector filter are published to the subscriber. As of now a stream table can have only one filtering column. In the following example, the stream table 'trades' on the publisher only publishes data for IBM and GOOG to the subscriber:
share streamTable(10000:0,`time`symbol`price, [TIMESTAMP,SYMBOL,INT]) as trades
setStreamTableFilterColumn(trades, `symbol)
trades_slave=table(10000:0,`time`symbol`price, [TIMESTAMP,SYMBOL,INT])
filter=symbol(`IBM`GOOG)
subscribeTable(tableName=`trades, actionName=`trades_slave, handler=append!{trades_slave}, msgAsTable=true, filter=filter);Unsubscribe
Each subscription is uniquely identified with a subscription topic. If a new subscription has the same topic as an existing subscription, the new subscription cannot be established. To make a new subscription with the same subscription topic as an existing subscription, we need to cancel the existing subscription with command unsubscribeTable .
unsubscribeTable(tableName="trades_stream", actionName="trades");